
面试准备(框架部分)
面试准备(框架部分)
Glide
先上其他大牛的博客链接
面试官:简历上最好不要写Glide,不是问源码那么简单 - 掘金 (juejin.cn)
Android | 《看完不忘系列》之Glide - 掘金 (juejin.cn)
基础流程
开始自己的记录
需要明确的是看其他人的图片加载框架其实就是为了学习如果自己要搭建一个图片加载框架需要做的各个方面的工作
首先看最简单的用法
1 | Glide.with(this).load(url).into(imageView); |
最简单的用法可以看作主干,其实就是三部曲
更进阶一点的用法这里贴出来,当然还有更多
1 | //扩展功能 |
下面先看三部曲部分
- with
with方法最后得到的一个对象是一个RequestManager对象,这个对象是用来管理和启动图片请求的对象。
with传入上下文context决定了图片请求的生命周期
如果传入Application对象,那么拿到的就是应用级别的RequestManager对象,Application级别的RequestManager对象是一个全局单例,(并且需要注意到的是,如果在子线程中使用Glide,无论传入的Context对象是什么级别的,最终拿到的也是这个Application级别的RequestManager对象),这里是通过RequestManagerRetriever去获取全局的RequestManager单例的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class RequestManagerRetriever implements Handler.Callback {
volatile RequestManager applicationManager;
RequestManager getApplicationManager(Context context) {
//双重检查锁,获取单例的RequestManager
if (applicationManager == null) {
synchronized (this) {
if (applicationManager == null) {
Glide glide = Glide.get(context.getApplicationContext());
applicationManager = factory.build(glide,new ApplicationLifecycle(),
new EmptyRequestManagerTreeNode(),context.getApplicationContext());
}
}
}
//返回应用级别的RequestManager单例
return applicationManager;
}
}如果传入Activity对象,那么拿到的是页面级别的RequestManager对象,这时候Glide会通过tag在map中寻找当前的Activity是否创建过SupportRequestManagerFragment,如果创建过就直接返回这个对象的RequestManager对象,如果没有创建过SupportRequestManagerFragment,那么就会创建一个,并且通过
fm.beginTransaction().add(current, FRAGMENT_TAG).commitAllowingStateLoss();将Fragment添加到Activity来感知Activity的生命周期变化(其中fm是FragmentManager),并返回新建的SupportRequestManagerFragment对象的RequestManager对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class RequestManagerRetriever implements Handler.Callback {
RequestManager supportFragmentGet(Context context,FragmentManager fm,
Fragment parentHint,boolean isParentVisible) {
//获取空fragment,无则创建
SupportRequestManagerFragment current =
getSupportRequestManagerFragment(fm, parentHint, isParentVisible);
RequestManager requestManager = current.getRequestManager();
if (requestManager == null) {
Glide glide = Glide.get(context);
//如果空fragment没有RequestManager,就创建一个
requestManager = factory.build(glide, current.getGlideLifecycle(),
current.getRequestManagerTreeNode(), context);
//让空fragment持有RequestManager
current.setRequestManager(requestManager);
}
//返回页面级别的RequestManager
return requestManager;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class RequestManagerRetriever implements Handler.Callback {
Map<FragmentManager, SupportRequestManagerFragment> pendingSupportRequestManagerFragments =
new HashMap<>();
SupportRequestManagerFragment getSupportRequestManagerFragment(
final FragmentManager fm, Fragment parentHint, boolean isParentVisible) {
//通过tag找到Activity中的空fragment
SupportRequestManagerFragment current =
(SupportRequestManagerFragment) fm.findFragmentByTag(FRAGMENT_TAG);
if (current == null) {
//findFragmentByTag没找到空fragment,有可能是延迟问题?再从Map中找一下
current = pendingSupportRequestManagerFragments.get(fm);
if (current == null) {
//确实没有空fragment,就创建一个
current = new SupportRequestManagerFragment();
//...
//缓存进Map
pendingSupportRequestManagerFragments.put(fm, current);
//空fragment添加到Activity,使其能感知Activity的生命周期
fm.beginTransaction().add(current, FRAGMENT_TAG).commitAllowingStateLoss();
//...
}
}
return current;
}
}
- **load**
load方法最后得到的是一个RequestBuilder对象,也就是图片请求构建器,with得到的RequestManager可以构建RequestBuilder对象
```java
class RequestManager
implements ComponentCallbacks2, LifecycleListener, ModelTypes<RequestBuilder<Drawable>> {
//入口
RequestBuilder<Drawable> load(String string) {
return asDrawable().load(string);
}
//1
RequestBuilder<Drawable> asDrawable() {
//需要加载的类型为Drawable
return as(Drawable.class);
}
//2,走到这里开始构建RequestBuilder,之后回到入口走了RequestBuilder的load(String)方法,接下来看这个方法
<ResourceType> RequestBuilder<ResourceType> as(Class<ResourceType> resourceClass) {
//创建一个请求构建器
return new RequestBuilder<>(glide, this, resourceClass, context);
}
}
1 | class RequestBuilder<TranscodeType> extends BaseRequestOptions<RequestBuilder<TranscodeType>> |
- into
这里其实就是构建Target包装对象,构建Request发起请求,并且走三级缓存获取图像,网络请求由EnginJob发起,DecodeJob为具体请求,HttpUrlFecth最后执行并获取数据,最后SingleRuest回调到Target,Target加载图片到ImageView
- 先要开始图片请求
一开始是先根据传入的ImageView的参数设置一些请求参数,之后返回的是重载的into方法
1 | class RequestBuilder<TranscodeType> extends BaseRequestOptions<RequestBuilder<TranscodeType>> |
在重载into方法中,就是要构建具体的Request请求了,就是先判断Target载体是否已经有请求,如果之前的请求正在允许就先启动异步请求,如果不存在就为Target绑定图片请求,之后通过前面获取到的RequestManager启动Request请求。
1 | class RequestBuilder<TranscodeType> extends BaseRequestOptions<RequestBuilder<TranscodeType>> |
requestManager.track(target, request);是开启图片请求用的,下面是具体的启动过程
1 | //RequestManager.java |
2.
之后需要关注的就是request.begin()方法了,这个方法里面其实就是先看是否明确了图片的尺寸,不然先去明确尺寸,最后都走到了onSizeReady
在onSizeReady中就通过 engine.load()(这里传了很多参数给load方法)
1 | class Engine implements EngineJobListener,MemoryCache.ResourceRemovedListener, |
最后如果内存中没有就要走到waitForExistingOrStartNewJob,最后是engineJob.start(decodeJob);,这里的EngineJob是负责最后的网络请求的,这里调用链是
1 | DecodeJob.run -> DecodeJob.runWrapped -> DecodeJob.runGenerators -> |
最后走到了HttpUrlFetcher.loadData,最后通过 callback.onDataReady(result);回调出去
1 | class HttpUrlFetcher implements DataFetcher<InputStream> { |
这里的callback是SingleRequest,当然result还需要做各种解码等等工作,最后看到SingleRequest,这里面最后走到了 target.onResourceReady(result, animation);
1 | class SingleRequest<R> implements Request, SizeReadyCallback, ResourceCallback { |
最后的 target.onResourceReady(result, animation);走到DrawableImageViewTarget,就是将图片设置出去
1 | class DrawableImageViewTarget extends ImageViewTarget<Drawable> { |
最后into的两个阶段的解析图就是如下
三级缓存细节
这里所说的三级缓存是内存缓存、硬盘缓存、网络
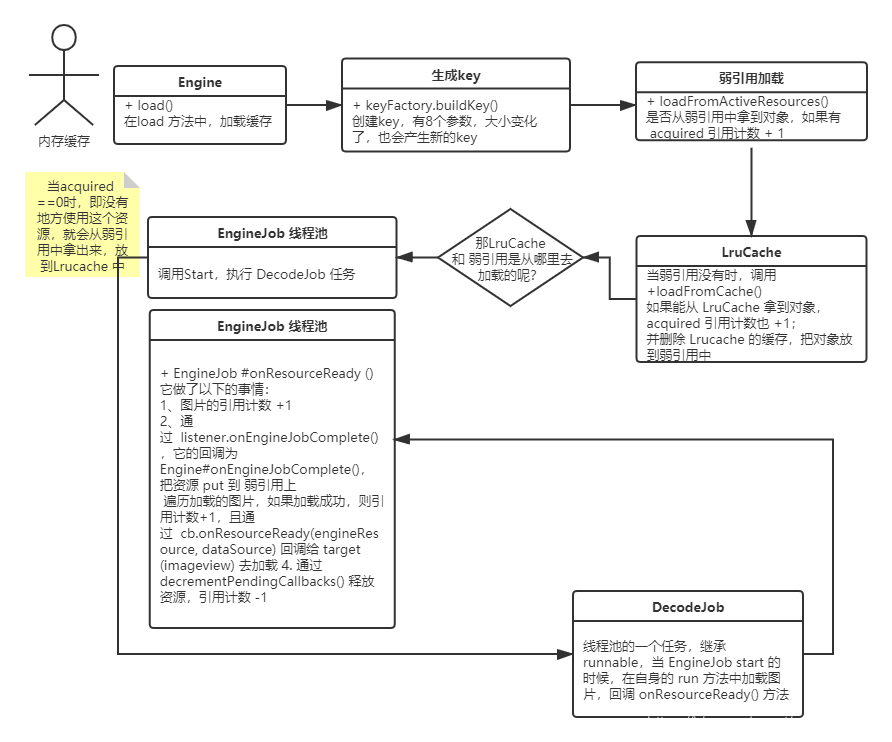
EngineResource的acquired变量记录使用的位置的数量,调用acquire()方法会让变量+1,调用release()方法会让变量-1
内存缓存
弱引用
弱引用是由一个HashMap维护,key是缓存的key(这个key由图片url、width、heigjt等10来个参数组成)value是图片资源对象的弱引用类型
Map<Key, ResourceWeakReference> activeEngineResources = new HashMap<>();提高效率)弱引用使用的是HashMap,而LruCache采用的是LinkedHashMap,从访问效率而言,肯定是HashMap更高;(分压策略)减少LruCache中的trimToSize的概率,同一张图片不会同时出现在弱引用和LruCache中,正在引用的放到弱引用中,减少了LruCache中存放的数量
LruCache
Glide使用的内存缓存
LruCache,不过并不是Android SDK中的**LruCache**,不过内部也是基于LinkHashMap(LinkedHashMap 源码分析 | JavaGuide)可以先了解LinkHashMap,之后再了解Glide的LruCache的算法设计,这里的算法设计是最近最少使用算法,也就是需要移除的时候将最老的数据移除(达到缓存大小回收)
其中LinkHashMap的Entry也就是表对象如下,就是继承了HashMap,本质也是数组+链表的组合,就是重写了
createEntry方法,创建的Entry变成了如下的结构,也就是所有的节点都能连在一起,是一个双向链表的形式,结构可以看下面的图1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private static class LinkedHashMapEntry<K,V> extends HashMapEntry<K,V> {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry<K,V> before, after; //双向链表
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}那么链表头节点header的before是最新访问的数据,header的after则是最旧的数据。这样在回收的时候就回收header的after即可,调用remove方法改变指针即可,要添加图片就在before前面添加即可,调用addBofore方法添加
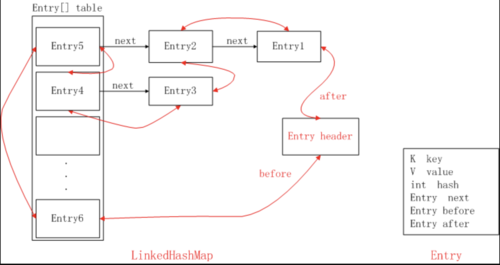
1
2
3
4
5
6
7
8
9
10
11private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
private void remove() {
before.after = after;
after.before = before;
}LruCache有个trimToSize方法用来移除最老的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
//大小没有超出,不处理
if (size <= maxSize) {
break;
}
//超出大小,移除最老的数据
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
//这个大小的计算,safeSizeOf 默认返回1;
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
磁盘缓存
DiskLruCache跟LruCache的思路差不多,一样是设置一个总大小,每次往磁盘写文件,总大小超过阈值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// DiskLruCache 内部也是用LinkedHashMap
private final LinkedHashMap<String, Entry> lruEntries =
new LinkedHashMap<String, Entry>(0, 0.75f, true);
...
public synchronized boolean remove(String key) throws IOException {
checkNotClosed();
validateKey(key);
Entry entry = lruEntries.get(key);
if (entry == null || entry.currentEditor != null) {
return false;
}
//一个key可能对应多个value,hash冲突的情况
for (int i = 0; i < valueCount; i++) {
File file = entry.getCleanFile(i);
//通过 file.delete() 删除缓存文件,删除失败则抛异常
if (file.exists() && !file.delete()) {
throw new IOException("failed to delete " + file);
}
size -= entry.lengths[i];
entry.lengths[i] = 0;
}
...
return true;
}可以看到 DiskLruCache 同样是利用LinkHashMap的特点,只不过数组里面存的 Entry 有点变化,Editor 用于操作文件。
1
2
3
4
5
6
7
8
9
10
11
12private final class Entry {
private final String key;
private final long[] lengths;
private boolean readable;
private Editor currentEditor;
private long sequenceNumber;
...
}网络部分
线程池细节
避免OOM和内存移除细节
软引用
强引用: 普通变量都属于强引用,比如 private Context context;
软应用: SoftReference,在发生OOM之前,垃圾回收器会回收SoftReference引用的对象。
弱引用: WeakReference,发生GC的时候,垃圾回收器会回收WeakReference中的对象。
虚引用: 随时会被回收,没有使用场景。(强引用对象的回收时机依赖垃圾回收算法,我们常说的可达性分析算法,当Activity销毁的时候,Activity会跟GCRoot断开,至于GCRoot是谁?这里可以大胆猜想,Activity对象的创建是在ActivityThread中,ActivityThread要回调Activity的各个生命周期,肯定是持有Activity引用的,那么这个GCRoot可以认为就是ActivityThread,当Activity 执行onDestroy的时候,ActivityThread 就会断开跟这个Activity的联系,Activity到GCRoot不可达,所以会被垃圾回收器标记为可回收对象。)
存不足时软引用中的Bitmap被回收的时候,这个LruCache就形同虚设,相当于内存缓存失效了,必然出现效率问题
onLowMemory
当内存不足的时候,Activity、Fragment会调用onLowMemory方法,可以在这个方法里去清除缓存,Glide使用的就是这一种方式来防止OOM。
1
2
3
4
5
6
7
8
9
10
11
12
13//Glide
public void onLowMemory() {
clearMemory();
}
public void clearMemory() {
// Engine asserts this anyway when removing resources, fail faster and consistently
Util.assertMainThread();
// memory cache needs to be cleared before bitmap pool to clear re-pooled Bitmaps too. See #687.
memoryCache.clearMemory();
bitmapPool.clearMemory();
arrayPool.clearMemory();
}从Bitmap 像素存储位置考虑
占用内存由像素大小和宽高影响
Bitmap不同的格式,一个像素占用的大小不一样,如果Bitmap使用 RGB_565 格式,则1像素占用 2 byte,ARGB_8888 格式则占4 byte。
在选择图片加载框架的时候,可以将内存占用这一方面考虑进去,更少的内存占用意味着发生OOM的概率越低。 Glide内存开销是Picasso的一半,就是因为默认Bitmap格式不同。(Glide默认的bitmap格式为RGB_565,Picasso默认的bitmap格式为ARGB_8888)至于宽高,是指Bitmap的宽高,如果 BitmapFactory.Options 中指定 inJustDecodeBounds 为true,则为原图宽高,如果是false,则是缩放后的宽高。所以我们一般可以通过压缩来减小Bitmap像素占用内存。
8.0 的Bitmap创建就两个点:
- 创建native层Bitmap,在native堆申请内存。
- 通过JNI创建java层Bitmap对象,这个对象在java堆中分配内存。
7.0 像素内存的分配是这样的:
通过JNI调用java层创建一个数组
然后创建native层Bitmap,把数组的地址传进去。
由此说明,7.0 的Bitmap像素数据是放在java堆的。当然,3.0 以下Bitmap像素内存据说也是放在native堆的,但是需要手动释放native层的Bitmap,也就是需要手动调用recycle方法,native层内存才会被回收。这个大家可以自己去看源码验证。
native层Bitmap 回收问题
Java层的Bitmap对象由垃圾回收器自动回收,而native层Bitmap印象中我们是不需要手动回收的,源码中如何处理的呢?记得有个面试题是这样的:
说说final、finally、finalize 的关系
三者除了长得像,其实没有半毛钱关系,final、finally大家都用的比较多,而 finalize 用的少,或者没用过,finalize 是 Object 类的一个方法,垃圾回收器确认这个对象没有其它地方引用到它的时候,会调用这个对象的finalize方法,子类可以重写这个方法,做一些释放资源的操作。
在6.0以前,Bitmap 就是通过这个finalize 方法来释放native层对象的。
内存泄露问题
Glide在with中传入的是具有生命周期的作用域(非Application作用域),尽量避免使用Application作用域,因为Application作用域不会对页面绑定生命周期机制,就会回收不及时释放操作等,也别持有ImageView等等,最简单将ImageView用WeakReference修饰就完事了,但不完美,最完美就是上面Glide的生命周期方案了。
一些对比
Glide和Picasso
with参数

图片质量不同
Glide默认的bitmap格式为RGB_565
Picasso默认的bitmap格式为ARGB_8888
加载Gif图不同
Glide的一个明显的优点就是它可以加载gif图片,用Picasso加载的gif图片是不会动的
因为Glide被设计成能和Activity/Fragment的生命周期完美的相结合,因此gif动画将随着Activity/Fragment的生命周期自动的开始和停止。
gif的缓存和一般的图片也是一样的,也是第一次加载的时候调整大小,然后缓存。
缓存策略和加载速度
Picasso的缓存是全尺寸的,而Glide的缓存根据ImageView的尺寸相同
将ImageView调整成不同的大小,不管大小如何,Picasso值缓存一个全尺寸的,Picasso则需要在显示前重新调整大小而导致一下延迟.
而Glide不同,它会为每种大小尺寸缓存一下,加载速度比Picasso更快,磁盘策略比Picasso更好,但需要更大的空间来缓存,Glide比Picasso更有利于减少OOM的发生
**Glide和Fresco **
Fresco 之所以能跟Glide 正面交锋,必然有其独特之处,文中开头列出 Fresco 的优点是:“在5.0以下(最低2.3)系统,Fresco将图片放到一个特别的内存区域(Ashmem区)” 这个Ashmem区是一块匿名共享内存,Fresco 将Bitmap像素放到共享内存去了,共享内存是属于native堆内存。
Fresco 关键源码在 PlatformDecoderFactory 这个类
1 | public class PlatformDecoderFactory { |
8.0 先不看了,看一下 4.4 以下是怎么得到Bitmap的,看下GingerbreadPurgeableDecoder这个类有个获取Bitmap的方法
1 | //GingerbreadPurgeableDecoder |
捋一捋,4.4以下,Fresco 使用匿名共享内存来保存Bitmap数据,首先将图片数据拷贝到匿名共享内存中,然后使用Fresco自己写的加载Bitmap的方法。
Fresco对不同Android版本使用不同的方式去加载Bitmap,至于4.4-5.0,5.0-8.0,8.0 以上,对应另外三个解码器,大家可以从PlatformDecoderFactory 这个类入手,自己去分析,思考为什么不同平台要分这么多个解码器,8.0 以下都用匿名共享内存不好吗?期待你在评论区跟大家分享~
OkHttp
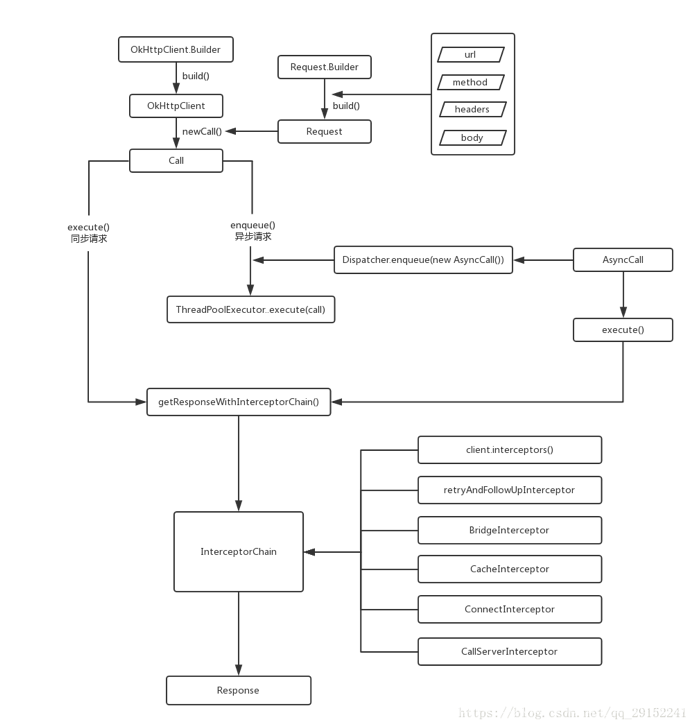
使用和工作原理
首先是OkHttpClient
(官方建议使用单例创建OkHttpClient,即一个进程中只创建一次即可,以后的每次交易都使用该实例发送交易。这是因为OkHttpClient拥有自己的连接池和线程池,这些连接池和线程池可以重复使用,这样做利于减少延迟和节省内存。)
1
2
3
4
5
6
7
8//OkHttpClient的构造采用了建造者模式
mOkHttpClient = new OkHttpClient.Builder()
.addInterceptor(loggingInterceptor)
.retryOnConnectionFailure(true)
.connectTimeout(TIME_OUT, TimeUnit.SECONDS)
.readTimeout(TIME_OUT, TimeUnit.SECONDS)
.build();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37final Dispatcher dispatcher;//调度器
final
Proxy proxy;//代理
final List<Protocol> protocols;//协议
final List<ConnectionSpec> connectionSpecs;//传输层版本和连接协议
final List<Interceptor> interceptors;//拦截器
final List<Interceptor> networkInterceptors;//网络拦截器
final EventListener.Factory eventListenerFactory;
final ProxySelector proxySelector;//代理选择器
final CookieJar cookieJar;//cookie
final
Cache cache;//cache 缓存
final
InternalCache internalCache;//内部缓存
final SocketFactory socketFactory;//socket 工厂
final
SSLSocketFactory sslSocketFactory;//安全套层socket工厂 用于https
final
CertificateChainCleaner certificateChainCleaner;//验证确认响应书,适用HTTPS 请求连接的主机名
final HostnameVerifier hostnameVerifier;//主机名字确认
final CertificatePinner certificatePinner;//证书链
final Authenticator proxyAuthenticator;//代理身份验证
final Authenticator authenticator;//本地省份验证
final ConnectionPool connectionPool;//链接池 复用连接
final Dns dns; //域名
final boolean followSslRedirects;//安全套接层重定向
final boolean followRedirects;//本地重定向
final boolean retryOnConnectionFailure;//重试连接失败
final int connectTimeout;//连接超时
final int readTimeout;//读取超时
final int writeTimeout;//写入超时其次是Request
1
2
3
4
5
6
7
8
9String run(String url) throws IOException {
//Request中包含客户请求的参数:url、method、headers、requestBody和tag,也采用了建造者模式。
Request request = new Request.Builder()
.url(url)
.build();
Response response = client.newCall(request).execute();
return response.body().string();
}Call其实是RealCall,其中主要方法是①同步请求:client.newCall(request).execute;②异步请求:client.newCall(request).enqueue(常用)
1
2
3
4
5
6
7
8interface Factory {
Call newCall(Request request);
}
...
public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14RealCall.java
public void enqueue(Callback responseCallback) {
//TODO 不能重复执行
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
//TODO 交给 dispatcher调度器 进行调度
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
/*这里synchronized (this) 确保每个call只能被执行一次不能重复执行,之后Dispatcher 调度器 将 Call 加入队列,并通过线程池执行 Call,在上面的OkHttpClient就已经初始化了Dispatcher*/下面就是Dispatcher了,具体结构原理在后面享学课堂部分写到了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//Dispatcher的属性和方法
//TODO 同时能进行的最大请求数
private int maxRequests = 64;
//TODO 同时请求的相同HOST的最大个数 SCHEME :// HOST [ ":" PORT ] [ PATH [ "?" QUERY ]]
//TODO 如 https://restapi.amap.com restapi.amap.com - host
private int maxRequestsPerHost = 5;
/**
* Ready async calls in the order they'll be run.
* TODO 双端队列,支持首尾两端 双向开口可进可出,方便移除
* 异步等待队列
*
*/
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
/**
* Running asynchronous calls. Includes canceled calls that haven't finished yet.
* TODO 正在进行的异步队列
*/
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//TODO 执行异步请求
synchronized void enqueue(AsyncCall call) {
//TODO 同时请求不能超过并发数(64,可配置调度器调整)
//TODO okhttp会使用共享主机即 地址相同的会共享socket
//TODO 同一个host最多允许5条线程通知执行请求
if (runningAsyncCalls.size() < maxRequests &&
runningCallsForHost(call) < maxRequestsPerHost) {
//TODO 加入运行队列 并交给线程池执行
runningAsyncCalls.add(call);
//TODO AsyncCall 是一个runnable,放到线程池中去执行,查看其execute实现
executorService().execute(call);
} else {
//TODO 加入等候队列
readyAsyncCalls.add(call);
}
}
/*可见Dispatcher将Call加入队列中(若同时请求数未超过最大值,则加入运行队列,放到线程池中执行;否则加入等待队列),然后通过线程池执行call。*/executorService() 本质上是一个线程池执行方法,用于创建一个线程池
1
2
3
4
5
6
7
8
9
10
11public synchronized ExecutorService executorService() {
if (executorService == null) {
//TODO 线程池的相关概念 需要理解
//TODO 核心线程 最大线程 非核心线程闲置60秒回收 任务队列
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher",
false));
}
/*使用的是SynchronousQueue作为运行队列,有请求进来就创建线程去执行,这才满足网络请求的要求,高并发并按顺序进行请求*/
return executorService;
}加入线程池中的Call实际是AsyncCall,继承自NamedRunnable类,而NamedRunnable实现Runnable接口,线程池中执行execute()其实就是执行AsyncCall的execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29final class AsyncCall extends NamedRunnable {
protected void execute() {
boolean signalledCallback = false;
try {
//TODO 责任链模式
//TODO 拦截器链 执行请求
Response response = getResponseWithInterceptorChain();
//回调结果
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
//TODO 移除队列
client.dispatcher().finished(this);
}
}
}下面就是拦截器的部分了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35//TODO 核心代码 开始真正的执行网络请求
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
//TODO 责任链
List<Interceptor> interceptors = new ArrayList<>();
//TODO 在配置okhttpClient 时设置的intercept 由用户自己设置
interceptors.addAll(client.interceptors());
//TODO 负责处理失败后的重试与重定向
interceptors.add(retryAndFollowUpInterceptor);
//TODO 负责把用户构造的请求转换为发送到服务器的请求 、把服务器返回的响应转换为用户友好的响应 处理 配置请求头等信息
//TODO 从应用程序代码到网络代码的桥梁。首先,它根据用户请求构建网络请求。然后它继续呼叫网络。最后,它根据网络响应构建用户响应。
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//TODO 处理 缓存配置 根据条件(存在响应缓存并被设置为不变的或者响应在有效期内)返回缓存响应
//TODO 设置请求头(If-None-Match、If-Modified-Since等) 服务器可能返回304(未修改)
//TODO 可配置用户自己设置的缓存拦截器
interceptors.add(new CacheInterceptor(client.internalCache()));
//TODO 连接服务器 负责和服务器建立连接 这里才是真正的请求网络
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//TODO 配置okhttpClient 时设置的networkInterceptors
//TODO 返回观察单个网络请求和响应的不可变拦截器列表。
interceptors.addAll(client.networkInterceptors());
}
//TODO 执行流操作(写出请求体、获得响应数据) 负责向服务器发送请求数据、从服务器读取响应数据
//TODO 进行http请求报文的封装与请求报文的解析
interceptors.add(new CallServerInterceptor(forWebSocket));
//TODO 创建责任链
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//TODO 执行责任链
return chain.proceed(originalRequest);
}后面是根据责任链的设计模式,按照责任链去递归执行拦截器,当责任链执行完毕,如果拦截器想要拿到最终的数据做其他的逻辑处理等,这样就不用在做其他的调用方法逻辑了,直接在当前的拦截器就可以拿到最终的数据。这也是okhttp设计的最优雅最核心的功能。周执行调度器完成方法,移除队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
//TODO calls 移除队列
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
//TODO 检查是否为异步请求,检查等候的队列 readyAsyncCalls,如果存在等候队列,则将等候队列加入执行队列
if (promoteCalls) promoteCalls();
//TODO 运行队列的数量
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
//闲置调用
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
private void promoteCalls() {
//TODO 检查 运行队列 与 等待队列
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
//TODO 将等待队列加入到运行队列中
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
//TODO 相同host的请求没有达到最大,加入运行队列
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//TODO 同步执行请求 直接返回一个请求的结果
/*同步请求就直接交给调度器将Call加入执行队列,然后通过拦截器链通过责任链模式真正进行网络请求,之后完成后移除队列*/
public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
//TODO 调用监听的开始方法
eventListener.callStart(this);
try {
//TODO 交给调度器去执行
client.dispatcher().executed(this);
//TODO 获取请求的返回数据
Response result = getResponseWithInterceptorChain();//这里就是责任链的开始部分
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
//TODO 执行调度器的完成方法 移除队列
client.dispatcher().finished(this);
}
}
总结
①OkhttpClient 实现了Call.Fctory,负责为Request 创建 Call;
②RealCall 为Call的具体实现,其enqueue() 异步请求接口通过Dispatcher()调度器利用ExcutorService实现,而最终进行网络请求时和同步的execute()接口一致,都是通过 getResponseWithInterceptorChain() 函数实现
③getResponseWithInterceptorChain() 中利用 Interceptor 链条,责任链模式 分层实现缓存、透明压缩、网络 IO 等功能;最终将响应数据返回给用户。
设计模式
建造者模式
创建者模式又叫建造者模式,是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。创建者模式隐藏了复杂对象的创建过程,它把复杂对象的创建过程加以抽象,通过子类继承或者重载的方式,动态的创建具有复合属性的对象。OkHttp中HttpClient、Request构造便是通过建造者模式
简单工厂模式
okhttp 实现了Call.Factory接口
1
2
3
4
5
6
7
8
9interface Factory {
Call newCall(Request request);
}
//实现Call接口
public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}责任链模式
责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。看完只能说设计真的精妙
1
2
3
4
5
6
7
8
9
10public interface Interceptor {
String interceptor(Chain chain);
interface Chain {
String request();
String proceed(String request);
}
}
1
2
3
4
5
6
7
8
9public class BridgeInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 BridgeInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 BridgeInterceptor 拦截器之后代码 得到最终数据:"+proceed);
return proceed;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class RetryAndFollowInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 RetryAndFollowInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:" + proceed);
return proceed;
}
}
public class CacheInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 CacheInterceptor 最后一个拦截器 返回最终数据");
return "success";
}
}
public class RealInterceptorChain implements Interceptor.Chain {
private List<Interceptor> interceptors;
private int index;
private String request;
public RealInterceptorChain(List<Interceptor> interceptors, int index, String request) {
this.interceptors = interceptors;
this.index = index;
this.request = request;
}
public String request() {
return request;
}
public String proceed(String request) {
if (index >= interceptors.size()) return null;
//获取下一个责任链
RealInterceptorChain next = new RealInterceptorChain(interceptors, index+1, request);
// 执行当前的拦截器
Interceptor interceptor = interceptors.get(index);
return interceptor.interceptor(next);
}
}
//测试和结果
List<Interceptor> interceptors = new ArrayList<>();
interceptors.add(new BridgeInterceptor());
interceptors.add(new RetryAndFollowInterceptor());
interceptors.add(new CacheInterceptor());
RealInterceptorChain request = new RealInterceptorChain(interceptors, 0, "request");
request.proceed("request");
//打印出的log
/*执行 BridgeInterceptor 拦截器之前代码
执行 RetryAndFollowInterceptor 拦截器之前代码
执行 CacheInterceptor 最后一个拦截器 返回最终数据
执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:success
执行 BridgeInterceptor 拦截器之后代码 得到最终数据:success
*/
源码解读
ConnectionPool连接池
管理HTTP和SPDY连接的重用,减少网络延迟。连接池是将已经创建好的连接保存在一个缓冲池中,当有请求来时,直接使用已经创建好的连接。
在okhttp中,客户端与服务端的连接被抽象为一个个的Connection,实现类是RealConnection。而ConnectionPool就是专门用来管理Connection的类。ConnectionPool用来管理connections的复用,以减少网络的延迟。一些共享一个地址(Address)的HTTP requests可能也会共享一个Connection。ConnectionPool设置这样的策略:让一些connections保持打开状态,以备将来使用。
OKHttp开源框架学习十:ConnectionPool连接池_okhttp connectionpool-CSDN博客
Route路由:对地址Adress的一个封装类
RouteSelector路由选择器:在OKhttp中其实其作用也就是返回一个可用的Route对象
Platform平台:用于针对不同平台适应性
Call请求(Request\Response):代表实际的http请求,它是连接Request和response的桥梁。由于重写,重定向,跟进和重试,你简单的请求Call可能产生多个请求Request和响应Response。OkHttp会使用Call来模化满足请求的任务,然而中间的请求和响应是必要的(重定向处理和IP出错)
Call执行有两种方式:
Synchronous:线程会阻塞直到响应可读。
Asynchronous:在一个线程中入队请求,当你的响应可读时在另外一个线程获取回调。
线程中的请求取消、失败、未完成,写请求主体和读响应主体代码会遇到IOExceptionDispatchar调度器:Dispatcher是okhttp3的任务调度核心类,负责管理同步和异步的请求,管理每一个请求任务的请求状态,并且其内部维护了一个线程池用于执行相应的请求
1
2
3
4
5
6
7
8
9// Dispatchar内部维护了三个队列
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();//等待执行的异步队列
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();//正在执行的异步队列
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();//同步队列
一个线程池
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
/*Deque是一个双向队列接口,Deque接口具有丰富的抽象数据形式,它支持从队列两端点检索和插入元素
当需要执行的线程大于所能承受的最大范围时,就把未能及时执行的任务保存在readyAsyncCalls队列中。当线程池有空余线程可以执行时,会调用promoteCall()方法把等待队列readyAsyncCalls中的任务放到线程池执行,并把任务转移到runningAsyncCalls队列中*/Interceptor拦截器:拦截器是一个强大的机制,它可以监控,重写和重试Calls,自带5种拦截器,在享学课堂的OkHttp部分有写,下面的缓存相关部分是缓存拦截器内相关的原理
缓存Cache
Cache来自OkHttpClient
Cache中采用了DiskLruCache,以Request的URL的md5为key,相应Response为value。此外Cache中还通过外观模式对外提供了InternalCache接口变量,用于调用Cache中的方法,也满足面向对象的接口隔离原则和依赖倒置原则等。
DiskLruCache和LruCache内部都是使用了LinkedHashMap去实现缓存算法的,只不过前者针对的是将缓存存在硬盘(/sdcard/Android/data//cache),而后者是直接将缓存存在内存;缓存策略CacheStrategy
CacheStrategy的内部工厂类Factory中有一个getCandidate方法,会根据实际的请求生成对应的CacheStrategy类返回,是个典型的简单工厂模式。其内部维护一个request和response,通过指定request和response来告诉CacheInterceptor是使用缓存还是使用网络请求,亦或两者同时使用。
缓存框架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78public Response intercept(Chain chain) throws IOException {
// 1.如果设置缓存并且当前request有缓存,则从缓存Cache中获取当前请求request的缓存response
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
// 2.传入的请求request和获取的缓存response通过缓存策略对象CacheStragy的工厂类get方法根据一些规则获取缓存策略CacheStrategy(这里的规则根据请求的request和缓存的Response的header头部信息生成的,比如是否有noCache标志位,是否是immutable不可变,缓存是否过期等等)
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
// 3.生成的CacheStrategy有2个变量,networkRequest和cacheRequest,如果networkRequest为Null表示不进行网络请求,如果cacheResponse为null,则表示没有有效缓存
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
// 4.缓存不可用,关闭
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// 5.如果networkRequest和cacheResponse都为Null,则表示不请求网络且缓存为null,返回504,请求失败
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
// 6.如果不请求网络,但存在缓存,则不请求网络,直接返回缓存,结束,不执行下一个拦截器
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
// 7.否则,请求网络,并调用下一个拦截器链,将请求转发到下一个拦截器
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
//8.请求网络,并且网络请求返回HTTP_NOT_MODIFIED,说明缓存有效,则合并网络响应和缓存结果,同时更新缓存
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
//9.若没有缓存,则写入缓存
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
}
return response;
}具流流程如下:
①如果本地没有缓存,直接发送网络请求;cacheResponse == null
如果当前请求是Https,而缓存没有TLS握手,则重新发起网络请求;
request.isHttps() && cacheResponse.handshake() == null
如果当前的缓存策略是不可缓存,直接发送网络请求;
!isCacheable(cacheResponse, request)
请求头no-cache或者请求头包含If-Modified-Since或者If-None-Match,则需要服务器验证本地缓存是不是还能继续使用,直接网络请求;
requestCaching.noCache() || hasConditions(request)
可缓存,并且ageMillis + minFreshMillis < freshMillis + maxStaleMillis(意味着虽过期,但可用,只是会在响应头添加warning),则使用缓存;
缓存已经过期,添加请求头:If-Modified-Since或者If-None-Match,进行网络请求;ConnectInterceptor(核心,连接池)
(下面有部分内容前面有过了)
okhttp的一大特点就是通过连接池来减小响应延迟。如果连接池中没有可用的连接,则会与服务器建立连接,并将socket的io封装到HttpStream(发送请求和接收response)中,HttpCodec(Stream):数据交换的流,对请求的编码以及对响应数据的解码(Stream:基于Connection的逻辑Http请求/响应对),RealConnecton(Collection):Connection实现类,主要实现连接的建立等工作;Http中Stream和Collection关系:Http1(Http1.0)1:1一个连接只能被一个请求流使用Http2(Http1.1)1:n一个连接可被多个请求流同时使用,且keep-alive机制保证连接使用完不关闭,当下一次请求与连接的Host相同时,连接可以直接使用,不用再次创建StreamAllocation(流分配):会通过ConnectPool获取或者创建一个RealConnection来得到一个连接到Server的Connection连接,同时会生成一个HttpCodec用于下一个CallServerInterceptor,以完成最终的请求;RouteDataBase:这是一个关于路由信息的白名单和黑名单类,处于黑名单的路由信息会被避免不必要的尝试;ConnectionPool:连接池,实现连接的复用;
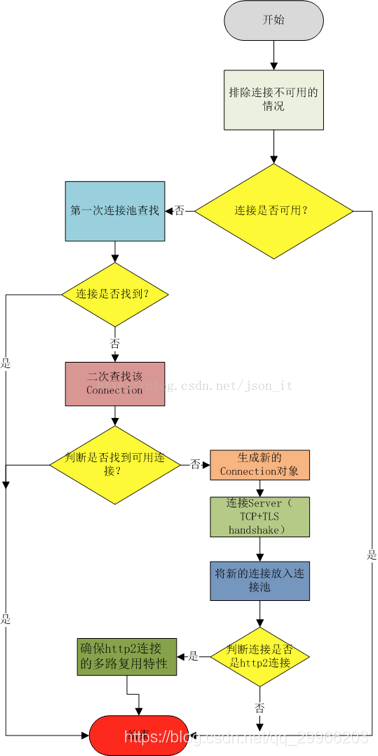
具体源码不看了,直接看步骤
1.框架使用URL和配置好的OkHttpClient创建一个address。此地址指定我们将如何连接到网络服务器。
2.框架通过address从连接池中取回一个连接。
3.如果没有在池中找到连接,ok会选择一个route尝试连接。这通常意味着使用一个DNS请求, 以获取服务器的IP地址。如果需要,ok还会选择一个TLS版本和代理服务器。
4.如果获取到一个新的route,它会与服务器建立一个直接的socket连接、使用TLS安全通道(基于HTTP代理的HTTPS),或直接TLS连接。它的TLS握手是必要的。
5.开始发送HTTP请求并读取响应。
如果有连接出现问题,OkHttp将选择另一条route,然后再试一次。这样的好处是当服务器地址的一个子集不可达时,OkHttp能够自动恢复。而且当连接池过期或者TLS版本不受支持时,这种方式非常有用。
一旦响应已经被接收到,该连接将被返回到池中,以便它可以在将来的请求中被重用。连接在池中闲置一段时间后,它会被赶出。CallServerInterceptor
CallServerInterceptor的intercept()方法里 负责发送请求和获取响应,实际上都是由HttpStream类去完成具体的工作。
一个socket连接用来发送HTTP/1.1消息,这个类严格按照以下生命周期:
1、 writeRequestHeaders()发送request header
httpCodec.writeRequestHeaders(request);
2、打开一个sink来写request body,然后关闭sinkSink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength());
3、readResponseHeaders()读取response头部responseBuilder = httpCodec.readResponseHeaders(true);
4、打开一个source来读取response body,然后关闭source
使用方法
调用流程
代码部分前面了
OkHttp请求过程解除最多的是OkHttpClient、Request、Call、Response,但是框架内部进行了大量的逻辑处理,所有逻辑处理大部分集中在拦截器中,但是进入拦截器之前还需要依靠分发器来调配请求任务
分发器:内部维护队列和线程池,完成请求调配
拦截器:完成整个请求过程(完成一次完整的http请求的过程,DNS解析->三次握手建立TCP连接(socket)->发送http报文)(当然这里还完成了许多的优化的功能,包括连接池等等)
分发器Dispatcher
下面这部分就相当于是OkHttp进行网络请求的具体流程,源码分析就分析其中一些具体部分
构建OkHttpClient对象构造者模式可以使用自己的分发器对象
OkHttpClient的newCall方法传入Request对象得到一个Call对象(Call是一个接口,实现类是RealCall类,将OkHttpClient对象、Request对象都交给RealCall去处理,然后返回对象)
然后调用RealCall对象的同步和异步请求的方法发起请求
然后看到enqueue异步请求方法(进入这个方法一进来就synchronized(this),加锁保证RealCall并限制只能进行同步请求或异步请求,不能同时进行,否则抛出异常,可以使用clone方法,克隆一个对象出来进行请求)(OkHttpClient还可以设置EventListener对象,可以监听请求的开始。。。)
然后enqueue内部就调用OkHttpClient的dispatcher方法去获取DisPatcher对象去执行enqueue方法,之后传入一个AsyncCall对象(可以看作请求任务),这个对象传入CallBack回调
进入分发器的enqueue方法,有RunningAsyncCalls(正在执行异步请求队列)、RunningSyncCalls(正在执行的同步请求队列)、ReadyAsyncCalls(等待异步请求队列)队列(ArrayDeque类型,内部循环数组,作者解释,如果把这个类型当做stack栈来使用,它比栈快,如果把它当做queue来使用,它比LinkedList快)
接下来就是分发器分发任务的过程,对于异步请求有两种方式,进入等待队列,进入执行队列
进入Running队列的请求任务就会加入线程池执行,也是在enqueue方法中的,在加入执行队列代码下一行就是让ExecutorService对象(其实就是线程池)的execute执行这个Call对象任务(线程池需要接收Runnable,Call也就是AsyncCall其实就是Runnable)
接下来就是执行AsyncCall这个里面的execute方法(AsyncCall继承的类中的run执行了一个抽象方法execute),下面其实就是通过getResponseWithInterceptorChain方法去走拦截器,返回Response,这里异常机制,finally代码块一定执行,执行client.dispatcher().finished(this),finish方法传入running队列,AsyncCall对象和true,然后从Running队列移除已经完成的Call对象,然后就循环根据下面提到的从Ready队列拿对象放到Running队列
离并发任务分发
异步请求
分发器怎么决定放入ready还是running队列?
是一个判断语句
第一个条件根据正在执行异步请求队列的个数决定的,分发器默认定义这个值为64,小于这个值直接加入Running队列,大于这个值就加入Ready队列(可以修改)
第二个条件是同一个域名的请求最大数不大于5个,默认值为5个
从Ready移动到Running的条件是什么?
任务结束判断,Running队列数量少于分发器规定的最大同时异步请求对象的数量,并且请求队列不为空,而且对于同一域名的请求数量少于定义的数量(多于的对象就找下一个),就移动到Running队列中
分发器线程池怎么定义的?
executorService其实就是线程池,new了一个ThreadPoolExecutor对象(这个就是最基本的线程池类,不是那几个特别的,可以看前面的部分,下面讲一下它构造这个对象传入的内容),这里传入的等待队列传入的类型是synchronousQueue(因为LinkedBlockingQueue和ArrayBlockingQueue不合适,如果使用ArrayBlockingQueue设定值为1,核心线程数为1,那么如果有一个线程一直在跑,又进来一个任务就会进入队列,再进来一个任务就又要入队,但是队列满了按照这个类型的等待队列就需要额外新建一个线程,但是会先跑任务3再跑任务2,就很有问题,因为我们需要线程进来就开始跑,并且按顺序来),那么如果达到线程池定义的最大线程数怎么办呢,就会需要使用线程池传入的拒绝策略的参数来进行处理

同步请求
同样是先一个判断语句一个call只能用一次,然后执行分发器的同步请求方法(这里面就是直接把这个call放入running队列,直接执行),最后使用分发器的finished方法(将完成同步请求的call从队列remove)
前面异步的具体流程直接看分发器的部分就可以了
线程池排队
OKHttp传入的工作队列类型决定了他的工作行为为无等待,最大并发的,这个就是具体的排队机制,这很符合OkHttp的使用场景,高并发的网络请求场景,但是并不会很容易OOM,因为前面分发器中定义的等待队列和
执行队列就是为了限制所有的异步请求的数量,避免了OOM
拦截器
责任链模式
(避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。)
请求从上往下去执行,响应再从下往上去回传

五大拦截器
RetryAndFollowUpInterceptor(重试和重定向拦截器)
第一个接触到请求,最后接触到响应;负责判断是否需要重新发起整个请求
BridgeInterceptor(桥接拦截器)
补全请求(如补全请求头,gzip解压or设置cookie),并对响应进行额外处理
CacheInterceptor(缓存拦截器)
请求前查询缓存,获得响应并判断是否需要缓存(需要使用就需要手动去开启缓存,就是在构建OkHttpClient的时候在Builder.cache(new Cache(存储路径,最大长度)))
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类可以分为强制缓存和对比缓存
强制缓存
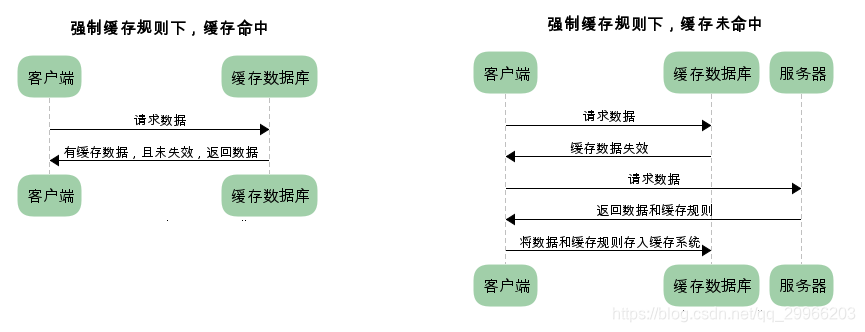
http1.1的head中Cache-Control字段标明失效规则,private客户端可以缓存;public客户端和代理服务器都可以缓存;max-age=xxx:缓存的内容将在 xxx 秒后失效;no-cache:需要使用对比缓存来验证缓存数据;no-store:所有内容都不会缓存,强制缓存,对比缓存都不会触发
对比缓存
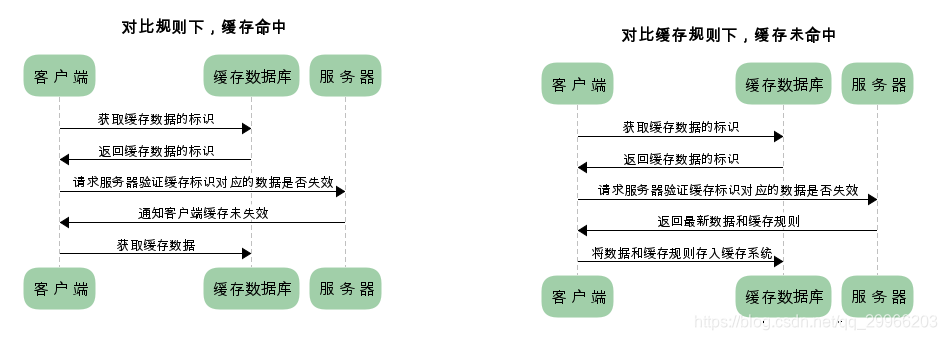
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
最重要的就是在header中的传递的两种标识,Last-Modified / If-Modified-Since,Last-Modified:
服务器在响应请求时,告诉浏览器资源的最后修改时间;If-Modified-Since:再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。还有Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since),Etag:
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定),If-None-Match:再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
ConnectInterceptor(链接拦截器)
与服务器完成TCP连接 (Socket)
CallServerInterceptor(请求服务拦截器)
与服务器通信;封装请求数据与解析响应数据(如:HTTP报文)
还可以自定义拦截器
在Builder的addInterceptor和addNetworkInterceptor可以传入自定义的拦截器,这两者的区别体现在添加到list的顺序不同,添加拦截器是在RealCall中完成的,getResponseWithInterceptorChain中完成的,addInterceptor添加到拦截器会在list的最前面,也就是在重试和重定向拦截器的前面,而addNetworkInterceptor添加的拦截器在最后一个请求连接器的前面
1 | Response getResponseWithInterceptorChain() throws IOException { |
拦截器中的ConnectionPool(连接池)看前面的OkHttp部分有提到原理
网络代理
这是网络通信必备基础中的socket通信原则中的内容,socket通信原则中有SOCKS代理和HTTP普通代理与隧道代理
设计模式
建造者模式
创建者模式又叫建造者模式,是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。创建者模式隐藏了复杂对象的创建过程,它把复杂对象的创建过程加以抽象,通过子类继承或者重载的方式,动态的创建具有复合属性的对象。OkHttp中HttpClient、Request构造便是通过建造者模式
简单工厂模式
okhttp 实现了Call.Factory接口
1
2
3
4
5
6
7
8
9interface Factory {
Call newCall(Request request);
}
//实现Call接口
public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}责任链模式
责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。看完只能说设计真的精妙,可以看下面这个博客一开始的代码就知道怎么写简单的责任链设计模式了行为型设计模式——责任链模式-CSDN博客
1
2
3
4
5
6
7
8
9
10public interface Interceptor {
String interceptor(Chain chain);
interface Chain {
String request();
String proceed(String request);
}
}
1
2
3
4
5
6
7
8
9public class BridgeInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 BridgeInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 BridgeInterceptor 拦截器之后代码 得到最终数据:"+proceed);
return proceed;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class RetryAndFollowInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 RetryAndFollowInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:" + proceed);
return proceed;
}
}
public class CacheInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 CacheInterceptor 最后一个拦截器 返回最终数据");
return "success";
}
}
public class RealInterceptorChain implements Interceptor.Chain {
private List<Interceptor> interceptors;
private int index;
private String request;
public RealInterceptorChain(List<Interceptor> interceptors, int index, String request) {
this.interceptors = interceptors;
this.index = index;
this.request = request;
}
public String request() {
return request;
}
public String proceed(String request) {
if (index >= interceptors.size()) return null;
//获取下一个责任链
RealInterceptorChain next = new RealInterceptorChain(interceptors, index+1, request);
// 执行当前的拦截器
Interceptor interceptor = interceptors.get(index);
return interceptor.interceptor(next);
}
}
//测试和结果
List<Interceptor> interceptors = new ArrayList<>();
interceptors.add(new BridgeInterceptor());
interceptors.add(new RetryAndFollowInterceptor());
interceptors.add(new CacheInterceptor());
RealInterceptorChain request = new RealInterceptorChain(interceptors, 0, "request");
request.proceed("request");
//打印出的log
/*执行 BridgeInterceptor 拦截器之前代码
执行 RetryAndFollowInterceptor 拦截器之前代码
执行 CacheInterceptor 最后一个拦截器 返回最终数据
执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:success
执行 BridgeInterceptor 拦截器之后代码 得到最终数据:success
*/
拦截器
由浅入深,聊聊OkHttp的那些事(易懂,不繁琐) - 掘金 (juejin.cn)
OkHttp中有五大拦截器
RetryAndFollowUpInterceptor(重试和重定向拦截器)
第一个接触到请求,最后接触到响应;
用于 请求失败 的 重试 工作以及 重定向 的后续请求工作,同时还会对 连接 做一些初始化工作。
- 请求时如果遇到异常,则根据情况去尝试恢复,如果不能恢复,则抛出异常,跳过本次请求;如果请求成功,则在
finally里释放资源; - 如果请求是重试之后的请求,那么将重试前请求的响应体设置为null,并添加到当前响应体的
priorResponse字段中; - 根据当前的responseCode判断是否需要重试,若不需要,则返回
response;若需要,则返回request,并在后续检查当前重试次数是否达到阈值; - 重复上述步骤,直到步骤三成功。
在第一步时,获取
response时,需要调用realChain.proceed(request),如果你还记得上述的责任链,所以这里触发了下面的拦截器执行,即BridgeInterceptor。- 请求时如果遇到异常,则根据情况去尝试恢复,如果不能恢复,则抛出异常,跳过本次请求;如果请求成功,则在
BridgeInterceptor(桥接拦截器)
补全请求(如补全请求头,gzip解压or设置cookie),并对响应进行额外处理
用于 客户端和服务器 之间的沟通 桥梁 ,负责将用户构建的请求转换为服务器需要的请求。比如添加
content-type、cookie等,再将服务器返回的response做一些处理,转换为客户端所需要的response,比如移除Content-Encoding- 首先调用
chain.request()获取原始请求数据,然后开始重新构建请求头,添加header以及cookie等信息; - 将第一步构建好的新的
request传入chain.proceed(),从而触发下一个拦截器的执行,并得到 服务器返回的response。然后保存response携带的cookie,并移除header中的Content-Encoding和Content-Length,并同步修改body。
- 首先调用
CacheInterceptor(缓存拦截器)
请求前查询缓存,获得响应并判断是否需要缓存(需要使用就需要手动去开启缓存,就是在构建OkHttpClient的时候在Builder.cache(new Cache(存储路径,最大长度)))(走的DiskLruCache磁盘缓存)
下面是Http缓存的规则,上面的图是OkHttp缓存规则图,HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类可以分为强制缓存和对比缓存
强制缓存
http1.1的head中Cache-Control字段标明失效规则,private客户端可以缓存;public客户端和代理服务器都可以缓存;max-age=xxx:缓存的内容将在 xxx 秒后失效;no-cache:需要使用对比缓存来验证缓存数据;no-store:所有内容都不会缓存,强制缓存,对比缓存都不会触发
对比缓存
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
最重要的就是在header中的传递的两种标识,Last-Modified / If-Modified-Since,Last-Modified:
服务器在响应请求时,告诉浏览器资源的最后修改时间;If-Modified-Since:再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。还有Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since),Etag:
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定),If-None-Match:再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
ConnectInterceptor(链接拦截器)
与服务器完成TCP连接 (Socket)
先通过
ExchangeFinder去RealConnecionPool中尝试寻找已经存在的连接,未找到则会重新创建一个RealConnection(连接) 对象,并将其添加到连接池里,开始连接。然后根据找到或者新创建RealConnection对象,并根据当前请求协议创建不同的ExchangeCodec对象并返回,最后初始化一个Exchange交换器并返回,从而实现了Exchange的初始化过程。在具体找寻
RealConnection的过程中,一共尝试了5次,具体如下:- 尝试重连
call中的connection,此时不需要重新获取连接; - 尝试从连接池中获取一个连接,不带路由与多路复用;
- 再次尝试从连接池中获取一个连接,带路由,不带多路复用;
- 手动创建一个新连接;
- 再次尝试从连接池中获取一个连接,带路由与多路复用;
当
Exchange初始化完成后,再复制该对象创建一个新的Exchange,并执行下一个责任链,从而完成连接的建立。- 尝试重连
CallServerInterceptor(请求服务拦截器)
与服务器通信;封装请求数据与解析响应数据(如:HTTP报文)
先写入要发送的请求头,然后根据条件判断是否写入要发送的请求体。当请求结束后,解析服务器返回的响应头,构建一个新的
response并返回;如果response.code为 100,则重新读取响应体并构建新的response。因为这是最底层的拦截器,所以这里肯定不会再调用proceed()再往下执行。
还可以自定义拦截器
在Builder的addInterceptor和addNetworkInterceptor可以传入自定义的拦截器,这两者的区别体现在添加到list的顺序不同,添加拦截器是在RealCall中完成的,getResponseWithInterceptorChain中完成的,addInterceptor添加到拦截器会在list的最前面,也就是在重试和重定向拦截器的前面,而addNetworkInterceptor添加的拦截器在最后一个请求连接器的前面
1 | Response getResponseWithInterceptorChain() throws IOException { |
拦截器中的ConnectionPool(连接池)看前面的OkHttp部分有提到原理








