Android知识秘籍
总结自下面链接,转载请使用大佬的博客地址
https://blog.csdn.net/qq_29966203/article/details/105455615?spm=1001.2014.3001.5502
第一章 四大组件
- 介绍一下四大组件?
- Activity
- 生命周期
- 参数传递
- 启动过程
- 启动模式
- 状态保存 & 恢复
- Service
- 启动方式 & 生命周期
- 适用场景(Service 与 Thread 对比)
- Service 分类 & 使用
- IntentService
- Service和Activity 通信
- ContentProvider
- 描述
- 使用
- BroadcastReceiver
- 描述
- 分类
- 注册方式
- 使用方式:发送\接受\屏蔽 广播
- Context
- 理解 & 作用
- 分类
- 内存泄露
- Intent
- 指定当前组件要完成的动作
- 传递数据
- Application
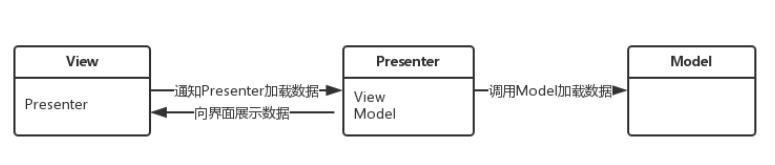
介绍一下四大组件?
- Activity(活动)
Activity是Android程序与用户交互的窗口,是Android构造块中最基本的一种。它为用户提供一个窗口,上面可以显示一些控件用于监听并处理用户的事件。 - Service(服务)
Service提供需在后台长期运行的服务,无用户界面。一个组件可以与一个Service进行绑定实现组件之间的交互。Service可以在后台执行很多任务,如处理网络事务,播放音乐,文件读写下载等等。 - Content Provider(内容提供者)
Content Provider是Android官方推荐的不同应用程序间进行数据交互&共享的方式。ContentProvider为存储和获取数据提供统一的接口,相当于数据的搬运工(中间者),真正的数据源为Sqlite/文件/XML/网络等。 - BroadcastReceiver(广播接收器)
BroadcastReceiver相当于一个全局监听器,用于接收应用间/应用内发出的广播信息,并作出响应。
Activity
生命周期
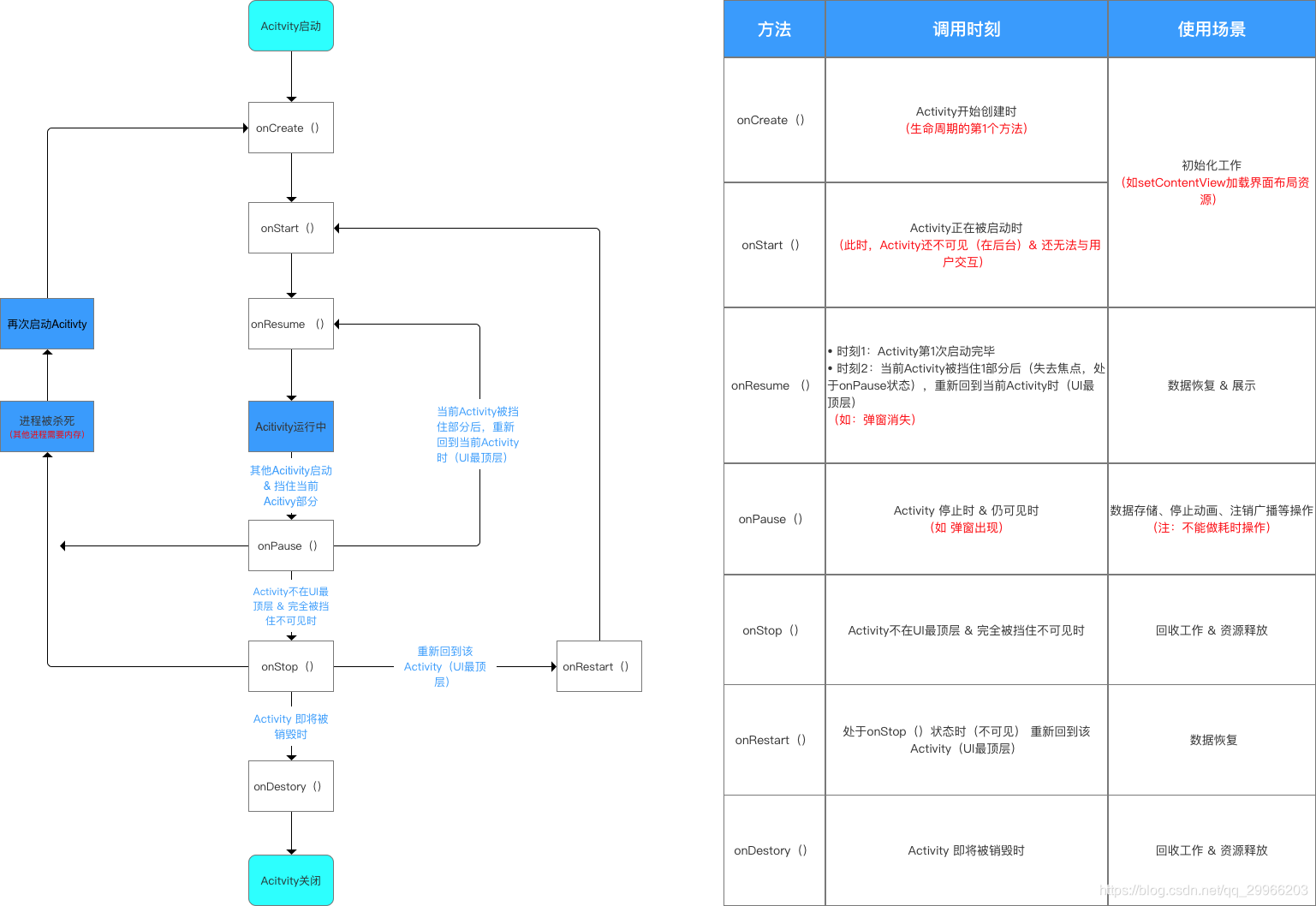

Activity生命周期包括四种状态、七种方法、两个异常:
- 四种状态
- Running状态:处于栈的最顶端,此时它处于可见并可和用户交互的激活状态。
- Paused状态:当Activity被另一个透明或者Dialog样式的Activity覆盖时的状态。它仍然可见,但失去了焦点,故不可与用户交互。
- Stopped状态:当Activity完全不可见,处于后台时,但仍保留着当前状态和成员信息
- Killed状态:当前界面被销毁,等待被系统回收
- 七个方法
- onCreate():在Activity创建时调用。一般用来做一些初始化操作,如初始化布局setContentLayout()
- onStart():在Activity即将显示界面时调用,但用户无法操作。一般也用于做一些初始化操作,但对于Activity而言,onCreate只执行一次,但onStart可执行多次。
- onResume():在Activity获取焦点开始与用户交互时调用,此时Activity处于运行状态,位于栈顶。一般用于数据恢复、开启动画等
- onPause():在当前Activity被其他Activity覆盖部分或锁屏时调用,此时Activity处于暂停状态,仍然可见,但失去焦点,不能与用户交互。一般用于关闭动画,注销广播等。并应进行状态保存与数据存储,但不适合做耗时操作。(为了让新的Activity尽快切换到前台)
- onStop():在Activity对用户完全不可见时调用,此时Activity处于停止状态。此时进程优先级较低,当系统内存不足时,容易被杀死。一般用于进行资源回收。
- onDestory():在Activity销毁时调用,常用于释放资源,Activity处于销毁状态后,将被清出内存。
- onRestart():在Activity从停止状态再次启动时调用。onRestart一般是应用位于后台重新切换为前台调用,可用于进行数据刷新。
其中onCreate() & onDestory()、onStart() & onStop()、onResume() & onPause()成对出现。
- 两个异常
- 更高优先级的进程需要内存,但系统内存不足
处于暂停/停止状态(低优先级)可能会被直接杀死onStop()->直接杀死进程(当前Activity)
手动重启当前Activity->onCreate()->onStart()->onResume()->运行 - 系统配置发生改变导致Activity意外销毁(如横竖屏切换、键盘事件等)
Running->onSaveInstanceState()->onPause()->onStop()->onDestroy()->自动重启->onCreate()->onStart()->onRestoreInstanceState()->onResume()->Running
在onSaveInstanceState()保存Activity状态。适合保存一些非持久数据,如布局状态、成员变量的值等,持久数据适合在onPause()与onStop()中通过数据库、sharedpreference保存
在onRestoreInstanceState()/onCreate()恢复Activity状态。
补充:Activity各种实际场景下生命周期的变换
(1)横竖屏切换、键盘事件等系统配置(自动重启)
->onPause->onSaveInstanceState->onStop->onDestroy->onCreate->onStart->onRestoreInstanceState->onResume
(2)横竖屏切换总结
- 设置
a. 静态设置,即在Mainfest文件中配置screenOrientation属性
1 | // 控制Activity为竖屏显示 |
b. 动态设置,即调用Activity的setRequestedOrientation(@ActivityInfo.ScreenOrientation int requestedOrientation)方法设置screenOrientation属性值
- Activity生命周期
关于Android横竖屏切换Activity是否会销毁重建,这个由Activity的configChanges属性控制。
a. Activity 不销毁重建
下方配置可以控制Activity在横竖屏切换时不销毁重建
1 | android:configChanges="orientation|keyboardHidden|screenSize" |
配置了android:configChanges=”orientation|keyboardHidden|screenSize”横竖屏切换时Activity不会销毁重建,而是会回调Activity的onConfigurationChanged方法。
b. Activity销毁重建
- 不配置configChanges属性
- 设置android:configChanges=“orientation”
- 设置android:configChanges=“orientation|keyboardHidden”
以上三种配置,横竖屏切换时Activity均会销毁重建,Activity的生命周期都会重新执行一次
onPause -> onStop -> onDestroy -> onCreate -> onStart -> onResume
(3)锁屏/息屏/Home/打开新Activity/处于后台,并手动重启
->onPause->-> onSaveInstanceState->onStop->onReStart->onStart->onResume
(4)Back键退出当前Activity
onPause->onStop->onDestroy
(5)Aactivity切换Bactivity
AActivity:->onPause()
BActivity:onCreate()->onStart()->onResume()
AActivity:onStop()
(6)Aactivity切换Bactivity(透明/对话框)
AActivity:->onPause()
BActivity:onCreate()->onStart()->onResume()
面试题
1、弹出普通Dialog和一个自定义Dialog视图的Activity(android:theme=”@style/dialogstyle”)生命周期有什么区别?
(1)弹出普通Dialog:Activity周期不发生变化。因为Dialog依附于 Activity, Activity仍位于前台。
(2)弹出Dialog视图的Activity:
原Activity:onPause()
Dialog样式Activity:onCreate()->onStart()->onResume()
2、两个Activity 之间跳转时必然会执行的是哪几个方法?
当在A Activity里面激活B Activity的时候, A会调用onPause()方法,然后B调用onCreate() ,onStart(), onResume()。
这个时候B覆盖了A的窗体, A会调用onStop()方法。
如果B是个透明的窗口,或者是对话框的样式, 就不会调用A的onStop()方法。
如果B已经存在于Activity栈中,B会调用onReStart()->onStart()->onResume()
故一定会执行A的onPause()和B的onStart()与onResume()。
参数传递
- 通过Intent传递
- 使用putExtra,可直接传递单一基本数据类型,或用Bundle封装多种数据类型再传递或者传递经Serializable/Parcelable序列化对象
1 | // 传递基本数据类型 |
- 使用startActivityForResult+setResult获取新Activity关闭后返回的数据
FirstActivity.java
1 | // FirstActivity.java |
SecondActivity.java
1 | public class SecondActivity extends Activity{ |
- 通过直接访问类的静态变量实现
- 在Application(单例模式)设置应用的全局变量,可在程序中通过getApplication随时调用
- 使用EventBus插件传输数据量较大的数据
订阅者
1 | //使用EventBus的接收方法的Activity,需要注册监听 |
发布者
1 | EventBus.getDefault().post(new MyEvent("Event From Publisher")); |
- 借助外部存储,如SharedPreference、Sqlite或者File等
启动过程
Activity的启动过程,我们可以从Context的startActivity说起,其实现是ContextImpl的startActivity,然后内部会通过Instrumentation来尝试启动Activity,这是一个跨进程过程,它会调用AMS的startActivity方法
当AMS校验完activity的合法性后,将activity入栈,并创建新的应用进程ActivityThread,这个过程是在ActivityStack里完成的,ActivityStack是运行在Server进程里的。
此时Server进程会通过ApplicationThread回调到我们的进程通知app进程ActivityThread绑定Application并启动Activity,这也是一次跨进程过程,而ApplicationThread就是一个binder,回调逻辑是在binder线程池中完成的,所以需要通过Handler H向主线程ActivityThread发送操作消息
绑定Application发送的消息是BIND_APPLICATION,对应的方法是handleBindApplication,该方法中对进程进行了配置,并创建及初始化了Application。启动Activity发送的消息是LAUNCH_ACTIVITY,对应的方法handleLaunchActivity,在这个方法里完成了Activity的创建和启动,回调Activity相关的周期方法。接着,在activity的onResume中,activity的内容将开始渲染到window上,然后开始绘制直到我们看见。
启动模式
Activity的启动模式有四种:standard、singleTop、singleTask和singleInstance。我们可以通过在AndroidManifest.xml的activity标签下通过launchMode属性指定想要设置的启动模式。
1 | <activity android:name=".MainActivity" |
- standard(标准模式)
该启动模式为默认模式。标准模式下,只要启动一次Activity,不管该实例是否存在,系统都会在当前任务栈中新建一个Activity实例并将该实例置于栈顶。
该模式用于正常打开一个新的页面。使用最多,最普通。 - singleTop(栈顶复用模式)
栈顶复用模式下,如果要启动的Activity已经处于栈的顶部,那么此时系统不会创建新的实例,而是复用栈顶的实例,同时它的onNewIntent()方法会被执行,我们可以通过Intent进行传值。否则会创建一个新的实例。
SingleTop适用于接受推送通知的内容显示页面,防止每点击一次通知重新打开重复页面。 - singleTask(栈内复用模式)
栈内复用模式下,首先会根据taskAffinity去寻找对应的任务栈:
1、如果不存在指定的任务栈,系统会新建对应的任务栈,并新建一个Activity实例压入栈中。
2、如果存在指定的任务栈,则会查找该任务栈中是否存在该Activity实例
a、如果不存在该实例,则会在该任务栈中新建一个Activity实例压入栈中。
b、如果存在该实例,则将任务栈中该Activity实例之上的所有Activity出栈并将所需Activity置于栈顶。
SingleTask这种启动模式最常使用的就是一个APP的首页,因为一般为一个APP的第一个页面,且长时间保留在栈中,所以最适合设置singleTask启动模式来复用。 - singleInstance(单例模式)
单例模式拥有singleTask(栈内复用)所有特性外且该Activity实例单独占用一个任务栈,具有全局唯一性。该模式启动的activity在系统中是单例的。如果已存在,则将它所在的任务栈调度到前台,进行复用。
适用于与程序分开,具有独立功能的页面,如闹铃提醒,电话拨号等。
任务栈 & 任务
[Android 任务栈][Android]
可简单理解,一个应用程序对应一个任务,任务以栈的方式存储一系列与用户交互的Activity
状态保存 & 恢复
- 需要保存/恢复Activity状态的场景
当一些异常的场景导致某个activity变得”容易”被系统销毁(而不是被用户主动销毁(如点击BACK键))时,系统 会调用onSaveInstanceState方法来给用户提供一个存储现场的机会。
这些场景包括:锁屏、点击home键、其他app进入前台、启动新的activity、(当前activity可能被销毁)横竖屏切换、由于内存不足app被杀死(一定被销毁)等。
当该activity被系统销毁后重启回到前台时,系统会调用onRestoreInstanceState恢复Activity中数据。 - 如何保存/恢复Activity状态
我们通常在系统调用onSaveInstanceState(Bundle savedInstanceState)中,我们可以在该方法中用一组存储在Bundle对象中的键值对集合保存该Activity当前状态/需要恢复的数据。当我们重启该Activity时,上述的Bundle对象会作为实参传递给onCreate()与onRestoreInstanceState(Bundle savedInstanceState)方法, 我们可以从Bundle对象中取出保存的数据, 然后利用这些数据将activity恢复到被摧毁之前的状态.
1 |
|
Service
启动方式 & 生命周期
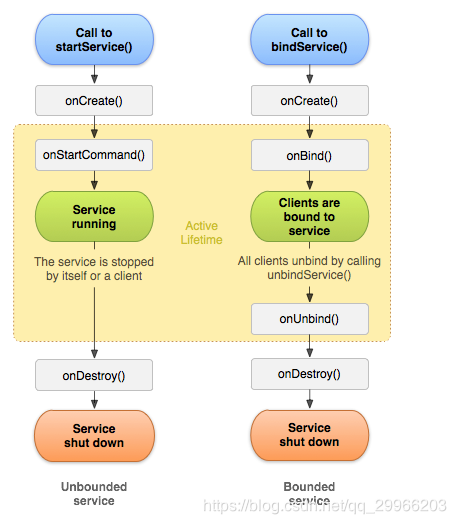
- Service 有2种启动方式
- startService()方式启动服务,调用者与Service没有关联。只有当Service调用stopSelf()或调用者调用stopService()才能停止服务。
- bindService()方式启动服务,调用者与Servie绑定,可以与Service进行交互。当所有调用者退出后,Service会自动停止。
- Service 有5种生命周期方法
| 回调 | 描述 |
|---|---|
| onStartCommand() | 其他组件(如活动)通过调用startService()来请求启动服务时,系统调用该方法。如果你实现该方法,你有责任在工作完成时通过stopSelf()或者stopService()方法来停止服务。 |
| onBind() | 当其他组件想要通过bindService()来绑定服务时,系统调用该方法。如果你实现该方法,你需要返回IBinder对象来提供一个接口,以便客户来与服务通信。你必须实现该方法,如果你不允许绑定,则直接返回null。 |
| onUnbind() | 当客户中断所有服务发布的特殊接口时,系统调用该方法。 |
| onCreate() | 当服务通过onStartCommand()和onBind()被第一次创建的时候,系统调用该方法。该调用要求执行一次性安装。 |
| onDestroy() | 当服务不再有用或者被销毁时,系统调用该方法。你的服务需要实现该方法来清理任何资源,如线程,已注册的监听器,接收器等。 |
- Service的生命周期根据启动方式分3种情况
- 只用startService启动服务:onCreate-> onStartCommand-> onDestory
- 只用bindService绑定服务:onCreate-> onBind-> onUnBind-> onDestory
- 同时用startService启动服务与用bindService绑定服务:onCreate-> onStartCommnad-> onBind-> onUnBind-> onDestory
| 服务启动方式 | startService | bindService |
|---|---|---|
| 方法参数 | Intent:用于启动服务 | Intent:用于启动服务 ServiceConnection:Activity 和 Service 建立连接时通信使用 |
| 服务周期 | 启动服务后服务将一直在后台运行,即使 Activity 销毁依然存在 | 假如没有先 startService,bindService后绑定的最后一个 Activity 销毁时,service也将销毁,且bindService后的Service 在系统 Running 任务管理器下是看不见的。但先startService,接着 bindService 时,系统 Running 任务管理器显示该服务,Service 解绑后,onDestroy并不会得到运行 |
适用场景(Service 与 Thread 对比)
Service和Thread均没有界面,在后台运行。
| Service | Thread | |
|---|---|---|
| 运行线程 | 主线程 | 工作线程 |
| 依赖 | 不依赖Activity,所有Activity都可以与该Service关联 | 依赖某个Activity,在某个Activity创建进程,其他Activity无法获取 |
| 优先级 | 提高进程的优先级,系统不容易回收进程 | 在activity中开启的子线程按照优先级回收,易回收 |
| 适用场景 | 长期在后台运行的操作 | activity中需要处理的耗时操作 |
Android 系统进程管理是按照一定规则的:应用程序一旦打开,为了下一次快速启动,关闭(清空任务栈)后进程不会停止。会带来内存不足的问题。Android系统有一套内存清理机制,根据进程优先级回收系统内存。服务的作用就是提高进程的优先级,使系统不容易回收进程。因此对于需要在后台长期运行的操作,不要在activity中开启子线程,应该创建服务,在服务里开启子线程。
如:长期在后台运行的没有界面的组件。如天气预报、股票显示(后台连接服务器的逻辑,每隔一段时间获取最新的(天气、股票)信息)、mp3播放器(后台长期播放音乐)等。
Service 分类 & 使用
- 不可交互的后台服务
不可交互的后台服务即是普通的Service,通过startService()方式开启。Service的生命周期很简单,分别为onCreate、onStartCommand、onDestroy这三个。
音乐播放器案例,继承Service类实现自定义Service,提供在后台播放音乐、暂停音乐、停止音乐的方法。
1 | public class MyService extends Service { |
①Service不运行在一个独立的进程中,它同样执行在UI线程中,因此,在Service中创建了子线程来完成耗时操作。
②当Service关闭后,如果在onDestory()方法中不关闭线程,你会发现我们的子线程进行的耗时操作是一直存在的,此时关闭该子线程的方法需要直接关闭该应用程序。因此,在onDestory()方法中要进行必要的清理工作。
(2)在清单文件中声明Service,为其添加label标签,便于在系统中识别Service
1 | <service |
如果想配置成远程服务,加如下代码:
1 | android:process="remote" |
(3)Activity中在布局中添加三个按钮,用于控制音乐播放、暂停与停止
1 | public class MainActivity extends AppCompatActivity { |
- 可交互的后台服务
可交互的后台服务是指前台页面可以调用后台服务的方法,通过bindService()方式开启。Service的生命周期很简单,分别为onCreate、onBind、onUnBind、onDestroy这四个。
- 创建服务类
和普通Service不同在于这里返回一个代理对象,返回给前台进行获取,即前台可以获取该代理对象执行后台服务的方法
1 |
|
- 前台调用
通过以下方式绑定服务:
1 | bindService(mIntent,con,BIND_AUTO_CREATE); |
当建立绑定后,onServiceConnected中的service便是Service类中onBind的返回值。如此便可以调用后台服务类的方法,实现交互。
1 | private ServiceConnection con = new ServiceConnection() { |
可参考回调方式实现与Activity交互案例
- 前台服务
所谓前台服务只不是通过一定的方式将服务所在的进程级别提升了。前台服务会一直有一个正在运行的图标在系统的状态栏显示,非常类似于通知的效果。
由于后台服务优先级相对比较低,当系统出现内存不足的情况下,它就有可能会被回收掉,所以前台服务就是来弥补这个缺点的,它可以一直保持运行状态而不被系统回收。
创建服务类
前台服务创建很简单,其实就在Service的基础上创建一个Notification,然后使用Service的startForeground()方法即可启动为前台服务。
1 | public class ForeService extends Service{ |
启动前台服务
1 | startService(new Intent(this, ForeService.class)); |
IntentService
- 定义
由于Service默认运行在主线程中,所以如果直接在服务中处理耗时操作,容易出现ANR。此时可引用IntentService。
IntentService本质上是一个封装了HandlerThread+Service的异步框架,继承自Service。在使用完后会自动停止,适合需要在工作线程中按先后顺序,处理UI无关/后台 的耗时任务的场景,如离线下载。
不适用于多个数据同时请求的场景,因为所有的任务都在同一个Thread loop里执行,故按照先后顺序。
- 使用
(1)定义IntentService子类,构造方法传入线程名称,复写onHandleIntent()方法
1 | public class myIntentService extends IntentService{ |
(2)在AndroidManifest.xml中注册服务
1 | <service android:name=".myIntentService"> |
(3)在Activity中开启服务
1 | public class MainActivity extends AppCompatActivity { |
输出结果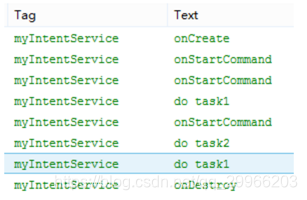
一个服务只会创建一次onCreate,只会开启一个工作线程。在onHandleIntent中依次处理传入的Intent
- 源码分析
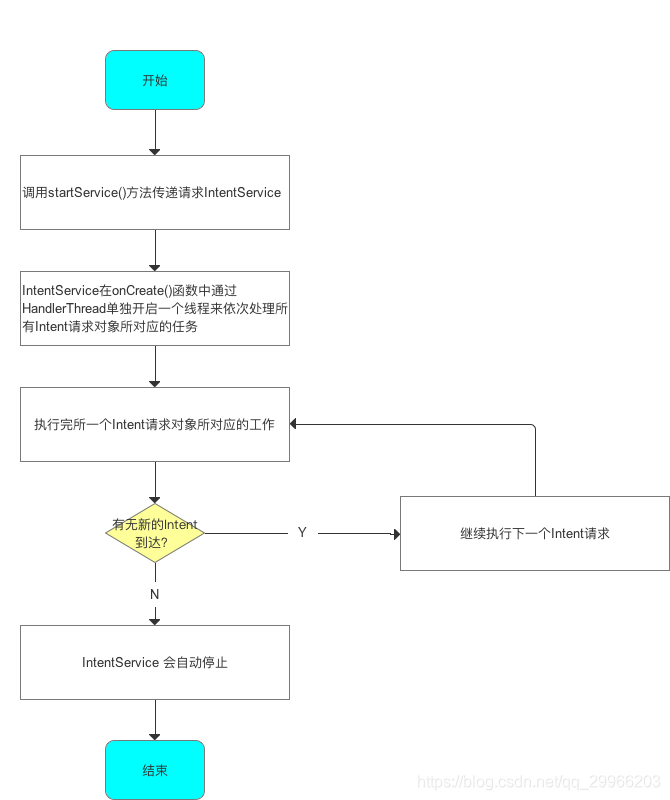
IntentService本质上是一个封装了HandlerThread+Service的异步框架。若启动IntentService 多次,但只创建一个工作线程,因此 每个耗时操作 则 以队列的方式 在 IntentService的 onHandleIntent回调方法中依次执行,执行完自动结束。 - onCreate
(1)IntentService 通过 HandlerThread 开启一个新的工作线程 ServiceThread
(2)创建1个内部 Handler:ServiceHandler,并将ServiceHandler 与 ServiceThread 绑定,接受这个工作线程的消息队列中的消息,重写onHandleIntent()依次处理这些消息(根据Intent 的不同执行不同操作)。
1 |
|
- onStartCommand
IntentService将Intent传递给ServiceHandler & 依次插入到工作队列 & 逐个发送给onHandleIntent()
1 | /** |
IntentService只会创建一个工作任务队列,因此多次启动 IntentService 时,每一个耗时操作(通过Intent逐一发送请求)会以工作队列的方式在IntentService的onHandleIntent回调方法中执行,会按串行的方式顺序执行事件。
即 若一个任务正在IntentService中执行,此时你再发送1个新的任务请求,这个新的任务会一直等待直到前面一个任务执行完毕后才开始执行
- IntentService & Service 区别
| IntentService | Service | |
| 运行线程 | 创建一个独立的工作线程处理异步任务(耗时操作) | 主线程 |
| 结束服务操作 | 需手动调用stopService() | 处理完所有intent请求后,系统自动关闭服务 |
| 联系 | IntentService继承自Service IntentService为Service的onBind()默认实现:return null IntentService为Service的onStartCommand()提供默认实现:将请求的intent添加到队列 |
|
- IntentService & 其他线程 区别
| 作用 | 优先级 | |
|---|---|---|
| IntentService | 后台线程,提供服务(继承自Service) | 高 |
| 其他线程 | 工作线程,处理异步任务 | 低,容易被系统杀死 |
Service和Activity 通信
Service与Activity有2种方式进行通信:
- bindService + 回调函数
Activity调用bindService方法,绑定一个Service。通过实例化ServiceConnection接口内部类监听的方法获取Service中的Binder对象,并将该接口传给binderService方法。如果想实现主动通知Activity的,还可以在Service中添加回调方法。
(1)新建一个回调接口,通过回调接口实现当Service中进度发生变化主动通知Activity更新UI
1 | public interface OnProgressListener { |
(2)新建一个Service类
1 | public class MsgService extends Service { |
(3)Activity中新建一个ServiceConnection对象,它是一个接口,Activity与Service绑定后,在onServiceConnected回调方法中返回服务对象。
onServiceConnected用于执行Activity与Service绑定后执行相关操作。
1 | public class MainActivity extends Activity { |
- 广播(推荐LocalBroadcastManager)
Activity调用registerReceive注册广播接收器,通过startService启动一个Service,之后Service调用sendBoardcast向Activity发送广播。Activity则通过onReceive方法接收Service发送的消息。
ContentProvider
描述
ContentProvider主要用于在不同的应用程序之间实现数据共享的功能。
ContentProvider=中间者角色(搬运工),真正存储&操作数据的数据源为原来存储数据的方式(数据库(sqlite)、文件、XML、网络等等)
ContentProvider一般为存储和获取数据提供统一的接口,可以在不同的应用程序之间共享数据。
它的设计用意在于:
(1)对底层数据库的抽象
对数据进行封装,提供统一的接口。使用者不必关心这些数据来源于数据库、XML、Preferences或请求。当项目改变数据来源时,不会对使用代码产生影响。
(2)提供一种跨进程数据共享方式
数据在多个应用程序中共享,当一个应用程序改变共享数据时候,可用ContentResolver接口的notifyChange函数通知那些注册了监控该URI的ContentObserver对象,去通知其他应用程序共享数据被修改了,使得它们可以相应地执行一些处理。
(3)用安全的方式对数据进行封装
是ContentProvider为应用间的数据交互提供了一个安全的环境。它准许你把自己的应用数据根据需求开放给其他应用进行增、删、改、查。通过android:exported属性指示该服务是否能够被其他应用程序组件调用或跟它交互,通过permission属性对于需要开放的组件设置合理的权限,通过path-permission可开放部分uri进行共享。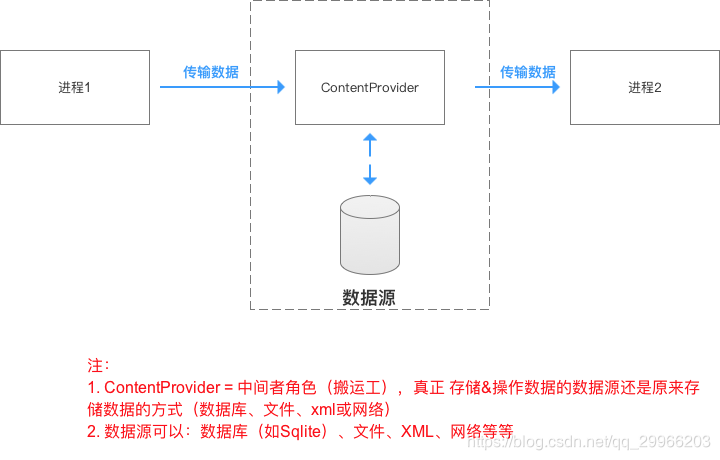
使用
- 使用原理
内容提供者是一种跨应用访问数据库的方式。一个应用可以通过内容提供者将自己的私有数据暴露出来,其他应用通过内容解析者对数据进行增删改查等操作。 - 使用场景
由于ContentProvider是向其他应用暴露数据库接口,不能保证应用所定义的数据库的安全性。因此往往不用于自定义数据库。适用于获取系统数据库的接口,如短信数据库、联系人数据库。 - 实例
- 自定义Sqlite数据库
(1)创建数据库类 集成SQLiteOpenHelper
1 | public class DBHelper extends SQLiteOpenHelper { |
(2)自定义ContentProvider 子类,继承自ContentProvider。并在清单文件中配置内容提供者
MyProvider.java
1 | public class MyProvider extends ContentProvider { |
AndroidManifest.xml
1 | <provider android:name="MyProvider" |
(3)由于第一个应用的私有数据库已通过ContentProvider暴露,因此第二个应用可以使用内容解析者对数据进行操作
1 | public class MainActivity extends AppCompatActivity { |
- 系统短信数据库
系统短信目录位于com.android.provider.telephony内的mmssms.db(Provider 管理的私有数据库包括 com.android.provider.* 如applications、calendar、downloads等等)
权限 -rw-rw—- 对一般用户不可读不可写不可执行(完全私有)=> 通过ContentProvider 暴露接口。
linux 文件访问权限
Linux的文件访问权限分为 读、写、执行三种:
drwxr-xr-x意思如下:
第一位表示文件类型:
d是目录文件,l是链接文件,-是普通文件,p是管道。
后面分为三个三位来看,分别表示不同用户的权限:
第一个 rwx: root :r 是可读,w 是可写,x 是可执行,rwx 意思是可读可写可执行。
第二个 r-x: 一般用户(用户组):r-x 是可读可执行不可写。
第三个 r-x: 其他用户,r-x 是可读可执行不可写。
综合起来就是权限设置为:文件所有者(root)可读可写可执行,与文件所有者同属一个用户组的其他用户可读可执行,其它用户组可读可执行。

1 | public void click(View v){ |
记得申请权限
1 | <uses-permission android:name="android.permission.WRITE_SMS" /> |
BroadcastReceiver
描述
- BoardcastReceiver 简介
BroadcastReceiver是一个全局监听器,用于监听应用间/应用内发出的广播消息,并作出响应。分为广播发送者和广播接受者。
系统在特定场景会发送广播,如电量低、插入耳机、状态改变等等。每个应用程序都会收到;应用程序也可以发送广播用来通知其他APP状态变化;
如果我们的应用程序想接收特定的广播并执行相关操作,便可注册一个BroadcastReceiver进行监听对应的广播,并在onReceive中执行操作。 - BoardcaseReceiver 原理
Android中广播使用设计模式中观察者模式,基于消息的发布/订阅事件模型。模型中有3个角色:消息订阅者(广播接受者)、消息发布者(广播发布者)、消息中心(AMS)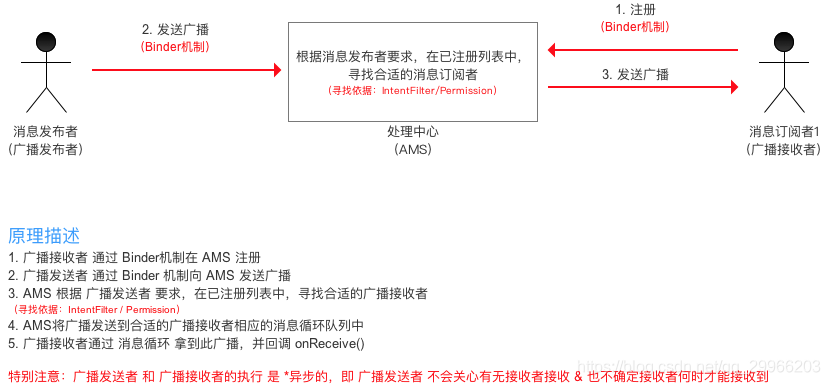
分类
| 类型 | 介绍 | 使用 |
|---|---|---|
| 普通广播 | 自定义广播为开发者自身定义的广播。 | 开发者定义广播的intent,并通过sendBroadcast()方法发送。 |
| 系统广播 | Android中内置了多个系统广播:包括手机的状态变化与基本操作(如开机、网络状态变化、电量状况、拍照等等),都会发出相应的广播。(每个广播都有特定的Intent - Filter(包括具体的action))。 | 当使用系统广播时,只需要在注册广播接收者时定义相关的action即可,并不需要手动发送广播,当系统有相关操作时会自动进行系统广播 |
| 有序广播 | 有序广播通过sendOrderedBroadcast发送,发送出去的广播根据广播接受者的优先级Priority按先后顺序接收。广播在发送过程中可被优先级较高的接受者拦截并修改再传给下一接受者。 | sendOrderedBroadcast(intent); |
| 无序广播 | 无序广播直接通过sendBroadcast发送,发送的广播不可被拦截也无法被修改。 | sendBroadcast(intent); |
| 全局广播 | 在应用间、应用与系统间、应用内部进行通信的一种方式。 | 默认BroadcastReceiver是跨应用广播 |
| 本地广播 | 本地广播仅能在自己应用内发送、接收广播。即发送的广播只能在自身app传播,且接收不到其他app发送的广播。故更加安全与高效。 | (1)注册广播时将exported属性设置为false,使得非本App内部发出的此广播不被接收;(2)在广播发送和接收时,增设相应权限permission,用于权限验证;(3)发送广播时指定该广播接收器所在的包名,此广播将只会发送到此包中的App内与之相匹配的有效广播接收器中。(通过intent.setPackage(packageName)指定报名)(4)使用封装好的LocalBroadcastManager类 |
注册方式
| 静态注册 | 动态注册 | |
|---|---|---|
| 使用 | 在AndroidManifest中通过标签声明,应用首次启动后,系统会自动实例化广播接收器实例并注册到广播系统中。 | 在代码中调用Context.registerReceiver()方法完成注册。 |
| 特点 | 广播常驻后台,不会随着其他组件的消亡而变化,当应用程序关闭后,如果有广播,应用程序仍会被系统调用。这样的话不仅占用内存,而且会增加应用的耗电量。 | 广播非常驻后台,生命周期灵活可控。注册和注销的过程需要开发者自己手动完成。为了避免内存泄漏,当广播不再使用时,开发者需要手动注销广播。 |
| 场景 | 适用于需要时刻监听广播的场景 | 需要特定时刻监听广播 |
使用方式:发送\接受\屏蔽 广播
- 发送广播
开发者自定义intent广播并发送
1 | Intent intent = new Intent(); |
- 接收广播
- 静态/动态注册广播接收器
静态注册——在AndroidManifest.xml里通过标签声明
1 | //此广播接收者类是mBroadcastReceiver |
通过过滤器匹配自定义广播:对于自定义广播接收者中注册时intentFilter的action与上述匹配,则会接收此广播(即进行回调onReceive())。如下mBroadcastReceiver则会接收对应action广播
1 | //此广播接收者类是mBroadcastReceiver |
动态注册——在代码中调用Context.registerReceiver()方法
1 | // 选择在Activity生命周期方法中的onResume()中注册 |
在onResume()注册、onPause()注销是因为onPause()在App死亡前一定会被执行,从而保证广播在App死亡前一定会被注销,从而防止内存泄露。
不在onCreate() & onDestory() 或 onStart() & onStop()注册、注销是因为:
当系统因为内存不足(优先级更高的应用需要内存,请看上图红框)要回收Activity占用的资源时,Activity在执行完onPause()方法后就会被销毁,有些生命周期方法onStop(),onDestory()就不会执行。当再回到此Activity时,是从onCreate方法开始执行。
假设我们将广播的注销放在onStop(),onDestory()方法里的话,有可能在Activity被销毁后还未执行onStop(),onDestory()方法,即广播仍还未注销,从而导致内存泄露。
但是,onPause()一定会被执行,从而保证了广播在App死亡前一定会被注销,从而防止内存泄露。
- 自定义广播接收者BroadcastReceiver
1 | // 继承BroadcastReceivre基类 |
- 屏蔽广播
- 注册广播时将exported属性设置为false,使得非本App内部发出的此广播不被接收;
- 在广播发送和接收时,增设相应权限permission,用于权限验证,只用具有相应权限的广播发送者发送的广播才能被该BoardcastReceiver接收;
1 | <receiver |
发送广播时指定权限
1 | // 发送广播,第二个参数标识接收消息的广播接收器需要BROADCAST_PERMISSION_DISC权限 |
- 发送广播时指定该广播接收器所在的包名,此广播将只会发送到此包中的App内与之相匹配的有效广播接收器中。
1 | // 发送广播时指定包名 |
- 使用封装好的LocalBroadcastManager类(本地广播发送的广播只在自身app传播)
App应用内广播可理解为一种局部广播,广播的发送者和接收者都同属于一个App。相比于全局广播(普通广播),App应用内广播优势体现在:安全性高 & 效率高(仅根据intent-filter过滤广播可能会造成隐私数据泄露等)
使用方式上与全局广播几乎相同,只是注册/取消注册广播接收器和发送广播时将参数的context变成了LocalBroadcastManager的单一实例
1 | //注册应用内广播接收器 |
Context
理解 & 作用
Android应用模型是基于组件的应用设计模式,组件的运行要有一个完整的Android工程环境,(与Java不同,不能单单靠new出来对象就能运行)Context是维持Android程序中各组件(Activity、Service等)能够正常工作的一个核心功能类。
Context:语境、上下文。提供了关于应用环境全局信息的接口。我们可以通过这个接口获取 应用程序的资源和类 以及 进行应用级别的操作。如:启动Activity,弹出对话框,启动服务,发送广播,加载资源等等。
分类
Context 继承关系
Context是一个抽象类,它的具体实现类是ContextImpl,ContextWrapper是包装类。Activity,Application,Service都是继承自ContextWrapper,其初始化的过程中都会创建一个具体的ContextImpl实例,由ContextImpl实现Context中的方法。
ContextThemeWrapper继承自ContextWrapper,相对于ContextWrapper添加了与主题相关的接口。Application与Service直接继承自ContextWrapper,Activity直接继承自ContextThemeWrapper。
这里所说的主题就是指在AndroidManifest.xml中通过android:theme为Application元素或者Activity元素指定的主题。
当然,只有Activity才需要主题,Service是不需要主题的,因为Service是没有界面的后台场景,所以Service直接继承于ContextWrapper,Application同理。
因此对于一个应用程序,Context数量 = Activity数量 + Service数量 + 1(Application数量)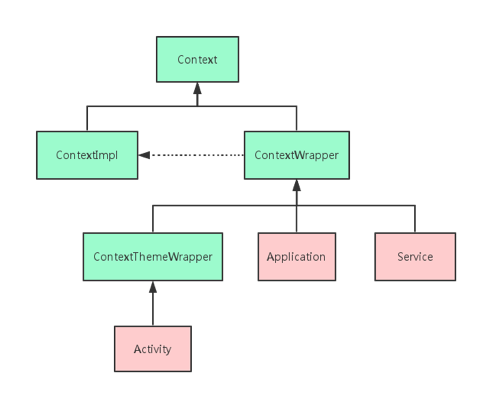
Context 作用域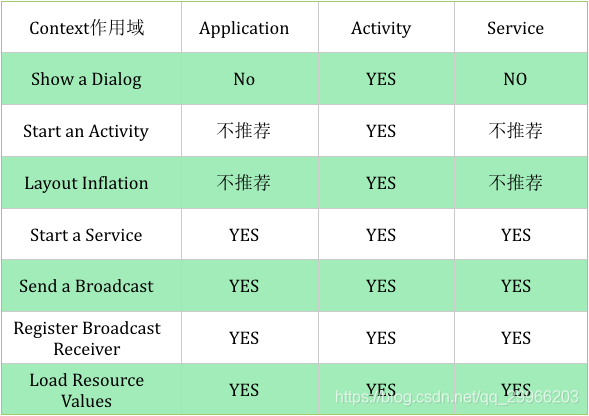
Appliation/Service 不推荐使用的两种情况:
- 如果我们用ApplicationContext去启动一个LaunchMode为standard的Activity的时候会报错android.util.AndroidRuntimeException: Calling startActivity from outside of an Activity context requires the FLAG_ACTIVITY_NEW_TASK flag. Is this really what you want?
这是因为非Activity类型的Context并没有所谓的任务栈,所以待启动的Activity就找不到栈了。解决这个问题的方法就是为待启动的Activity指定FLAG_ACTIVITY_NEW_TASK标记位,这样启动的时候就为它创建一个新的任务栈,而此时Activity是以singleTask模式启动的。所有这种用Application启动Activity的方式不推荐使用,Service同Application。 - 在Application和Service中去layout inflate也是合法的,但是会使用系统默认的主题样式,如果你自定义了某些样式可能不会被使用。所以这种方式也不推荐使用。
凡是跟UI相关的,都应该使用Activity做为Context来处理;其他的一些操作,Service,Activity,Application等实例都可以,当然了,注意Context引用的持有,防止内存泄漏。
不同种类Context的区别
| Context类型 | Activity Context | Application(Service) Context |
|---|---|---|
| 父类不同 | ContextThemeWrapper(Activity相对于Application增加了UI界面的处理,如弹出Dialog) | ContextWrapper |
| 数量不同 | 多个(Activity Context则随Activity启动而创建) | 一个(Application Context随Application启动而创建) |
| 生命周期不同 | 与Activity相关.故对于生命周期较长的对象应引用Application的Context防止内存泄露。 | 与Application相关,随应用程序销毁而销毁 |
| 作用域不同 | Activity所持用的Context作用域最广,无所不能(继承自ContextThemeWrapper,在ContextWrapper基础上增加了主题操作) | 不适用于UI相关的操作,如Start an Activity或Layout Inflate |
| 获取方式不同 | View.getContext()/Activity.this | Activity.getApplicationContext() |
内存泄露
- 引起内存泄露的原因
(1)错误的单例模式
1 | public class Singleton { |
这是一个非线程安全的单例模式,instance作为静态对象,其生命周期要长于普通的对象,其中也包含Activity,假如Activity A去getInstance获得instance对象,传入this,常驻内存的Singleton保存了你传入的Activity A对象,并一直持有,即使Activity被销毁掉,但因为它的引用还存在于一个Singleton中,就不可能被GC掉,这样就导致了内存泄漏。
(2)View持有Activity引用
1 | public class MainActivity extends Activity { |
有一个静态的Drawable对象,当ImageView设置这个Drawable时,ImageView保存了mDrawable的引用,而ImageView传入的this是MainActivity的mContext,因为被static修饰的mDrawable是常驻内存的,MainActivity是它的间接引用,MainActivity被销毁时,也不能被GC掉,所以造成内存泄漏。
- 正确使用Context
一般Context造成的内存泄漏,几乎都是当Context销毁的时候,却因为被引用导致销毁失败,而Application的Context对象可以理解为随着进程存在的,所以我们总结出使用Context的正确姿势:
- 当Application的Context能搞定的情况下,并且生命周期长的对象,优先使用Application的Context。
- 不要让生命周期长于Activity的对象持有到Activity的引用。
- 尽量不要在Activity中使用非静态内部类,因为非静态内部类会隐式持有外部类实例的引用,如果使用静态内部类,将外部实例引用作为弱引用持有。
Intent
Intent表示目的、意图。Android通过Intent协助应用间,或应用内部组件(Activity,Service和Broadcast Receiver)间交互与通讯。用户可以通过Intent向Android组件发出一个意图,Intent负责对这个意图的动作、附加数据等进行描述。Android根据Intent的描述找到对应的组件,将Intent传入并完成组件的调用。
Intent作用主要包括2个
指定当前组件要完成的动作
根据intent寻找目标组件的方式分成两类
- 隐式意图
通过在指定需启动组件所需满足的条件
(1)在AndroidManifest.xml清单文件中配置启动目标组件的条件
通过 AndroidManifest.xml文件下的<组件类型>(如< Activity >< Service > < BroadcastReceiver >)标签下的< intent -filter > 声明 需 匹配的条件,声明条件含:动作(Action)、类型(Category)、数据(Data)
1 | // 为使SecondActivity能继续响应该Intent |
(2)在Activity中发起意图
1 | // 使FirstActivity启动SecondActivity(通过按钮) |
- 显式意图
通过明确指定组件名
明确指定组件名的方式:调用Intent的构造方法、Intent.setComponent()、Intent.setClass()
通过 AndroidManifest.xml文件下的<组件类型 android:name=“组件名”>
1 | // 使FirstActivity启动SecondActivity(通过按钮) |
Intent 构造方法
1、Intent() 空构造函数
2、Intent(Intent o) 拷贝构造函数
3、Intent(String action) 指定action类型的构造函数
4、Intent(String action, Uri uri) 指定Action类型和Uri的构造函数,URI主要是结合程序之间的数据共享ContentProvider
5、Intent(Context packageContext, Class cls) 传入组件的构造函数,也就是上文提到的 6、Intent(String action, Uri uri, Context packageContext, Class cls) 前两种结合体
通常开启自定义组件使用显式意图,开启系统应用时使用隐式意图。
- Intent 常见使用场景
- 启动页面(Context.startActivity() 、Activity.startActivityForResult())
(1)启动系统Activity
1 | 显示网页 |
(2)启动自定义Activity
1 | Intent it = new Intent(Activity.Main.this, Activity2.class); |
- 启动服务( Context.startService() 、Context.bindService() )
1 | //构建启动服务的Intent对象 |
- 启动广播( Context.sendBroadcast()、Context.sendOrderedBroadcast())
1 | public class mBroadcastReceiver extends BroadcastReceiver { |
(1)监听系统广播
- 静态注册
1 | <receiver |
- 动态注册
1 |
|
(2)发送 & 监听自定义广播
即开发者自身定义intent的广播(最常用)。发送广播使用如下:
1 | Intent intent = new Intent(); |
若被注册了的广播接收者中注册时intentFilter的action与上述匹配,则会接收此广播(即进行回调onReceive())。如下mBroadcastReceiver则会接收上述广播
1 | <receiver |
传递数据
Intent可传递的数据类型有3种
- java的8种基本数据类型(boolean byte char short int long float double)、String以及他们的数组形式;
1 | // 目的:将FristActivity中的一个字符串传递到SecondActivity中,并在SecondActivity中将Intent对象中的数据(FristActivity传递过来的数据)取出 |
- Bundle类,Bundle是一个以键值对的形式存储可传输数据的容器;
1 | // 1. 数据传递 |
- 实现了Serializable和Parcelable接口的对象,这些对象实现了序列化。
Serializable
1 | public class User implements Serializable { |
Parcelable
1 | public class User implements Parcelable { |
Application
Application代表应用程序,属于Android的一个系统组件。
Application特点
- 单例模式
即每个App运行时,系统会自动创建并实例化Application对象,且应用程序中有且仅有一个Application对象。 - 全局实例
不同的组件可以获取Application且获取的是同一个Application。 - 与App应用程序同生共死。
Application的生命周期等于App的生命周期,与App同生共死。
Application获取方式
- Context环境
1 | application = (MyApplication)getApplicationContext(); //方法1 |
- 非Context环境——单例模式(饿汉式)
1 | public class MyApplication extends Application { |
Application应用场景
| 应用场景 | 调用生命周期方法 |
|---|---|
| 初始化资源,WebView预加载,推送服务注册,第三方插件加载等 | onCreate() |
| 数据共享、数据缓存(设置全局共享变量、方法) | onCreate() |
| 获取应用程序当前内存使用情况(及时释放资源,避免被系统杀死/提高应用程序性能) | onTrimMemory() & onLowMemory |
| 监听 应用程序 配置信息的改变 | onConfigurationChanged() |
| 监听应用程序内 所有Activity的生命周期 | registerActivityLifecycleCallbacks() & unregisterActivityLifecycleCallbacks() |
第二章 Fragment
- 理解 & “第五组件”
- 生命周期
- 使用方式 / Fragment加载到Activity的两种方式
- 切换方式
- 懒加载(结合 ViewPager)
- Fragment 回退栈(结合replace)
- Fragment 与 Activity 通信方式
- 遇见的坑
理解 & “第五组件”
Fragment,碎片。作为Activity界面的一部分,可理解为模块化Activity。是为了解决屏幕适配问题及UI界面的灵活控制而设计的。
Fragment不能独立存在,必须嵌入到Activity中。
Fragment比Activity更节省内存,拥有自己的生命周期,并且可以接收并处理事件。
Fragment使用频率很高,完全不低于其余四大组件。可以被称为第五大组件。
生命周期
- Fragment 完整生命周期流程
Fragment依赖Activity的存在而存在,Activity的状态决定了Fragment可能接收到的回调函数,故在Activity生命周期中的方法一般与Fragment生命周期中的方法同步执行(且Activity通常先于Fragment执行)。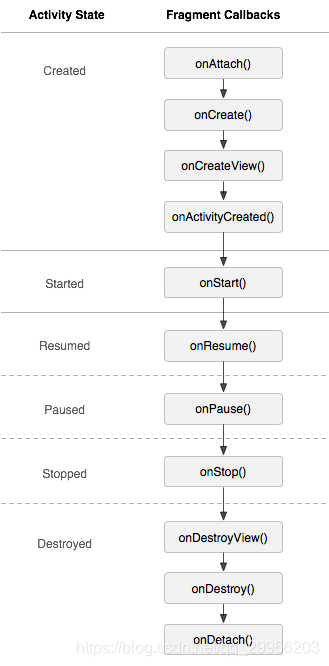
Fragment比Activity多了几个生命周期的回调方法
onAttach(Activity) 当Fragment与Activity发生关联的时候调用
onCreateView(LayoutInflater, ViewGroup, Bundle) 创建该Fragment的视图
onActivityCreated(Bundle) 当Activity的onCreated方法返回时调用
onDestroyView() 与onCreateView方法相对应,当该Fragment的视图被移除时调用
onDetach() 与onAttach方法相对应,当Fragment与Activity取消关联时调用 - Fragment切换生命周期变化
- 通过add、hide、show切换Fragment
切换时不执行Fragment生命周期,调用onHiddenChanged方法 - 通过replace切换Fragment
切换时,Fragment都进行了销毁,重建的过程。相当于执行了一次生命周期 - 通过ViewPager切换Fragment
切换时不执行生命周期,调用setUserVisVleHint方法
使用方式 / Fragment加载到Activity的两种方式
Fragment加载到Activity分为动态加载与静态加载两种方式:
- 静态加载
指在Activity布局文件中加载Fragment,使用指定属性name即可。
(1)创建一个类继承Fragment,重写onCreateView方法,来确定Fragment要显示的布局
1 | public class MyFragment extends Fragment { |
(2)在Activity中声明该类,与普通的View对象一样
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
- 动态加载
指在Activity的java文件中加载Fragment,需要使用FragmentManager,通过FragmentManager获取FragmentTransaction动态添加Fragment。
Activity 布局文件
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
MainActivity.java
1 | public class MainActivity extends AppCompatActivity { |
切换方式
FragmentTransaction对象,transaction的方法主要有以下几种:
| 方法 | 解释 |
|---|---|
| add | 向Activity中添加一个Fragment |
| remove | 从Activity中移除一个Fragment,如果被移除的Fragment没有添加到回退栈,这个Fragment实例将会被销毁 |
| replace | 使用另一个Fragment替换当前的,实际上就是remove()然后add()的合体 |
| hide | 隐藏当前的Fragment,仅仅是设为不可见,并不会销毁 |
| show | 显示之前隐藏的Fragment |
| commit | 提交事务,在add/replace/hide/show以后都要commit其效果才会在屏幕上显示出来 |
Fragment主要有3种界面切换方式:
MainActivity 布局文件(通过FrameLayout 显示fragment)
1 | <?xml version="1.0" encoding="utf-8"?> |
Fragment 实现逻辑代码
1 | public class MyFragment extends Fragment { |
MainActivity.java
1 | public class MainActivity extends AppCompatActivity implements View.OnClickListener{ |
- 方式1:add/show/hide
初始化时通过add加入Fragment,hide&show方式切换Fragment时将Fragment视图隐藏,所有的Fragment实例都会保存在内存,不会销毁与重建,不执行生命周期。
点击fragment文字改变后,切换到其他fragment并返回时,文字保持点击后改变的文字,而不是初始化的文字。即fragment没有重建,保持之前的fragment。

- 方式2:replace(+addToBackStack)
通过 replace 方法进行替换的时,Fragment 都是进行了销毁,重建的过程,相当于走了一整套的生命周期。
fragment1:onPause() -> onStop -> onDestroyView() -> onDestroy() -> onDetach()
fragment2:onAttach() -> onCreate() -> onCreateView() -> onActivityCreated() -> on Start() -> onResume()
点击fragment文字改变后,切换到其他fragment并返回时,文字恢复为初始化的文字。即fragment重新创建并初始化。
- 方式3:Fragment与ViewPager的搭配使用
通常情况下我们开发应用最常见的使用情况是TabLayout+ViewPager+Fragment的使用方式,下面通过一个实例展示:
- 步骤1:引入工具包
1 | implementation 'com.android.support:design:27.1.1' |
- 步骤2:书写布局文件
1 | <?xml version="1.0" encoding="utf-8"?> |
- 步骤3:实现TabLayout+ViewPager+Fragment
使用流程:
1、创建存储多个Fragment实例的列表
2、创建PagerAdapter实例并关联到Viewpager中
3、将ViewPager关联到Tablayout中
4、根据需求改写Tablayout属性
1 | public class TabLayoutActivity extends AppCompatActivity implements MyFragment.OnFragmentInteractionListener { |
- FragmentStatePagerAdapter与FragmentPagerAdapter
FragmentStatePagerAdapter与FragmentPagerAdapter用法类似,区别在于,卸载不需要的Fragment时,各自的处理方法不同。
| Adapter | FragmentStatePagerAdapter | FragmentPagerAdapter |
|---|---|---|
| 切换方式 | 会销毁不需要的Fragment,事务提交后,FragmentManager中的Fragment会被彻底移除,销毁时可在onSaveInstanceState方法中保存信息 | 对于不再需要的Fragment会调用事务的detach方法而非remove方法,仅仅是销毁Fragment的视图,而实例对象仍然保留 |
| 适用场景 | 更节省内存,当page页面较多时适合使用 | 界面只是少量固定页面,FragmentPagerAdapter更安全 |
ViewPager + Fragment结合使用会出现内存泄漏吗 & 如何解决?
- 原因:
一般ViewPager + Fragment结合使用出现内存泄漏的原因可能用某个集合存储了Fragment的实例,导致当用户滑动ViewPager的时候,某一个Fragment即将面临销毁的时候,由于这个集合持有的它的引用,因此不能被回收掉,如果Fragment里面有大量的数据占据内存,有可能会导致OOM。 - 解决方法:
尽量不要使用集合来存储Fragment实例对象,除非你有良好的二次封装。再就是要做好每一页Fragment的数据缓存问题。
懒加载(结合 ViewPager)
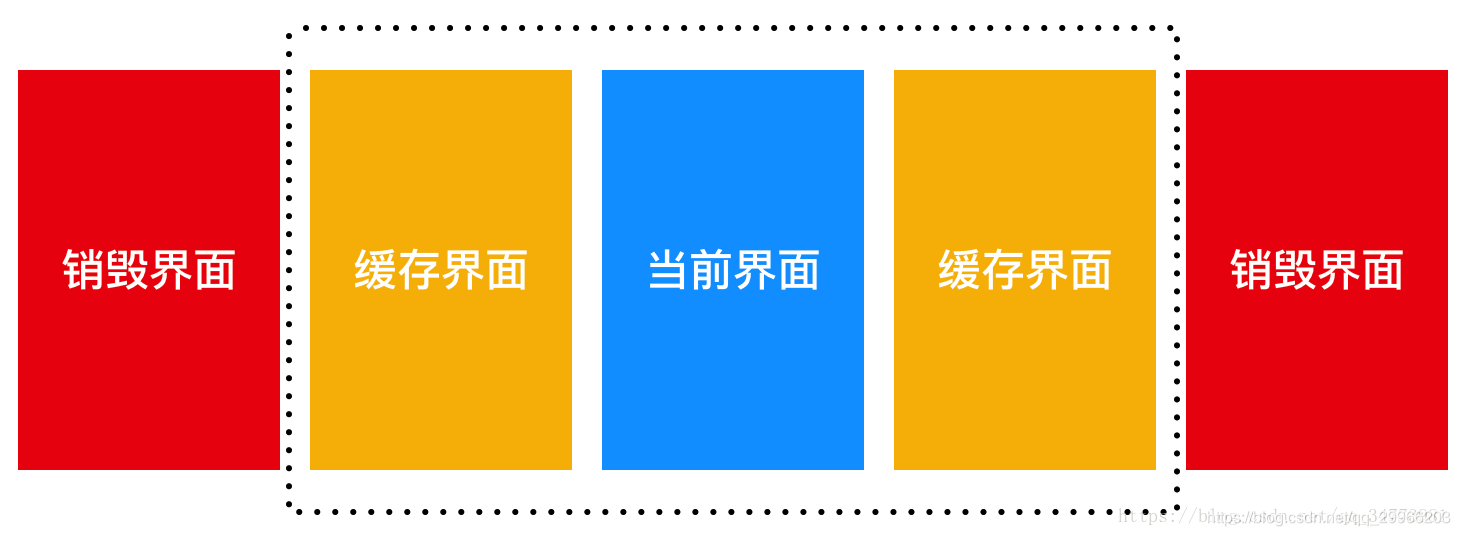
- ViewPager的缓存机制 —— 预加载
ViewPager为了让滑动的时候可以有很好的用户的体验,也就是防止出现卡顿现象,因此它有一个缓存机制。默认情况下,ViewPager会提前创建好当前Fragment旁的两个Fragment,举个例子说也就是如果你当前显示的是编号3的Fragment,那么其实编号2和4的Fragment也已经创建好了,也就是说这3个Fragment都已经执行完 onAttach() -> onResume() 这之间的生命周期函数了。
也可以通过下述函数设置缓存的页面数目:
1 | viewPager.setOffscreenPageLimit(int limit); |
- 为什么要懒加载?
Android的View绘制流程是最消耗CPU时间片的操作,尤其是在ViewPager+Fragment的情况下,会对所有的Fragment进行预加载。如果在View绘建的同时还进行多个Fragment的数据加载,那用户体验简直是爆炸(不仅浪费流量,而且还造成不必要的卡顿)因此,需要对Fragment们进行懒加载策略。 - 什么是懒加载?
被动加载,当Fragment页面可见时,才从网络加载数据并显示出来。 - 如何懒加载?
实行懒加载必须满足的条件
- View视图加载完毕,即onCreateView()执行完成
(setUserVisibleHint函数是游离在Fragment生命周期之外的,它的执行有可能早于onCreate和onCreateView,然而既然要时间数据的加载,就必须要在onCreateView创建完视图过后才能使用,不然就会返回空指针崩溃)
- 当前Fragment可见,即setUserVisibleHint()的参数为true
- 初次加载,即防止多次滑动重复加载
故在Fragment全局变量中增加对应的三个标志参数并设置初始值
1 | boolean mIsPrepare = false; //是否加载完成 => onCreateView |
当然在onCreateView中确保了View已经准备好时,将mPrepare置为true,在setUserVisibleHint中确保了当前可见时,mIsVisible置为true,第一次加载完毕后则将mIsFirstLoad置为false,避免重复加载。
1 |
|
最后,贴上懒加载的lazyLoad()代码(只要标志位改变,就要进行lazyLoad()函数的操作)
1 | private void lazyLoad() { |
最后,如果Fragment销毁的话,还应该将三个标志位进行默认值初始化:
1 |
|
为什么在onDestroyView中进行而不是在onDestroy中进行呢?这又要提到之前Adapter的差异,onDestroy并不一定会调用。
Fragment 回退栈(结合replace)
Fragment的回退栈是用来保存每一次Fragment事务发生的变化。在Fragment的时候,如果你不是手动开启回退栈,若用replace方式切换时,是直接销毁再重建;但如果将Fragment任务添加到回退栈,情况就会不一样了,它就有了类似Activity的栈管理方式。
1 | // Fragment1.java |
Fragment的点击事件里写的是replace方法,相当于remove和add的合体,并且如果不添加事务到回退栈,前一个Fragment实例会被销毁。
这里很明显,我们调用tx.addToBackStack(null)将当前的事务添加到了回退栈,所以FragmentOne实例不会被销毁,但是视图层次依然会被销毁,即会调用onDestoryView和onCreateView(但不会调用onDestroy()和onCreate())。
所以【请注意】,当之后我们从FragmentTwo返回到前一个页面的时候,视图层仍旧是重新按照代码绘制,这里仅仅是是实例没有销毁。
Fragment 与 Activity 通信方式
- 直接访问引用
如果你Activity中包含自己管理的Fragment的引用,可以通过引用直接访问所有的Fragment的public方法 - Activity向Fragment通信——FindFragmentById
若Fragment存在,则可通过getSupportFragmentManager().findFragmentById直接获得Fragment,调用它的共有方法获得数据。否则可通过setArguments(bundle)/getArguments方法传递bundle参数
MainActivity.java
1 | public static class MainActivity extends Activity { |
MyFragment.java
1 | public class MyFragment extends Fragment { |
- Fragment向Activity通信——回调函数
在Fragment内定义回调函数,并在Activity中实现回调接口,可实现Fragment向Activity传递数据
step1: 在Menuragment中创建一个接口以及接口对应的set方法:
1 | //MenuFragment.java文件中 |
step2: 在MenuFragment中的ListView条目点击事件中进行接口进行接口回调:
1 | //MenuFragment.java文件中 |
step3: 在MainActivity中根据menuFragment获取到接口的set方法,在这个方法中进行进行数据传递,具体如下:
1 | //在MainActivity.java中 |
- 第三方开源框架:EventBus
- Fragment之间通信——以宿主Activity为桥梁
综合上面两步,可得到Fragment之间的通信方式:
Fragment1通过getActivity获得宿主Activity,并通过Activity实例直接调用FindFragmentById获得Fragment2,并传递数据给Fragment2
遇见的坑
- getActivity空指针
调用getActivity时,当前Fragment已经onDetach宿主Activity,导致空指针异常。常见页面重启(因内存不足/按Home键/横竖屏切换)或pop了Fragment后,由于Fragment的异步任务仍执行,且执行时调用了getActivity方法,会报空指针异常。
应该在Fragment的基类设置一个宿主Activity的全局变量,并在onAttach赋值,使用该全局变量代替getActivity。保证Fragment在被onDetach后,仍有Activity的引用。 - 内存泄露
用集合保存Fragment数组时,销毁Fragment会因为集合中仍存在Fragment的引用而无法销毁,引起内存泄露。常见于ViewPager的使用。 - Can not perform this action after onSaveInstanceState异常
Activity在调用onSaveInstanceState()保存当前Activity的状态后,直到Activity状态恢复之前,若commit 一个FragmentTransaction,就会抛出该异常。因为onSaveInstanceState用于保存当前Activity的现场状态,若之后再调用FragmentTransaction.commit,则该事务没有被作为Activity的状态保存,导致意外的UI状态丢失。Android系统为了避免页面状态的丢失,抛出异常。
为了解决这个异常,应该谨慎地在Activity生命周期调用transaction的commit方法。确保在Activity状态恢复后才会调用。且避免在异步回调中处理transaction。使用commitAllowingStateLoss()虽然可以避免跑出异常,但是存在状态丢失的可能性。 - Fragment界面重叠
当使用add方式添加Fragment并使用hide|show切换时,如果发生页面重启,可能会导致Fragment重叠。这是因为Activity使用onSaveInstanceState方法时,系统保存了Fragment状态。在重启时,FragmentManager会从栈底向栈顶的顺序一次性恢复Fragment,但没有保存Fragment的mHidden属性,使所有的Fragment都以show的形式恢复,导致页面发生重叠。
故应该在创建时,判断savedInstanceState不为空时,通过findFragmentByTag找到对应的Fragment,show需要显示的项目并hide隐藏的项目。
第三章 存储
- 数据持久化 / 数据本地存储方式
- SharedPreferences
- 文件存储
- SQLite
数据持久化 / 数据本地存储方式
Android本地存储方式有5种,分别是SharedPreferences存储、文件存储、SQLite存储、ContentProvider和网络存储方式。
| 存储方式 | 简介 | 特点 | 默认存储路径 | 项目应用 |
|---|---|---|---|---|
| SharedPreferences | SharedPreferences是一种轻量级存储类,数据存储格式为键值对 | 保存一些简单的配置参数等轻量级数据 | /data/data/packageName/shared_prefs/xxx.xml | 登录界面保存上次登录成功的用户名和密码 |
| 文件存储 | 文件存储是通过I/O流从内部存储或SD卡(外存)中读写数据 | 内存中存储一些较小、安全性较高的数据 外存存储较大的文件或简单的文本/二进制数据 |
/data/data/packageName/files | 项目所需图片、音频文件 较大的数据信息(.json/.xml) |
| SQLite | 通过SQLite,一种轻型、嵌入式的ACID关系型数据库对数据存储,使用SQL语言 Android为此数据库提供了SQLiteDatabase类,封装了操作数据库的API |
数据量不是很大且逻辑关系较为复杂的数据(结构性数据) | /data/data/packageName/databases | 存储本地数据信息(结构性数据) |
| ContentProvider | 作为Android四大组件之一,ContentProvider一般为存储和获取数据提供统一的接口,可以在不同的应用程序之间共享数据 仅作为传输数据的媒介,数据源具有多样性 |
Android手机系统数据 跨进程数据 |
通过URI对象 | 获取手机短信、联系人等 进程间数据共享、交换 |
| 网络存储 | 与后台交互,将数据存储在后台数据库中 | 数据量大,逻辑关系复杂的数据交给后台处理 | 远程服务器 | 庞大的数据库 较大的音频、图片 |
SharedPreferences
- 简介
SharedPreferences是Android平台上一个轻量级的存储类,主要是保存一些常用的配置比如窗口状态。是Android最简单数据存储方式。
- 只支持Java基本数据类型 & String类型数据存储
如果要用 SharedPreferences 存取复杂的数据类型(类,图像等),就需要对这些数据进行编码。通常会将复杂类型的数据转换成Base64编码,然后将转换后的数据以字符串的形式保存在XML文件中。 - 数据存储类型为key-value对。
- 使用SharedPreferences保存数据,其背后是用xml文件存放数据,文件 存放在/data/data/ < package name > /shared_prefs目录下。
- 是一种轻量级存储类,常用于保存一些常用的配置比如窗口状态。之所以说SharedPreference是一种轻量级的存储方式,是因为它在创建的时候会把存储数据的整个xml文件全部加载进内存。
- SharedPreferences读取数据都使用awaitLoadedLocked同步锁,故是线程安全的。
- SharedPreferences一般采用单例模式
- 使用
存储数据
1 | //获取一个文件名为test、权限为private的xml文件的SharedPreferences对象 |
获取数据
1 | et_username = (EditText) findViewById(R.id.et_username); |
- 性能优化
SharedPreferences是Android平台上一个轻量级的存储类,主要是保存一些常用的配置比如窗口状态。本质是通过存放在/data/data//shared_prefs目录下xml文件存放数据。由于创建时候会把整个xml文件全部加载进内存,故若SharedPreference文件比较大,会带来如下问题:
- 第一次从sp中获取值时,可能会阻塞主线程,使界面卡顿、掉帧。
- 解析sp时会产生大量临时对象,导致频繁GC,引起界面卡顿
- 这些存储的键值对会永远存储在内存中,不会释放,若存取较大的数据则十分消耗内存。
故优化建议如下: - 不要存放大的数据,不相关的配置项不要放在一起。
- 频繁读取的key和不宜变动的key不要放在一起,影响读写速度。
- 不要多次apply和edit,尽量批量修改一次提交。多次apply会阻塞主线程(引起ANR)。
SP 调用 apply 方法,会创建一个等待锁mcr.writtenToDiskLatch.await()放到 QueuedWork 中,并将真正数据持久化封装成一个任务放到异步队列中执行,任务执行结束会释放锁。
Activity onStop 以及 Service 处理 onStop,onStartCommand 时,执行 QueuedWork.waitToFinish() 等待所有的等待锁释放。
- 尽量不要存放JSON和HTML。直接使用JSON配置文件。
- 不应使用SharedPreference进行跨进程通信(一般用ContentProvider。)
文件存储
- 内部存储(Internal Storage)
- 简介
- 位于/data/data/< package-name >/目录下的文件
- 依附于应用,位于和应用包名相同的目录下,只能被应用内部读写,且当应用卸载后,内部存储的文件也被删除。
- 内部存储控件有限,且存放系统本身和系统应用程序数据,包括SharedPreferences和SQLite数据库。
- 适用于存储体积小且安全性高的文件信息(内部存储一般用于系统存储APP专属文件)
- 存储路径 & 获取方式
| 方法 | 路径 | 解释 |
|---|---|---|
| getFilesDir() | /data/data/package-name/files | 返回应用内部存放文件的目录的绝对路径。 |
| getCacheDir() | /data/data/package-name/cache | 返回应用内部存储的临时目录。系统内部存储即将耗尽的时候,可能会删除这个目录下的文件。 |
| getDir(String name, int mode) | /data/data/package-name/name | 可用于在应用内部存储根目录下创建或打开自定义的文件目录。name表示自定义的文件目录名。mode表示操作模式,用来控制该目录的读写权限,默认为MODE_PRIVATE,表示仅仅应用自身可以访问。 |
附:/data/user/0/packname/目录(系统创建App专属文件):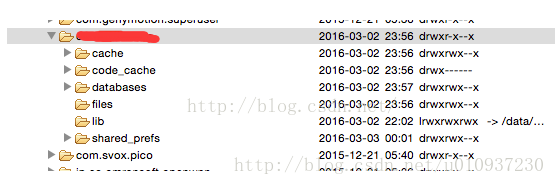
cache下存放缓存数据,databases下存放使用SQLite存储的数据,files下存放普通数据(log数据,json型数据等),shared_prefs下存放使用SharedPreference存放的数据。这些文件夹都是由系统创建的。
- 存储方式
1 | public static void writeInternal(String fileName, String content) throws IOException { |
- 外部存储(External Storage)
- 简介
- 位于/storage目录下的文件
- 4.4系统及以上的手机的外部存储分为机身存储(/storage/emulated/) & SD卡(/storage/sdcard/)两部分。(SD卡属于USB存储设备的形式装载外部存储,可拆卸)
1 | if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) { |
- 不依附于应用。外部存储的文件可以被全局访问,且用户卸载应用时,系统只卸载通过调用getExternalFilesDir()获取的目录里的文件(/storage/emulated/0/Android/data/packagename/files)。
- 适用于存放希望被其他应用共享的及被用户访问的文件(外部存储一般用于开发人员存储APP专属文件)
- 存储路径 & 获取方式
| 方法 | 路径 | 解释 |
|---|---|---|
| Environment.getExternalStoragePublicDirectory(Environment.Type) Environment.getExternalStorageDirectory(Environment.Type) |
/storage/emulated/0 | 获取外部存储的公共文件路径 |
| getExternalFilesDir(Environment.Type) | /storage/emulated/0/Android/data/package-name/files | 获取某个应用在外部存储的私有文件路径 |
| getExternalCacheDir() | /storage/emulated/0/Android/data/package-name/cache | 获取某个应用在外部存储的cache路径 |
其中,Environment的Type参数有:
| Environment的Type参数 | 对应模拟路径 | 解释说明 |
|---|---|---|
| DIRECTORY_DCIM | /storage/emulated/0/DCIM | 相册 |
| DIRECTORY_DOCUMENTS | /storage/emulated/0/Documents | 文件 |
| DIRECTORY_DOWNLOADS | /storage/emulated/0/Download | 下载文件 |
| DIRECTORY_MUSIC | /storage/emulated/0/Music | 音乐 |
| DIRECTORY_PICTURES | /storage/emulated/0/Pictures | 图片 |
- 存储方式
(1)获取外部存储权限
1 | <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/> |
(2)检测外部存储是否可用(外部存储可能不可用,比如用户将其挂载到了电脑或者移除了提供外部存储的SD卡)
1 | public boolean isExternalStorageWritable() { |
(3)公共文件目录的获取
公共文件目录可以通过getExternalStoragePublicDirectory()方法获取,需要指定文件类型参数,以便外部统一处理。比如DIRECTORY_MUSIC或DIRECTORY_PICTURES。比如:
1 | public File getAlbumStorageDir(String albumName) { |
应用卸载时,系统不会删除这些文件。
(4)私有文件目录的获取
调用getExternalFilesDir()方法传入目录名字获取相应目录。当用户卸载应用时候,系统会删除这些文件。
比如,使用下面方法创建个人相册目录:
1 | public File getAlbumStorageDir(Context context, String albumName) { |
上述方法会在Environment.DIRECTORY_PICTURES目录下创建albumName值的目录,当然你也可以将第一个参数传为null,则会在你应用外部存储私有目录的根目录下创建。
- 其他存储
| 路径 | 系统文件 | 缓存文件 |
|---|---|---|
| 路径 | /system | /cache |
| 获取方式 | Environment.getRootDirectory() | Environment.getDownloadCacheDirectory() |
- 案例:Android 保存网络图片到系统相册
- 确定存储路径
1、内部存储/data/data/packageName/(不采用)
一个应用对内部存储的所有访问都被限制在这个文件夹中,也就是说Android应用只能在该目录中读取,创建,修改文件。对该目录之外的其他内部存储中的目录都没有任何操作的权限。
因此,如果将图片保存在内部存储中,只能被应用自身读取,其他应用均无法读取。如果需要让系统图库,相册或其他应用能够找到保存的图片,必须将图片保存到外部存储中。
2、外部存储
(1)/storage/emulated/0/Android/data/packageName/(不采用)
这个路径会随着应用的销毁而销毁,无法长期存储在内存中。因此,也不能将图片保存在这个目录中。
(2)/storage/emulated/0/packageName/image/(采用)
除外部存储的/Android目录之外的其他目录一般都是可以被其他应用访问的。目前,大多数应用都会在外部存储的根路径下建立一个类似包名的多层目录,以存储需要共享的文件。
获取外部存储路径:由于Android系统的碎片化问题,不同设备上外部存储的路径很可能会不同,因此,不能直接使用/storage/emulated/0/作为外部存储的根路径。 Android SDK中 Environment类 提供了getExternalStorageDirectory()方法来获取外部存储的根路径。
1 | Environment.getExternalStorageDirectory().getAbsolutePath();// /storage/emulated/0 |
- 获取外部存储权限
1 | <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/> |
- 确定外部存储状态
由于外部存储需要被挂载,也可以被卸载,在写入文件之前,需要先判断外部存储的状态是否正常。只有状态正常情况下才可以执行保存文件的操作。
挂载(mounting)是指由操作系统使一个存储设备(诸如硬盘、CD-ROM或共享资源)上的计算机文件和目录可供用户通过计算机的文件系统访问的一个过程。
1 | //获取内部存储状态 |
- 确定文件名
保存的图片文件名可以由应用根据自身需要自行确定,一般来说需要有一个命名规则,然后根据命名规则计算得到文件名。 常用:
(1)时间命名
根据保存图片的当前系统时间来对图片命名。
1 | Calendar now = new GregorianCalendar(); |
(2)文件URL命名
每张网络图片都有一个对应的图片URL,可以根据图片的URL来对图片命名。
- 保存到文件中
1 | try { |
- 发送广播,通知系统扫描保存后的文件
将Bitmap对象保存成外部存储中的一个jpg格式的文件。为了让其他应用能够知道图片文件被创建,必须通知MediaProvider服务将新建的文件添加到图片数据库中。
Android系统中常驻一个MediaProvider服务,对应的进程名为android.process.media,此服务用来管理本机上的媒体文件,提供媒体管理服务。在系统开机或者收到外部存储的挂载消息后,MediaProvider会调用MediaScanner,MediaScanner会扫描外部存储中的所有文件,根据文件类型的后缀将文件信息保存到对应的数据库中,供其他APP使用。
MediaScannerReceiver是一个广播接收者,当它接收到特定的广播请求后,就会去扫描指定的文件,并根据文件信息将其添加到数据库中。当图片文件被创建后,就可以发送广播给MediaScannerReceiver,通知其扫描新建的图片文件。
1 | //保存图片后发送广播通知更新系统图库(将图片保存在系统图库) |
- 大图/多图的异步保存
保存图片文件时,如果图片很大,或需要同时保存多张图片时,就需要较多的时间。为了避免阻塞UI线程,出现帧率下降或ANR,通常需要将图片保存操作放到线程中去执行。当图片保存完毕后通过sendMessage()方法通知UI线程保存结果。 - 完整代码
1、保存Bitmap到本地指定路径下
2、通过广播,通知系统相册图库刷新数据
1 | public class ImgUtils { |
SQLite
- 简介
一种轻量级Android 内置的数据库,是遵守ACID的关联式数据库管理系统。
- 存储结构型、关系型数据,可使用SQL语言,支持事务处理。
- 轻量级。占用资源非常低(可能只有几百K内存)。
- 位于 /data/data/package-name/databases/database-name.db(内部存储,只能应用程序内部访问),Sqlite中每个数据库以单个文件形式存在,以B-Tree的形式存储在磁盘。
- Sqlite共享锁和独享锁机制,保证线程安全。
一个共享锁允许多个数据库联接在同一时刻从这个数据库文件中读取信息。“共享”锁将不允许其他联接针对此数据库进行写操作。
一个临界锁允许其他所有已经取得共享锁的进程从数据库文件中继续读取数据。但是它会阻止新的共享锁的生成。也就说,临界锁将会防止因大量连续的读操作而无法获得写入的机会。
- 使用
- 创建一个类继承SQLiteOpenHelper,复写 onCreat()、onUpgrade()
1 | public class DatabaseHelper extends SQLiteOpenHelper { |
- 创建数据库
1 | // 步骤1:创建DatabaseHelper对象(注:此时还未创建数据库) |
- 操作数据库
1 | // 插入数据 |
第四章 自定义组件、动画
- 自定义View
- Activity、PhoneWindow、DecorView、ViewRoot
- View绘制流程
- 自定义View
- View刷新/重绘机制
- View的事件分发机制
- Touch事件的传递 & 拦截机制
- 事件分发中的onTouch、onTouchEvent (和onClick) 有什么区别,又该如何使用?
- 动画
- 种类 & 特点 & 区别 &原理
- 使用
- 源码
- 问题
- 估值器
- ListView & RecycleView
- ListView 定义 & 原理 & 优化 & 封装?
- RecycleView 对比 & 应用
- PopupWindow & Dialog
- PopupWindow
- Dialog
- PopupWindow & Dialog 区别
自定义View
Activity、PhoneWindow、DecorView、ViewRoot
[Activity、PhoneWindow、DecorView、ViewRoot][Activity_PhoneWindow_DecorView_ViewRoot 1]
- Activity 控制器
Activity并不负责视图控制,它只是控制生命周期和处理事件。真正控制视图的是Window。一个Activity包含了一个Window,Window才是真正代表一个窗口。Activity就像一个控制器,统筹视图的添加与显示,以及通过其他回调方法,来与Window、以及View进行交互。 - Window 承载器
Window是视图的承载器,承载视图View的显示。内部持有一个 DecorView,而这个DecorView才是 view 的根布局。
Window是一个抽象类,实际在Activity中持有的是其子类PhoneWindow。PhoneWindow中有个内部类DecorView,通过创建DecorView来加载Activity中设置的布局R.layout.activity_main。
Window 通过WindowManager将DecorView加载其中,并将DecorView交给ViewRoot,进行视图绘制以及其他交互。
- WindowManager & WindowManagerService
[带你彻底理解 Window 和 WindowManager][Window _ WindowManager] - Window 分类
Window 有三种类型,分别是应用 Window、子 Window 和系统 Window。应用类 Window 对应一个 Acitivity,子 Window 不能单独存在,需要依附在特定的父 Window 中,比如常见的一些 Dialog 就是一个子 Window。系统 Window是需要声明权限才能创建的 Window,比如 Toast 和系统状态栏都是系统 Window。
Window 是分层的,每个 Window 都有对应的 z-ordered,层级大的会覆盖在层级小的 Window 上面,这和 HTML 中的 z-index 概念是完全一致的。在三种 Window 中,应用 Window 层级范围是 1 ~ 99,子 Window 层级范围是 1000 ~ 1999,系统 Window 层级范围是 2000 ~ 2999 - WindowManagerService
WindowManagerService 就是位于 Framework 层(Android Application层)的窗口管理服务,它的职责就是管理系统中的所有窗口。窗口的本质是什么呢?其实就是一块显示区域,在 Android 中就是绘制的画布:Surface,当一块 Surface 显示在屏幕上时,就是用户所看到的窗口了。WindowManagerService 添加一个窗口的过程,其实就是 WindowManagerService 为其分配一块 Surface 的过程,一块块的 Surface 在 WindowManagerService 的管理下有序的排列在屏幕上,Android 才得以呈现出多姿多彩的界面。于是根据对 Surface 的操作类型可以将 Android 的显示系统分为三个层次,如下图: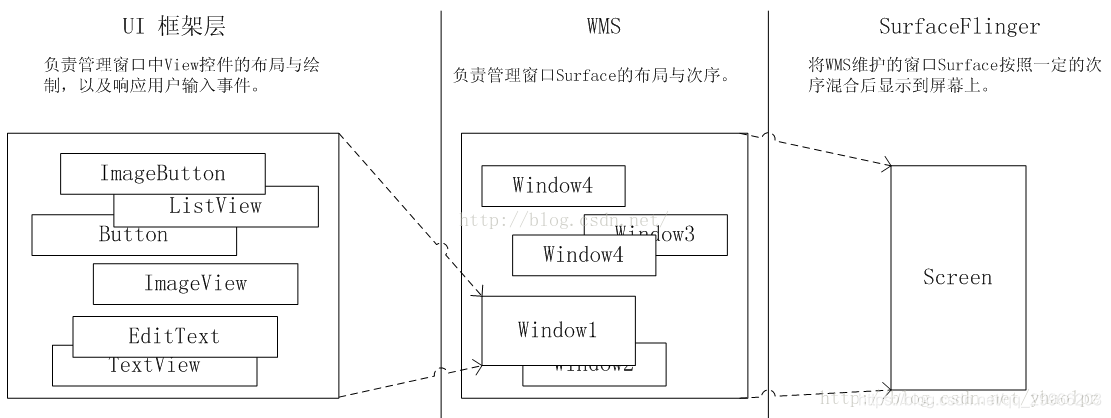
一般的开发过程中,我们操作的是 UI 框架层,对 Window 的操作通过 WindowManager 即可完成,而 WindowManagerService 作为系统级服务运行在一个单独的进程,所以 WindowManager 和 WindowManagerService 的交互是一个 IPC 过程。 - WindowManager
在实际使用中无法直接访问 Window,我们对 Window 的操作是通过 WindowManager 来完成的,WindowManager 是一个接口,它继承自只有三个方法的 ViewManager 接口:
1 | public interface ViewManager{ |
这三个方法其实就是 WindowManager 对外提供的主要功能,即添加 View、更新 View 和删除 View。WindowManager 最终都会通过一个 IPC 过程将操作移交给 WindowManagerService 这个位于 Framework 层的窗口管理服务来处理。
- DecorView 顶级View
DecorView是FrameLayout的子类,它可以被认为是Android视图树的根节点/顶级视图。用于显示 & 加载视图。它内部包含一个竖直方向的LinearLayout,在这个LinearLayout里面有两个部分:标题栏(根据Theme设置,有的布局没有),下面的是内容栏。 具体情况和Android版本及主体有关,以其中一个布局为例,如下所示:
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
在Activity中通过setContentView所设置的布局文件其实就是被加到内容栏之中的,成为其唯一子View,就是上面的id为content的FrameLayout中,在代码中可以通过content来得到对应加载的布局。
1 | ViewGroup content = (ViewGroup)findViewById(android.R.id.content); |
- ViewRoot 连接器
所有View的绘制以及事件分发等交互都是通过ViewRoot来执行或传递的。
ViewRoot对应ViewRootImpl类。它的作用包括:
(1)连接WindowManager 和 DecorView
(2)完成View的绘制流程
即ViewRoot可以与WMS交互通讯,调整窗口大小及分布;可以接收事件并向DecorView分发,Android的所有触屏事件、按键事件、界面刷新等事件都是通过ViewRoot进行分发的;可以完成View的三大绘制流程:测量、布局和绘制。 - Activity & PhoneWindow & DecorView & ViewRoot 联系
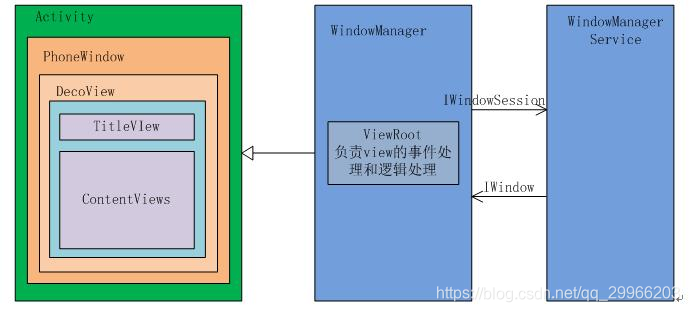
Activity就像个控制器,不负责视图部分。Window像个承载器,装着内部视图。DecorView就是个顶层视图,是所有View的最外层布局。ViewRoot像个连接器,负责沟通,通过硬件的感知来通知视图,进行用户之间的交互。 - DecorView 的创建 & 显示(View 绘制前准备)
工作流程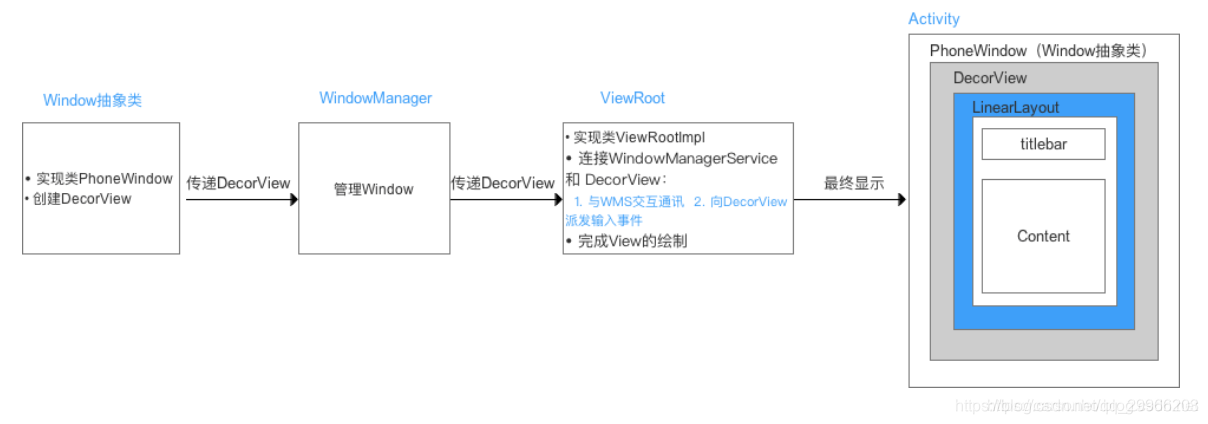
源码分析
总结:
(1) DecroView的创建
- Activity 启动时过程(attach()方法中),系统创建Window抽象子类PhoneWindow类实例对象,并为PhoneWindow类对象设置WindowManager对象
1 | mWindow = new PhoneWindow(this, window); |
- Activity 调用onCreate中通过setContentView(resId)中在PhoneWindow中创建一个DecroView类对象(初始布局根据系统主体样式),并为DecroView中content增加Activity中设置的布局文件。
1 | installDecor(); |
(2)DecroView 的显示
- 将DecroView对象添加到WindowManager
1 | wm.addView(mDecor, getWindow().getAttributes()); |
- 创建ViewRoot,WindowManager将DecroView对象交给ViewRoot。ViewRootImpl对象通过Handler向主线程发送了一条触发遍历操作的消息:performTraversals();该方法用于执行View的绘制流程(measure、layout、draw)。并将DecroView设置为可见。
1 | root = new ViewRootImpl(view.getContext(), display); |
解析:
- DecroView 的创建
这部分内容主要讲DecorView是怎么一层层嵌套在Actvity,PhoneWindow中的,以及DecorView如何加载内部布局。
(1)创建Window抽象类的子类PhoneWindow类的实例对象,为PhoneWindow类对象设置WindowManager对象
Activity启动过程(由ActivityThread 中的 performLaunchActivity() 来完成整个启动过程,在这个方法内部会通过类加载器创建 Activity 的实例对象,并调用其 attach 方法为其关联运行过程中所依赖的一系列上下文环境变量)
Activity 的 Window 创建就发生在 attach 方法里,系统会创建 Activity 所属的 Window 对象并为其设置回调接口
1 | final void attach(Context context, ActivityThread aThread, |
(2)为PhoneWindow类对象创建1个DecroView类对象,并为DecroView类对象中的contnt增加Activity中设置的布局文件
1 | /** |
- DecroView 的显示
以上仅仅是将DecorView建立起来。通过setContentView()设置的界面,为什么在onResume()之后才对用户可见呢?
(1)将DecroView对象添加到WindowManager
(2)创建ViewRoot,WindowManager将DecroView对象交给ViewRoot。ViewRootImpl对象通过Handler向主线程发送了一条触发遍历操作的消息:performTraversals();该方法用于执行View的绘制流程(measure、layout、draw)
这就要从ActivityThread开始说起。
1 | private void handleLaunchActivity(ActivityClientRecord r, Intent customIntent) { |
重点看下handleResumeActivity(),在这其中,DecorView将会显示出来,同时重要的一个角色:ViewRoot也将登场。
1 | final void handleResumeActivity(IBinder token, boolean clearHide, |
ViewRootImpl对象中接收的各种变化(如来自WmS的窗口属性变化、来自控件树的尺寸变化 & 重绘请求等都引发performTraversals()的调用 & 在其中完成处理。
而View的绘制则是在performTraversals()中执行,即View的绘制流程:measure、layout、draw
View绘制流程
View的绘制流程开始于:ViewRootImpl对象的performTraversals()
1 | /** |
从上面的performTraversals()可知:View的绘制流程从顶级View(DecorView)的ViewGroup开始,一层一层从ViewGroup至子View遍历测绘,采用递归实现
即:自上而下遍历、由父视图到子视图、每一个 ViewGroup 负责测绘它所有的子视图,而最底层的 View 会负责测绘自身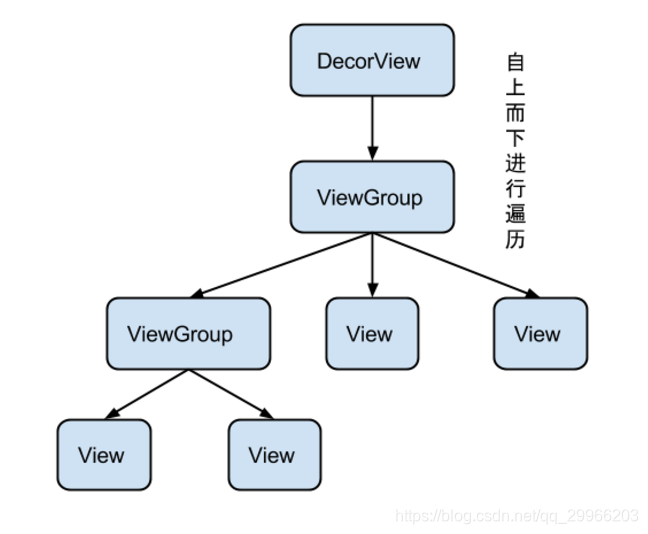
绘制的流程 = measure过程 + layout过程 + draw过程
- measure —— 测量View的宽 / 高
(1)Android 尺寸值
- ViewGroup.LayoutParams 布局参数
指定视图View 的高度(height) 和 宽度(width)等布局参数。可通过以下参数指定
| 参数 | 解释 |
|---|---|
| 具体值 | dp / px |
| match_parent | 强制性使子视图的大小扩展至与父视图大小相等(不含 padding ) |
| wrap_content | 自适应大小,强制性地使视图扩展以便显示其全部内容(含 padding ) |
- MeasureSpec 测量规格
- 描述
View大小的测量依据。
测量规格(MeasureSpec) = 测量模式(mode) + 测量大小(size) - 计算方法
子View的MeasureSpec值根据子View的布局参数(LayoutParams)和父容器的MeasureSpec值计算得来的
1 | /** |
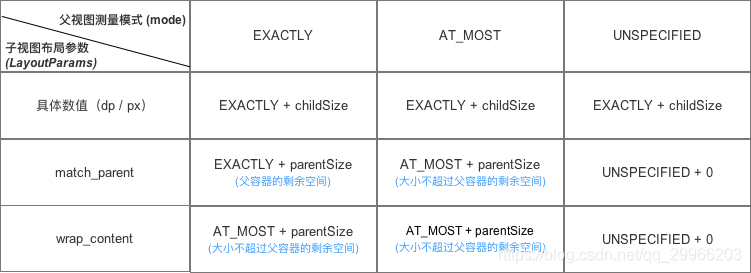
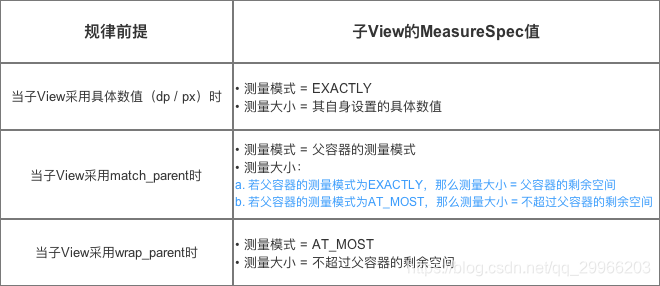
规律总结:
(2)measure流程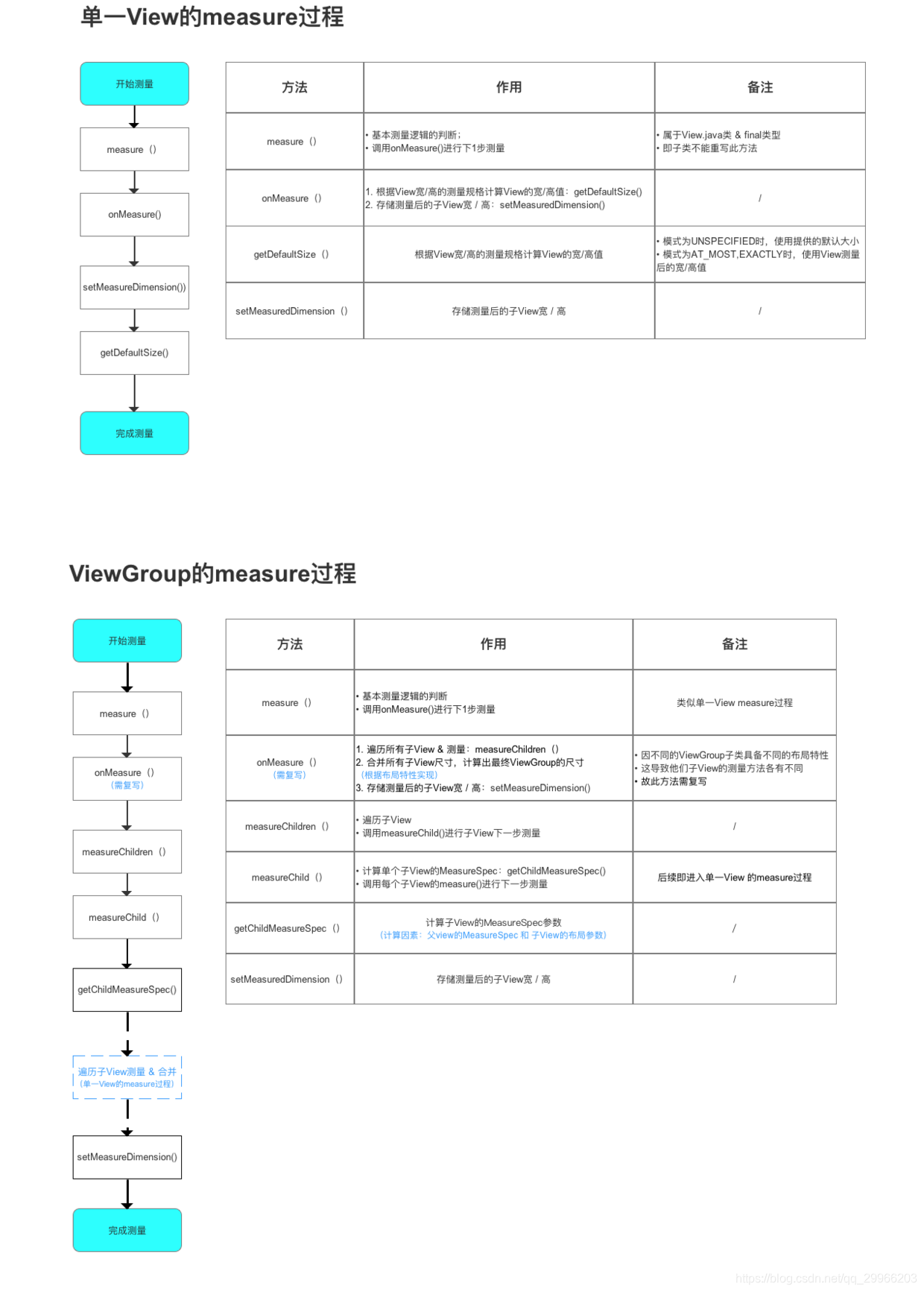
- 单一View
- ViewGroup
a. 遍历 测量所有子View的尺寸
b. 合并将所有子View的尺寸进行,最终得到ViewGroup父视图的测量值
自上而下、一层层地传递下去,直到完成整个View树的measure()过程
(1)自定义ViewGroup
需要复写onMeasure()从而实现自定义子View测量逻辑
因为不同的ViewGroup子类(LinearLayout、RelativeLayout / 自定义ViewGroup子类等)具备不同的布局特性,这导致他们子View的测量方法各有不同。因此,ViewGroup无法对onMeasure()作统一实现。
根据自身的测量逻辑复写onMeasure(),分为4步 - 遍历所有子View:measureChildren()
- 对子View 进行测量(根据父容器的measureSpec & 布局参数layoutParams) 并 递归调用View.measure():measureChild
- 合并所有子View的尺寸大小,最终得到ViewGroup父视图的测量值(自身实现)
- 存储测量后View宽/高的值:调用setMeasuredDimension()
1 |
|
(2)实例:LinearLayout extends ViewGroup
1 | protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) { |
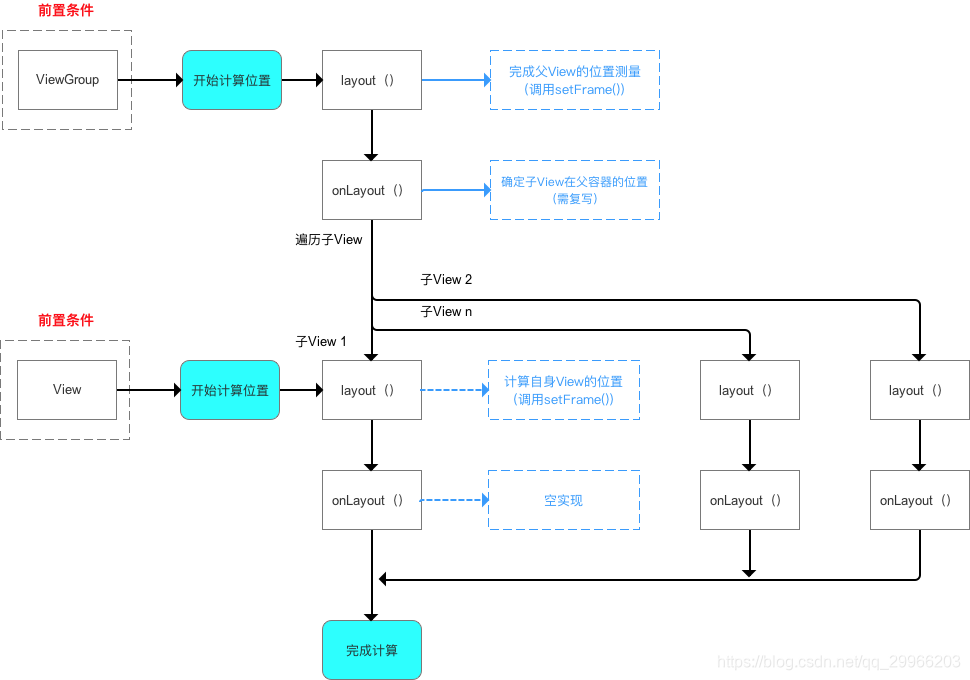
- layout —— 计算视图(View)的位置,即计算View的四个顶点位置:Left、Top、Right 和 Bottom

基础: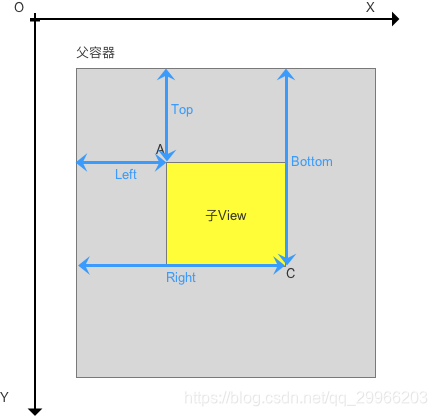
View的位置由4个顶点决定的(如下A、B、C、D),4个顶点的位置描述分别由4个值决定:
(请记住:View的位置是相对于父控件而言的)
Top:子View上边界到父view上边界的距离
Left:子View左边界到父view左边界的距离
Bottom:子View下边距到父View上边界的距离
Right:子View右边界到父view左边界的距离
- 单一View
- ViewGroup
a. 计算自身ViewGroup在父布局的位置:layout()(= setFrame())
b. 遍历ViewGroup的所有子View在ViewGroup的位置(调用子View 的 layout()):onLayout()
自上而下、一层层地传递下去,直到完成整个View树的layout()过程
(1)自定义ViewGroup
先计算自身在父容器中位置 setFrame(),再计算子View在父容器中相对位置onLayout():
必须重写onLayout()抽象方法,计算该ViewGroup包含所有的子View在父容器的位置。因:子View的确定位置与具体布局有关,所以onLayout()在ViewGroup没有实现。
根据自身逻辑复写布局方法onLayout(): - 循环遍历子View
- 计算当前子View相对于父容器(ViewGroup)的位置(根据具体布局)& 递归调用View.layout()
1 | // 计算该ViewGroup包含所有的子View在父容器的位置() |
(2)实例:LinearLayout extends ViewGroup
1 | /** |
- draw —— 绘制View视图

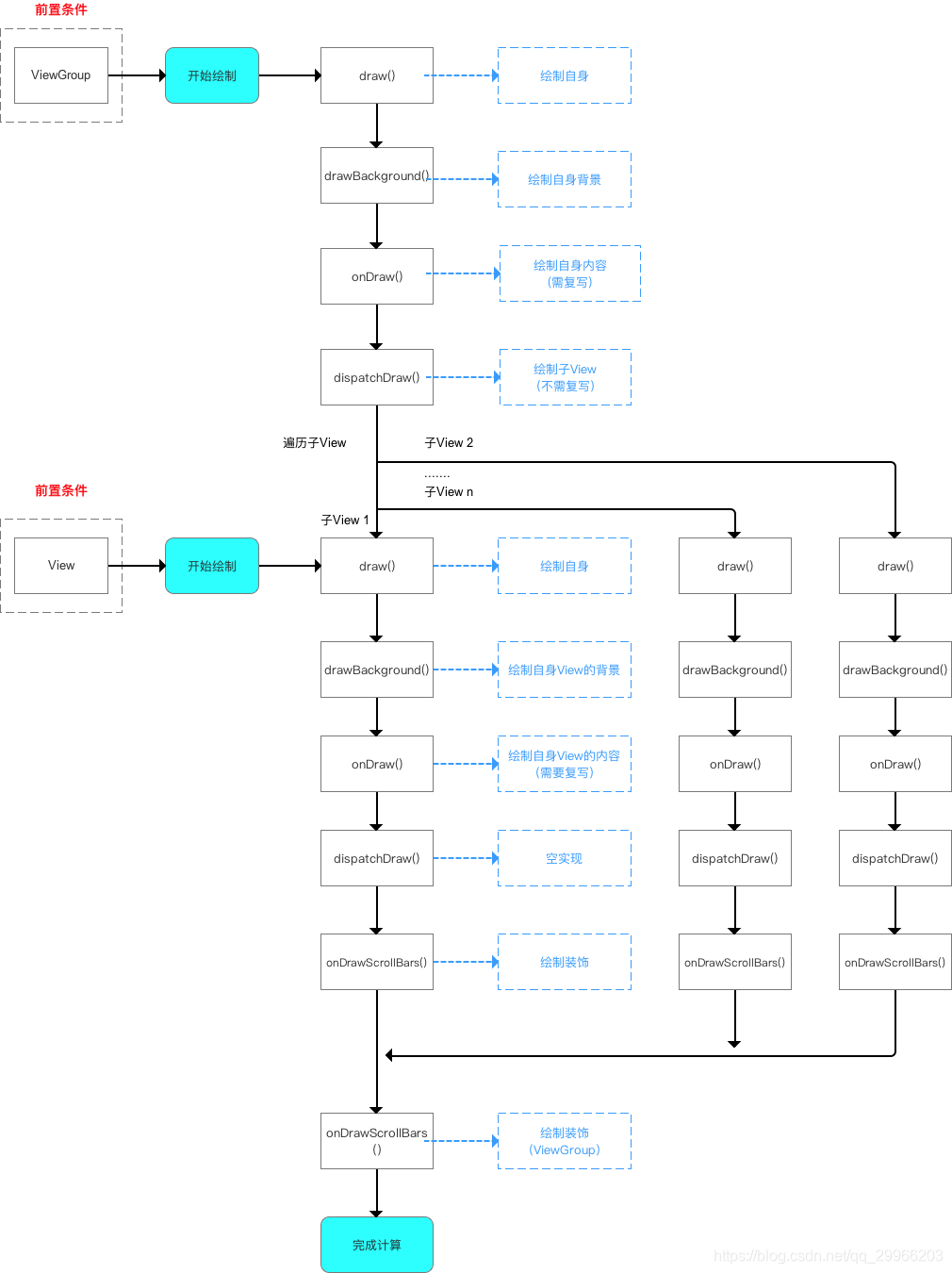
(1)单一View
1 | /** |
(2)ViewGroup
dispatchDraw默认逻辑:
- ViewGroup绘制自身(含背景、内容)
- 循环遍历子View
- 绘制子View(递归 调用View.draw() 绘制背景、内容、装饰)
- 绘制装饰(滚动指示器、滚动条、前景)
1 | /** |
自定义View
- 注意点
- 支持特殊属性
(1)支持wrap_content
如果不在onMeasure()中对wrap_content作特殊处理,那么wrap_content属性将失效
(2)支持padding & margin
如果不支持,那么padding和margin(ViewGroup情况)的属性将失效
对于继承View的控件,padding是在draw()中处理
对于继承ViewGroup的控件,padding和margin会直接影响measure和layout过程 - 多线程直接使用post
View的内部本身提供了post系列的方法,完全可以替代Handler的作用,使用起来更加方便、直接。 - 避免内存泄露
主要针对View中含有线程或动画的情况:当View退出或不可见时,记得及时停止该View包含的线程和动画,否则会造成内存泄露问题。 - 处理好滑动冲突
当View带有滑动嵌套情况时,必须要处理好滑动冲突,否则会严重影响View的显示效果。
在onTouchEvent()中处理
- 基本步骤
(1)创建自定义View类,复写相关方法(集成View类,具体绘制需要复写onDraw)
(2)在布局文件中添加自定义View类的组件
(3)Activity中setContentView(resId)显示 - 案例
(1)RefreshListView
(2)[含一键删除&自定义样式的SuperEditText][SuperEditText]
(3)[简单好用的搜索框(含历史搜索记录)][Link 6]
(4)[时间轴][Link 7]
(5)[一个可爱 & 小资风格的Android加载等待自定义View][_ _Android_View]
View刷新/重绘机制
- 时机
- 视图本身内部状态发生变化,比如显示属性由GONE到VISIBLE;
- ViewGroup中添加或删除了视图导致需要重新为子视图分配位置
- 视图本身的大小发生变化,比如TextView中的文本内容变多变少了
- 方法
- requestLayout
requestLayout()用于重新布局,该方法会递归调用父窗口的requestLayout()方法,直到触发ViewRootImpl的performTraversals()方法,此时mLayoutRequestede为true,会触发onMesaure()与onLayout()方法重新设置位置,不一定 会触发onDraw()方法。 - invalidate() & postInvalidate()
invalidate()和postInvalidate()均用于View的重绘。该方法递归调用父View的invalidateChildInParent()方法,直到调用ViewRootImpl的invalidateChildInParent()方法,最终触发ViewRootImpl的performTraversals()方法,此时mLayoutRequestede为false,不会 触发onMesaure()与onLayout()方法,会触发onDraw()方法。
invalidate()是在UI线程中使用,必须配合handler使用;postInvalidate可以在非UI线程中使用,不用使用handler。
invalidate主要给需要重绘的视图添加DIRTY标记,并通过不断回溯父视图做矩形运算求得真正需要绘制的区域,并最终保存在ViewRoot中的mDirty变量中,最后调用scheduleTraversals发起重绘请求,scheduleTraversals会发送一个异步消息,最终调用performTraversals()执行重绘(performTraversals()遍历所有相关联的 View ,触发它们的 onDraw 方法进行绘制)
postInvalidate只是实现了一个消息机制,让用户能够在非UI线程使用,最终还是调用到invalidate()方法来触发重画,实现界面更新动作。
- 流程
- View的界面刷新有三种方法invalidate(请求重绘)、requestLayout(重新布局)、requestFocus(请求焦点)
- View界面刷新的所有方法均会递归调用父容器的相关方法,从View树向上层层找到最顶层的DecorView,通过DecorView的mParent,即ViewRootImpl执行scheduleTraversals()方法进行界面绘制。
- 调用到scheduleTraversals()时不会立即执行,而是将该操作保存到待执行队列中。并给底层的刷新信号注册监听。
- 当VSYNC信号到来时,会从待执行队列中取出对应的scheduleTraversals()操作,并将其加入到主线程的消息队列中。
- 主线程从消息队列中取出并调用performTraversals()执行三大流程: onMeasure()-onLayout()-onDraw()
View的事件分发机制
Touch事件的传递 & 拦截机制
- 事件分发 简介
- 本质
由于Android的View是树形结构,多个View会重叠在一起,View事件分发的本质就是解决将点击事情(Touch)产生的MotionEvent对象传递到哪一个具体的View然后消耗处理这个事件的整个过程。 - 分发对象
Android事件分发顺序:Activity(Window) -> ViewGroup(容纳UI组件的容器,一组View的集合,如DecorView、Layout等) -> View(所有UI的基类) - 传递对象
事件(MotionEvent)
当用户触摸屏幕时(View或ViewGroup派生的控件),将产生点击事件(Touch事件)。Touch事件相关细节(发生触摸的位置、时间、历史记录、手势动作等)被封装成MotionEvent对象。
主要发生的Touch事件有如下四种:
MotionEvent.ACTION_DOWN:按下View(所有事件的开始)
MotionEvent.ACTION_MOVE:滑动View
MotionEvent.ACTION_UP:抬起View(与DOWN对应) - 事件分发对应方法
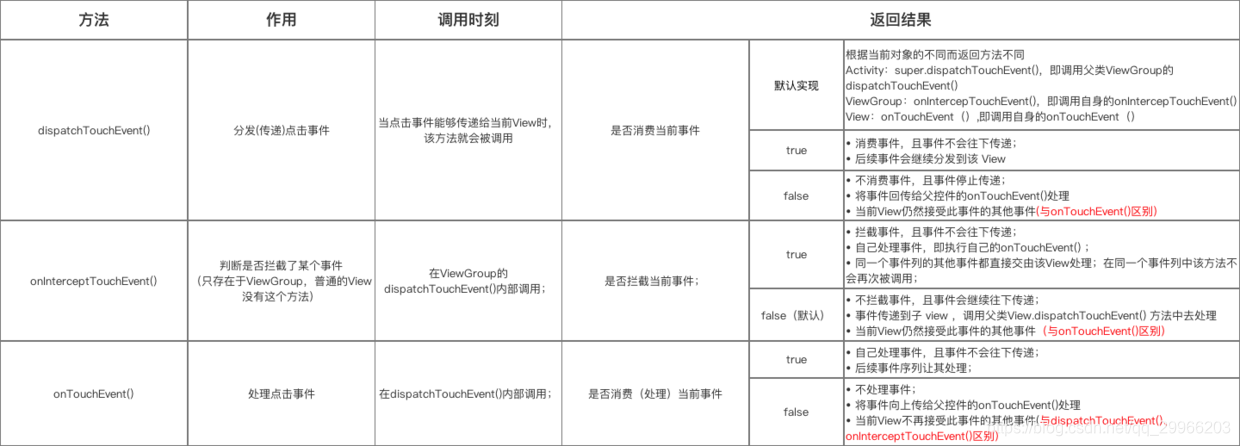
- 事件分发 流程
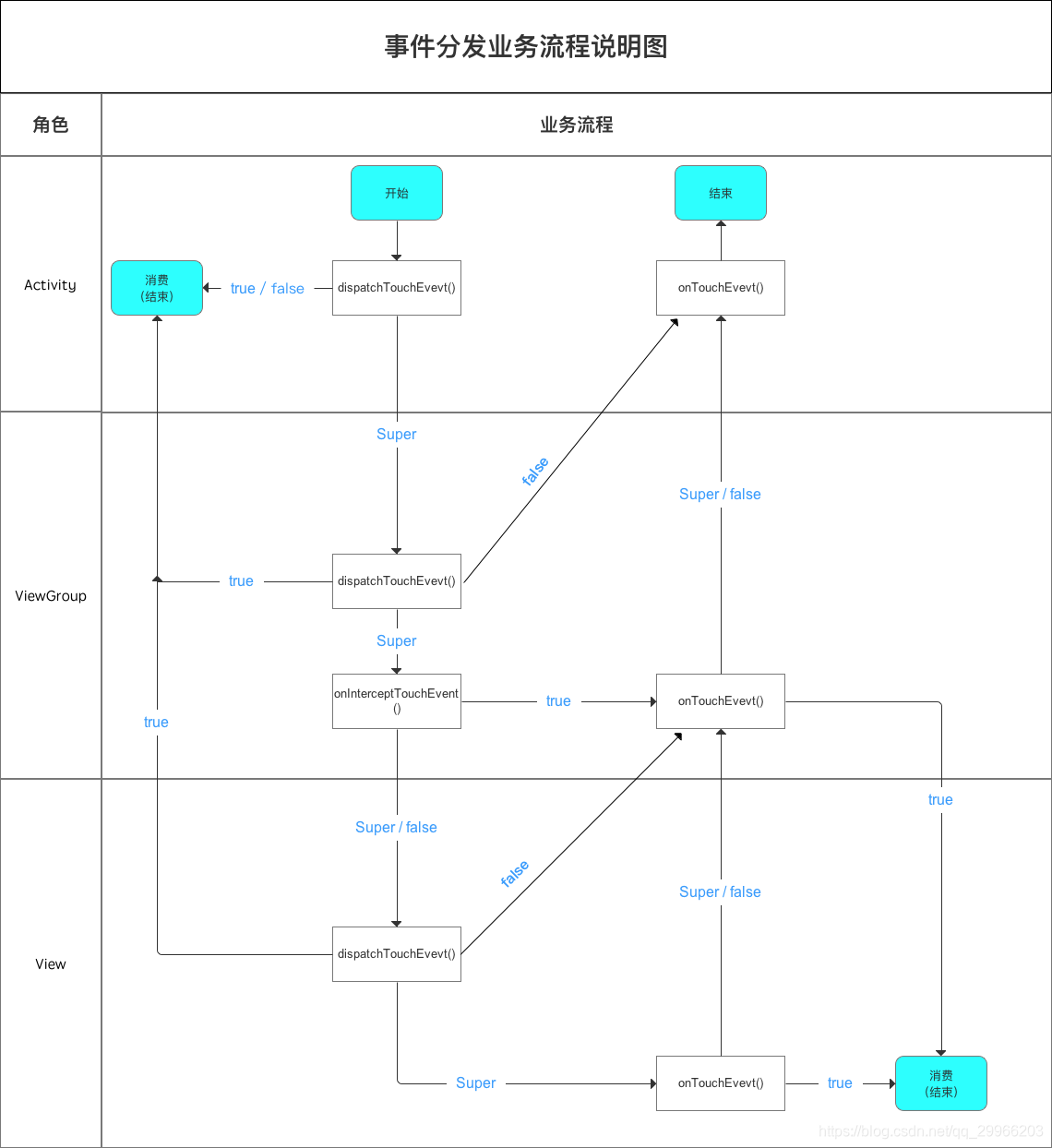
当一个点击事件产生后,它的传递过程遵循如下顺序:Activity–>Window–>View。
(1)Activity 事件分发
即先将事件传递给Activity,Activity再传递给Window,最后Window再传递给DecorView,DecorView接收到事件后,就会按照事件分发机制去分发事件。即调用调用ViewGroup的dispatchTouchEvent。
(2)ViewGroup 事件分发
此时顶级ViewGroup的dispatchTouchEvent就会被调用,这个方法用于事件分发。如果这个ViewGroup的onInterceptTouchEvent方法返回true就表示它要拦截当前的事件,接着事件就会交给这个ViewGroup处理,即它的onTouch方法就会被调用来消耗事件并返回true;如果这个ViewGroup的onInterceptTouchEvent方法返回false就表示它不拦截当前事件,这时当前事件就会继续传递给它的子元素View。
(3)View 事件分发
接着子元素的dispatchTouchEvent方法就会被调用,如果子元素是View,则它不会拦截事件,要么将事件消费,要么不处理直接回传。事件会按层级依此回传,最终会告诉Activity.dispatchTouchEvent。
在某个View拦截触摸事件:
- 设置View 的 <View android:clickable = “false” 不可点击 android:focusable = “false” 无法获取焦点 android:focusableInTouchMode = “false” 不可通过触摸获取焦点> 即使当前View不可获取点击事件,此时将事件回传给上一级父组件处理
- 设置View 的 onTouchEvent 返回值为false
- 设置View 的 父组件ViewGroup 的 onInterceptTouchEvent / dispatchTouchEvent 返回值为 true
dispatchTouchEvent 代码描述
1 | // 点击事件产生后,会直接调用dispatchTouchEvent()方法 |
- 事件分发 场景
原理分析:
类似侧滑菜单中若为一个列表,则对侧滑菜单SlideView的左右滑动事件可能会被列表的子元素ListViewItem消费,从而使左右滑动菜单显示/隐藏菜单功能失效
解决:
对侧滑菜单组件的onInterceptTouchEvent方法进行重写,滑动时获取x,y方向上的偏移值。若x方向上的偏移值>y方向上的偏移值 & x方向偏移值大于一个阈值,则返回true拦截此次触摸事件,交给侧滑菜单处理(调用侧滑菜单SlideView的滑动事件onScroll),否则交给子元素处理(ListViewItem的onClick)
1 | // 复写onInterceptEventTouch方法进行拦截处理 |
事件分发中的onTouch、onTouchEvent (和onClick) 有什么区别,又该如何使用?
这两个方法都在View.dispatchTouchEvent()中调用。
onTouch是View的onTouchListener中的方法。需要实现onTouchListener并且点击的View为enable时,View有touch事件便会调用。
onTouchEvent是复写的方法。屏幕有touch事件便会调用。
它们的区别在于
(1)onTouch优先级比onTouchEvent优先级高。当onTouch返回值为true,则表示事件已经被消费,便不会向onTouchEvent传递,也不会调用onClick(因为onClick是在onTouchEvent中执行的,onTouchEvent中performClick是onClick的入口方法)。只有当onTouch()的返回值为false。才会调用onTouchEvent()。
所以优先级为onTouch>onTouchEvent>onClick
(2)【为什么给ListView引入了一个滑动菜单的功能,ListView就不能滚动了?】
滑动菜单的功能是通过给ListView注册了一个touch事件来实现的。如果在onTouch方法里处理完了滑动逻辑后返回true,那么ListView本身的滚动事件就被屏蔽了,自然也就无法滑动(控件内置事件如滚动事件onScroll与点击事件onClick等等均基于onTouchEvent,优先级小于onTouch),因此解决办法就是在onTouch方法里返回false。
动画
种类 & 特点 & 区别 &原理
| 视图动画 | 属性动画 | ||
| 类型 | 补间动画 | 逐帧动画 | 属性动画 |
| 作用对象 | 视图控件(View) 如Android的TextView、Button等 不可作用于View组件的属性,如:颜色、背景等 |
任意Java对象 不仅局限于视图View对象 |
|
| 原理 | 通过确定开始的视图样式 & 结束的视图样式,中间动画变化过程由系统补全来确定一个动画 | 将动画拆分为帧的形式,且定义每一帧均是一张图片,按顺序播放一组预先定义好的图片 | 在一定时间间隔内,通过不断对值进行更改,并不断传值给对象的属性,从而实现对象在该属性上的动画效果 |
| 特点 | 作用对象局限:View & 只能改变View的视觉效果而无法改变View的属性 & 动画效果单一 适合视图简单、基本的动画效果(如Activity、Fragment的切换效果,或视图组(ViewGroup)中子元素出厂效果) |
作用对象扩展:面向属性,作用对象可以是任何一个Object对象 & 实际改变视图的属性 & 动画效果丰富:包括四种基本变化意外的其他动画效果 适合与属性相关,更为复杂的动画效果 |
|
| 使用 | 四种基本变换类型: 平移动画(Translate) 缩放动画(Scale) 旋转动画(Rotate) 透明度动画(Alpha) |
使用时避免使用尺寸大的图片,否则会引起OOM | 主要使用 ValueAnimator & ObjectAnimator |
| 区别 | 是否改变动画本身的属性 视图动画仅仅对图像进行变化,视图的位置、相应区域等均在远地;而属性动画是通过过动态改变对象的属性从而达到动画效果 |
||
使用
- 补间动画
[Android 补间动画:手把手教你使用 补间动画 ][Android _ _]
(1)在 res/anim的文件夹里创建动画效果.xml文件
创建地址为:res/anim/view_animation.xml
(2)根据 不同动画效果(平移、缩放、旋转、透明度)的语法 设置 不同动画参数,从而实现动画效果
| 动画类型 | 标签 | 方法 |
|---|---|---|
| 公用 | / | android:duration:动画持续时间 android:startOffset:动画延迟开始时间 android:repeatCount:动画重放次数 android:interpolator:插值器 |
| 平移 | < translate/ > | android:fromXDelta:视图在水平方向x 移动的起始值 android:toXDelta:视图在水平方向x 移动的结束值 android:fromYDelta:视图在竖直方向y 移动的起始值 android:toYDelta:视图在竖直方向y 移动的结束值 |
| 缩放 | < scale/ > | android:fromXScale:动画在水平方向X的起始缩放倍数 android:toXScale:动画在水平方向X的结束缩放倍数 android:fromYScale=“0.0”:动画开始前在竖直方向Y的起始缩放倍数 android:toYScale:动画在竖直方向Y的结束缩放倍数 android:pivotX:缩放轴点的x坐标 android:pivotY:缩放轴点的y坐标 |
| 旋转 | < rotate/ > | android:fromDegrees=“0.0”:动画开始时 视图的旋转角度 android:toDegrees:动画结束时 视图的旋转角度 android:pivotX:旋转轴点的x坐标 android:pivotY:旋转轴点的y坐标 |
| 透明度 | < alpha/ > | android:fromAlpha=“0.0”:动画开始时 视图的透明度 android:toAlpha:动画结束时 视图的透明度 |
| 组合 | < set/ > | android:shareinterpolator:表示组合动画中的动画是否和集合共享同一个差值器 |
(3)在Java代码中创建Animation对象并播放动画
1 | Button mButton = (Button) findViewById(R.id.Button); |
- 逐帧动画
[Android 逐帧动画:关于 逐帧动画 的使用都在这里了!][Android _ _ 1]
(1)将动画资源(即每张图片资源)放到 drawable文件夹里
(2)从drawable文件夹获取动画资源 & 载入并启动动画
1 | public class FrameActivity extends AppCompatActivity { |
- 属性动画
[Android 属性动画:这是一篇很详细的 属性动画 总结&攻略][Android _ _ 2]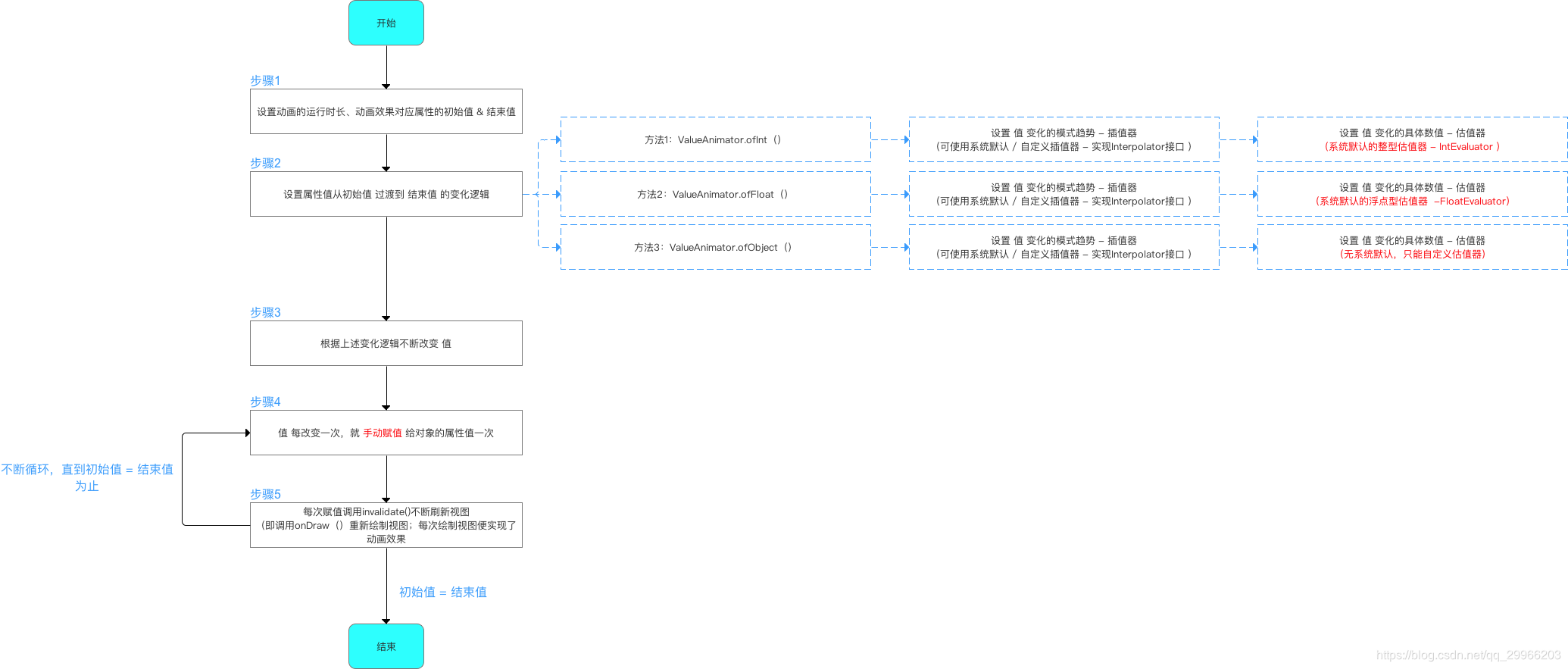
源码
[Android 动画原理分析][Android]
问题
- OOM:使用逐帧动画时避免使用尺寸大的图片,否则会引起OOM。
- 内存泄露:当我们把动画的repeatCount设置为无限循环时,如果在Activity退出时没有及时将动画停止,属性动画会导致Activity无法释放而导致内存泄漏,而补间动画却没有问题。因此,使用属性动画时切记在Activity执行 onStop 方法时顺便将动画停止。
在使用ValueAnimator或者ObjectAnimator时(ObjectAnimator继承ValueAnimator),如果没有及时做cancel取消动画,就可能造成内存泄露。ValueAnimator 有个AnimationHandler的单例,会持有属性动画对象自身的引用,属性动画对象持有view的引用,view持有activity引用,所以导致的内存泄露。
[分析:补间动画和属性动画内存泄露][Link 8]
估值器
插值器用于设置属性值从初始值过渡到结束值变化规律的一个接口。用于实现非线性运动,如匀速、加速、减速的动画效果。
估值器用于设置属性值从初始值过渡到结束值的变化具体数值的一个接口。用于决定值的变化规律,如匀速、加速、减速的变化趋势。用于辅助插值器实现非线性运动。
ListView & RecycleView
ListView 定义 & 原理 & 优化 & 封装?
- ListView & Adapter
列表 ListView 是 Android中的一种列表视图组件,继承自AdapterView抽象类。
适配器 Adapter 作为 View 和 数据 之间的桥梁&中介,将数据映射到列表要展示的View中。
ListView 仅作为容器(列表),用于装载 & 显示数据(即 列表项Item),而容器内的具体每一项的内容(列表项Item)则是由 适配器(Adapter)提供。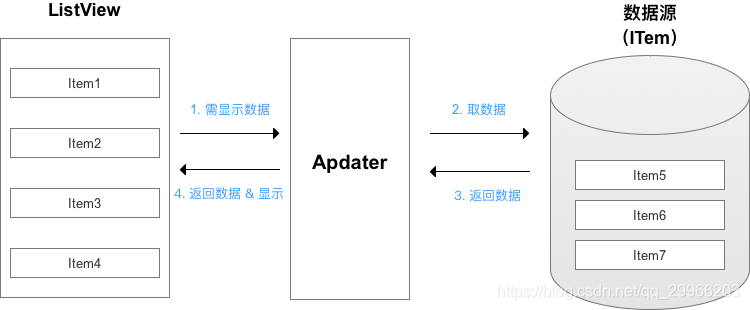
- RecycleBin 缓存原理
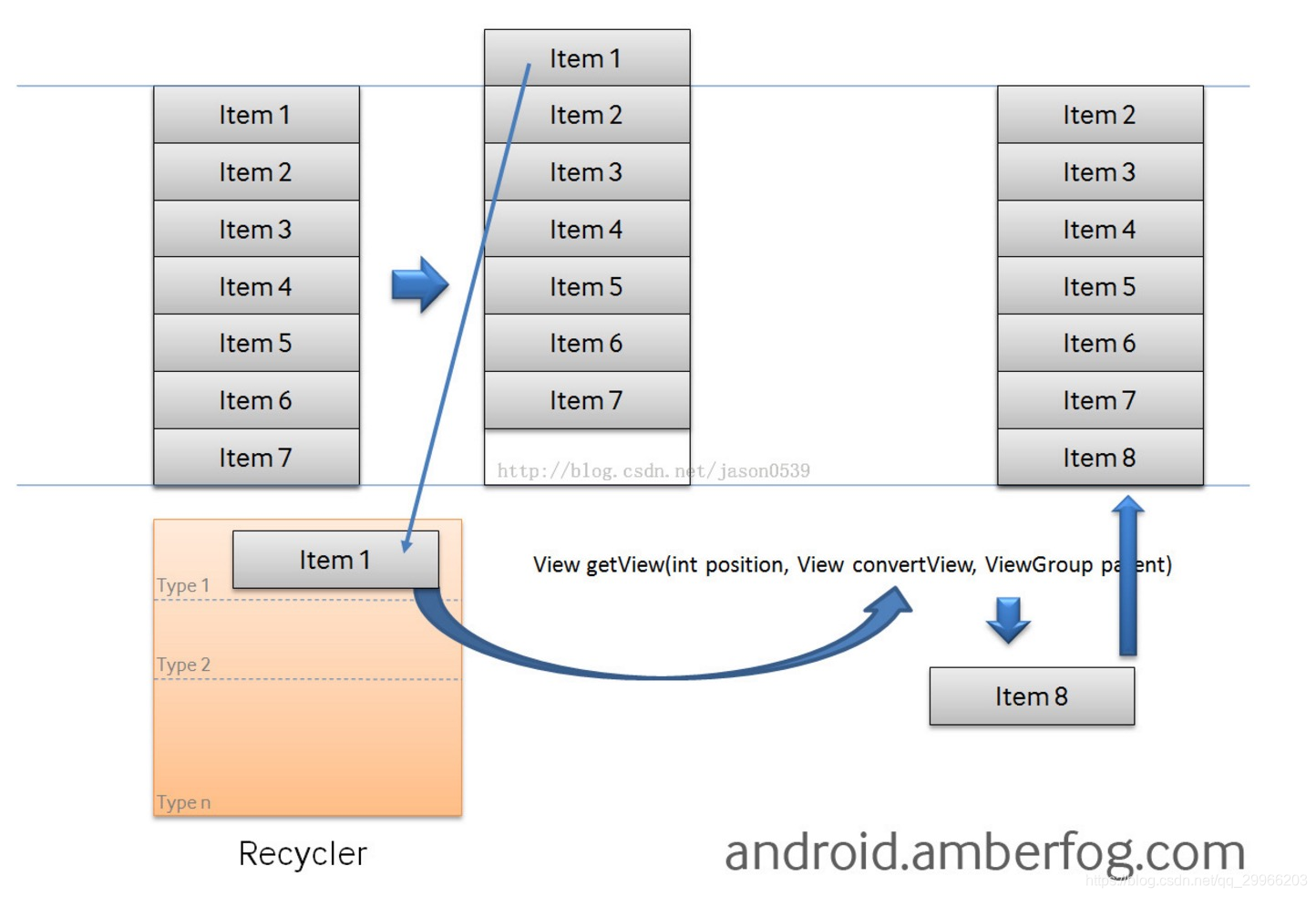
为了节省空间和时间,ListView不会为每一个数据创建一个视图,而是采用了RecycleBin(Recycler组件),用于回收 & 复用 View。
当屏幕需显示x个Item时,那么ListView会创建 x+1个视图。移出屏幕的View控件会缓存到RecycleBin当中,当有View进入屏幕后,ListView会从RecycleBin里面取出一个缓存View控件,将其作为convertView参数传递到Adapter的getView中,从而达到View的复用,不必每次都加载布局(LayoutInflater.inflate()) - ListView 优化
- getView() 优化
convertView优化
主要优化加载布局的问题——减少getView方法每次调用LayoutInflater.inflate()方法
1 | public View getView(int position, View convertView, ViewGroup parent){ |
- viewHolder优化(Google推荐ListView优化方案)
主要优化加载控件问题——减少getView方法每次调用findViewById()方法
1 | public View getView(int position, View convertView, ViewGroup parent) { |
- 图片错乱
图片错乱:ContentView复用 + 异步加载网络图片
1 | public View getView(int position, View convertView, ViewGroup parent) { |
假设屏幕上有7个条目,向上滑动。新的第8个条目进入界面就会回调getView()方法,而在getView()方法中会开启异步请求从网络上获取图片。由于网络操作耗时,刚进入的条目在图片下载完前会显示缓存中ImageView的图片(即第1个条目的图片),等到下载结束会变回网络图片。(因为第1个图片与第8个图片指向同一块ImageView实例)此时,若ListView快速滑动,移出屏幕的条目被进入的条目重新利用,若此时移出的条目发起的图片请求有了响应。则会造成不同位置显示图片错乱的现象。(显示第15个图片时,第8个图片得到响应,此时的image为第15个图片所复用,但显示的确是第8个图片)
解决方案:通过对ImageView设置tag(通常用图片的url)防止图片错位。
每次getView时(新的元素进入屏幕),对ImageView设置标签。当网络加载结束后,查询当前ImageView的标签,如果更改了,说明该ImageView被新的元素复用(因为移出屏幕的旧元素和进入屏幕的新元素指向的是同一块ImageView实例),则不显示加载的网络图片;否则仍为原来图片元素,显示加载的网络图片。
1 | public View getView(int position, View convertView, ViewGroup parent) { |
- 最优化方案的完整实现方案
(1)定义主xml布局:activity_main.xml
1 | <?xml version="1.0" encoding="utf-8"?> |
(2)根据需要,定义ListView每行所实现的xml布局(item布局):item.xml
1 | <?xml version="1.0" encoding="utf-8"?> |
(3)定义一个Adapter类继承BaseAdapter,重写里面的方法:MyAdapter.java
1 | class MyAdapter extends BaseAdapter { |
(4)在MainActivity中构造Adapter对象,设置适配器,将ListView绑定到适配器上:MainActivity.java
1 | public class MainActivity extends AppCompatActivity { |
- ListView 性能优化
- Bitmap优化
(1)用软引用存储图片信息
(2)图片压缩
(3)三级缓存 - 内存优化
(1)避免内存泄露,如使用Adapter传入context时注意context的生命周期(getApplicationContext)
(2)通过对View的复用减少内存
(3)分页机制 - ListView 封装 —— 实现下拉刷新,上拉加载的具有分页机制的ListView
[黑马视频:RefreshListView —— 下拉刷新 & 上拉加载][RefreshListView _ _ _]
设计思路:
(1)初始化头布局,动画:自定义头布局,初始隐藏头布局(mHeaderView.setTopPadding(-measuredHeight))
(2)处理触摸事件,根据下滑偏移量的大小设置不同状态,并根据状态进行处理(修改头布局、数据请求等): - ACTION_MOVE && 列表头显示第一条数据(getFirstVisiblePosition == 0):
(a)if(offset < measuredHeight && currentState != PULL_TO_REFRESH) :不完全显示 => 下拉刷新,修改头布局
(b)if(offset >= measuredHeight && currentState != RELEASE_REFRESH) :完全显示 => 释放刷新,修改头布局 - ACTION_DOWN
(a)if(currentState == RELEASE_REFRESH)
正在刷新,修改头布局,调用接口方法请求数据
(b)if(currentState == PULL_TO_REFRESH)
恢复头布局
(3)设置监听器,监听列表中数据变化: - 控件创建监听器回调接口,并调用接口方法
- 用户实现接口方法,监听刷新事件,进行网络请求
ListView封装
1 | public class RefreshListView extends ListView implements AbsListView.OnScrollListener { |
MainActivity调用
1 | public class MainActivity extends AppCompatActivity { |
RecycleView 对比 & 应用
- 简介
用于代替ListView的滑动组件。相对于ListView功能更强大、支持定制样式更丰富、扩展性更高。 - 特点

1 | mRecyclerView = findView(R.id.id_recyclerview); |
- 应用
RecyclerView 展示多种类型Item数据
(1)定义每个条目的bean
1 | public class Goods { |
(2)定义各样式(ViewHolder)统一的委托接口
1 | public interface IDelegateAdapter { |
(3)不同样式实现自己的Adapter,创建/复用 RecyclerView.ViewHolder
GoodsOfMineDelegateAdapter.java
1 | public class GoodsOfMineDelegateAdapter implements IDelegateAdapter { |
GoodsOfOthersDelegateAdapter.java
1 | public class GoodsOfOthersDelegateAdapter implements IDelegateAdapter { |
(4)实现RecyclerViewAdapter 继承 RecyclerView.Adapter<RecyclerView.ViewHolder>
1 | public class GoodsAdapter extends RecyclerView.Adapter<RecyclerView.ViewHolder>{ |
(5)RecyclerViewActivity中创建适配器,RecyclerView,绑定。并为RecyclerView设置布局管理器
activity_recycler_view.xml
1 | <?xml version="1.0" encoding="utf-8"?> |
RecyclerView.java
1 | public void initViews(){ |
对于固定块数的样式。比如硅谷商城界面,分为6块:横幅、频道、活动、秒杀、推荐和热卖。则getItemCount()中return 6(固定),此时getItemViewType(position)则会从0遍历到5,根据各个位置的布局,填充相应的样式(ViewHolder)即可。源码:
1 | // 6种类型 |
PopupWindow & Dialog
PopupWindow
定义popupWindow类
1 | /** |
自定义Style
1 | <style name="MyPopup" parent="android:style/Theme.Dialog"> |
定义进入和退出的动画:
进入:
1 | <?xml version="1.0" encoding="utf-8"?> |
退出
1 | <?xml version="1.0" encoding="utf-8"?> |
动画的style
1 | <style name="mypopwindow_anim_style"> |
在指定的位置显示
1 | //显示窗口 |
Dialog
定义style
1 | <!--自定义布局的dialog--> |
动画: 和popupwindow一致
自定义Dialog:
1 | /** |
在Activity中调用:
1 | SelectPicDialog dialog = new SelectPicDialog(mContext,R.style.MyDialog); |
PopupWindow & Dialog 区别
- Popupwindow在显示之前一定要设置宽高,Dialog无此限制。
- Popupwindow默认不会响应物理键盘的back,除非显示设置了popup.setFocusable(true);而在点击back的时候,Dialog会消失。
- Popupwindow不会给页面其他的部分添加蒙层,而Dialog会。
- Popupwindow没有标题,Dialog默认有标题,可以通过dialog.requestWindowFeature(Window.FEATURE_NO_TITLE);取消标题
- 二者显示的时候都要设置Gravity。如果不设置,Dialog默认是Gravity.CENTER。
- 二者都有默认的背景,都可以通过setBackgroundDrawable(new ColorDrawable(android.R.color.transparent));去掉。
其中最本质的差别就是:AlertDialog是非阻塞式对话框:AlertDialog弹出时,后台还可以做事情;而PopupWindow是阻塞式对话框:PopupWindow弹出时,程序会等待,在PopupWindow退出前,程序一直等待,只有当我们调用了dismiss方法的后,PopupWindow退出,程序才会向下执行。这两种区别的表现是:AlertDialog弹出时,背景是黑色的,但是当我们点击背景,AlertDialog会消失,证明程序不仅响应AlertDialog的操作,还响应其他操作,其他程序没有被阻塞,这说明了AlertDialog是非阻塞式对话框;PopupWindow弹出时,背景没有什么变化,但是当我们点击背景的时候,程序没有响应,只允许我们操作PopupWindow,其他操作被阻塞。
第五章 网络 之 计算机网络
- 计算机体系结构
- 计算机网络概念、组成与功能
- 计算机网络分层结构(各层功能)
- ISO/OSI 7层模型(权威)
- TCP/IP 4层模型(实用)
- 5层模型(折中)
- 一. 物理层
- 二. 数据链路层
- 基本功能
- 封装成帧
- 透明传输
- 差错检测
- 相关概念
- 局域网
- 以太网
- MAC地址
- 交换机
- 三. 网络层
- 异构网络互联(互联网)
- 路由选择 & 分组转发
- 路由表
- 为什么不用目的主机号制作路由表 / 为什么不直接用MAC地址/寻址?
- 内部结构 / 工作原理
- 分组转发算法
- IPv4 & IPv6
- IP数据报格式
- IP地址编址方式
- 第一阶段 1981:分类IP地址(2级结构)
- 第二阶段 1985:子网划分(3级结构)
- 第三阶段 1987:CIDR(无分类 / 网络前缀)
- 第四阶段 1994:NAT(地址转换)
- 相关协议
- ARP 地址解析协议(Adress Resolution Protocol)
- DHCP 动态主机设置协议(Dynamic Host Configuration Protocol)
- ICMP 网络控制报文协议(Internet Control Message Protocol)
- VPN 虚拟专用网
- 路由协议
- 内部网关协议IGP(RIP、OSPF)
- 外部网关协议EGP(BGP)
- 网络层设备:路由器
- 四. 传输层
- 传输层寻址 && 端口
- TCP && UDP
- TCP/UDP 特点
- 首部格式
- 三次握手 & 四次挥手
- TCP可靠传输
- 超时重传
- 滑动窗口
- 流量控制
- 拥塞控制
- 五. 应用层
- 网络应用模型
- C/S(客户端/服务器)方式
- P2P(peer to peer 对等)方式
- 相关协议
- DNS系统
- FTP
- 电子邮件(SMTP、POP3、IMAP)
- WWW(HTTP)
- Telent
- 面试
- MAC / IP地址 & 作用?
- 描述一次网络请求的流程/浏览器访问一个url网址所经历的过程?
- 什么是DNS?作用是什么?工作机制?
[文都考研——计算机网络强化班][Link 30]
计算机体系结构
计算机网络体系结构:计算机网络各层次与协议的集合
(1)层次:每个层次的功能是明确的,独立的,对等的。
(2)协议:为数据交换而制定的规则,约定,标准。包含:
- 语义:解释比特流每一部分的意义。
- 语法:用户数据与控制信息的结构与格式,以及数据出现的顺序的意义。
- 时序:事件实现顺序的详细说明。
计算机网络概念、组成与功能
- 概念
计算机网络就是利用通信设备和线路将地理位置不同、功能独立的多个计算机系统互连起来,以功能完善的网络软件(即网络通信协议、信息交换方式、网络操作系统等)实现网络中资源共享和信息传递的系统。 - 组成
资源子网:负责数据处理的主计算机与终端,由主机终端负责。
通信子网:负责数据通信处理的通信处理机与通信线路,由路由器,交换机负责。
计算机网络分层结构(各层功能)
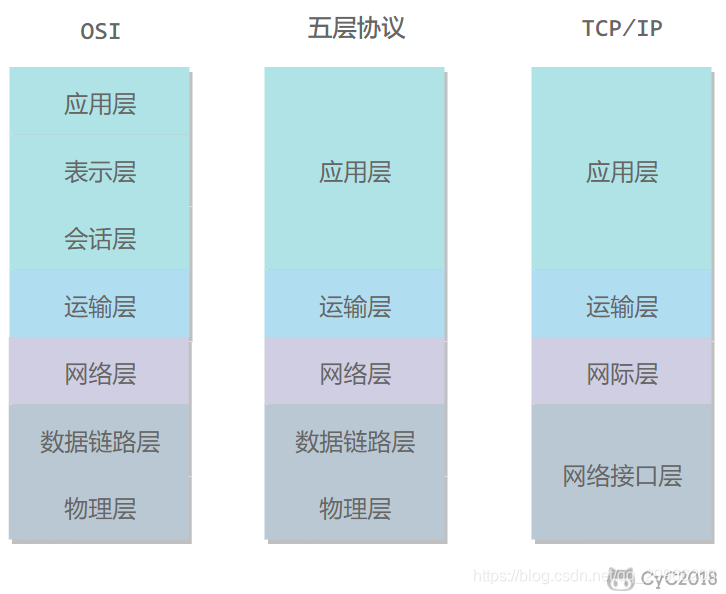
ISO/OSI 7层模型(权威)
- 物理层
利用传输介质为通信的网络结点之间建立、管理和释放物理连接;实现比特流的透明传输,位数据链路层提供数据传输服务;物理层的数据传输单元是比特。 - 数据链路层
在物理层提供的服务基础上,数据链路层在通信实体间简历数据链路连接;传输以”帧”为单位的数据包;采用差错控制与流量控制方法,使有差错的物理线路编程无差错的数据链路。 - 网络层
通过路由选择算法为分组通过通信子网选择最适当的路径;为数据在结点之间传输创建逻辑链路。 - 传输层(承上(资源子网)启下(通信子网))
向用户提供可靠端到端(end to end)通信;处理数据包错误、数据包次序以及其他一些关键传输问题;屏蔽了下层数据通信的细节,是计算机通信体系结构中关键的一层。 - 会话层
建立及管理会话(数据交换)。负责维护两个结点之间的传输链接,以便确保点到点传输不终端。 - 表示层
用于处理在两个通信系统中交换信息的表示方式,包括数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。 - 应用层
为应用程序提供了网络服务;应用层需要识别并保证通信对方的可用性,使得协同工作的应用程序之间的同步。建立传输错误纠正与保证数据完整性的控制机制。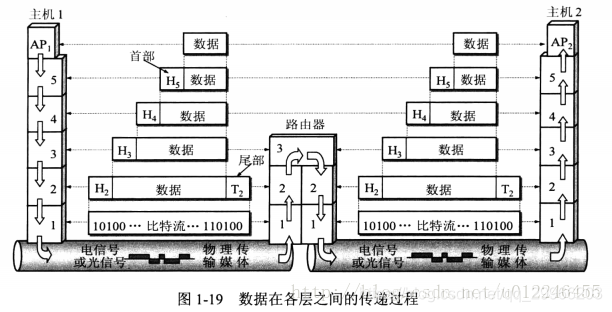
TCP/IP 4层模型(实用)
TCP/IP协议独立于特定的计算机硬件与操作系统,屏蔽网络层以下的传输。拥有统一的网络地址分配方案,使整个TCP/IP设备在网络中都有唯一的地址。
- 网络接口层:负责通过网络发送和接收IP数据报
- 网络层:IP协议是无连接的,提供”尽力而为”服务的网络层协议
- 传输层:在互联网中源主机与目的主机的对等实体间建立用于会话的端-端链接。包括TCP、UDP
- 应用层:包括Telnet、FTP、SMTP、P0P3、IMAP、DNS、HTTP等
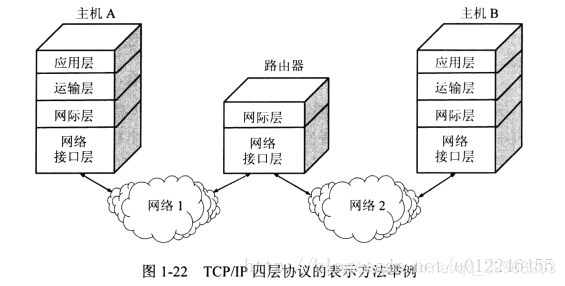
5层模型(折中)
包含:物理层、数据链路层、网络层、传输层、应用层
一. 物理层
二. 数据链路层
基本功能
封装成帧
将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
透明传输
透明表示一个实际存在的事物看起来好像不存在一样。
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。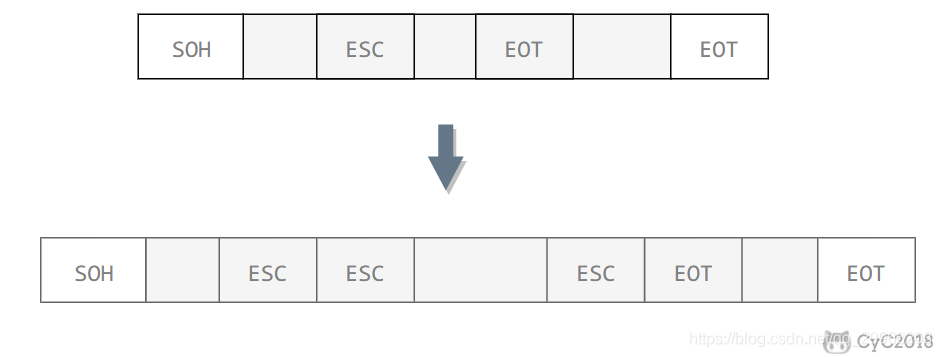
差错检测
目前数据链路层广泛使用了循环冗余检验(CRC)来检查比特差错。
相关概念
局域网
局域网是一种典型的广播信道,主要特点是网络为一个单位所拥有,且地理范围和站点数目均有限。
广播信道:一对多通信,一个结点发送数据能够被广播信道上所有结点接收到。所有的节点都在同一个广播信道上发送数据,因此需要有专门的控制方法进行协调,避免发生冲突(冲突也叫碰撞)。主要有两种控制方法进行协调,一个是使用信道复用技术,一是使用 CSMA/CD 协议。
主要有以太网、令牌环网、FDDI 和 ATM 等局域网技术,目前以太网占领着有线局域网市场。
可以按照网络拓扑结构对局域网进行分类: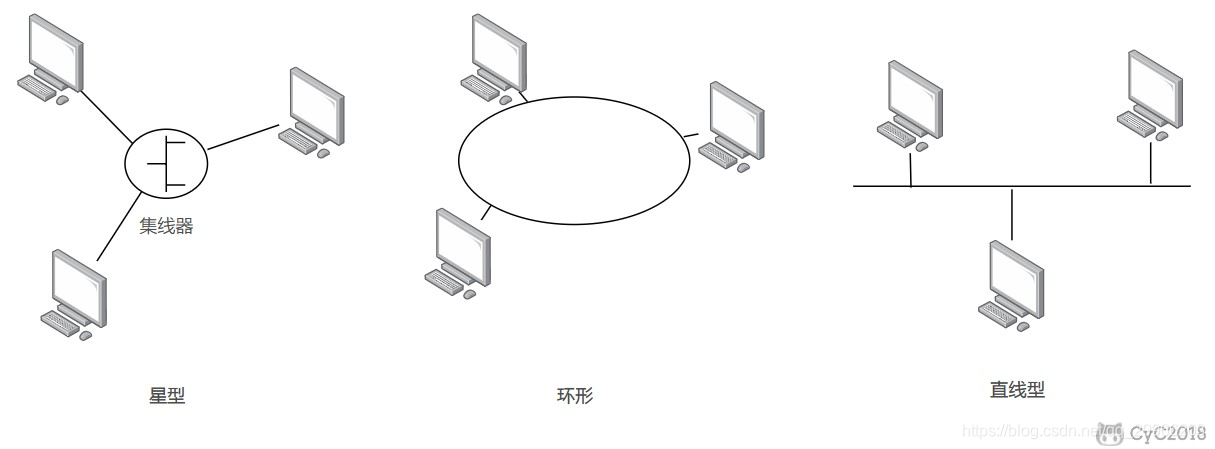
以太网
以太网是一种星型拓扑结构局域网。
早期使用集线器进行连接,目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
以太网/MAC帧格式:
类型 :标记上层使用的协议;
数据 :长度在 46-1500 之间,如果太小则需要填充;
FCS :帧检验序列,使用的是 CRC 检验方法;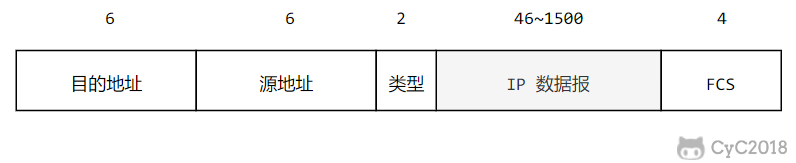
MAC地址
MAC 地址又称物理/硬件地址,是链路层地址,长度为 6 字节(48 位),用于唯一标识网络适配器(网卡)。
MAC地址前三字节(高位24位)由IEEE的注册管理机构RA负责向厂家分配。
MAC地址后三字节(地位24位)由厂家自行指派,称为扩展标识符,必须保证生产出的网络适配器没有重复地址。
交换机
交换机又称交换式集线器,实质上是一个多接口网桥,工作在数据链路层。根据MAC帧的目的地址对收到的帧进行转发。实现数据链路层上局域网的互连。(互连不同数据链路层协议、不同传输介质与不同传输速率的网络)
交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC 地址到接口的映射。
正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。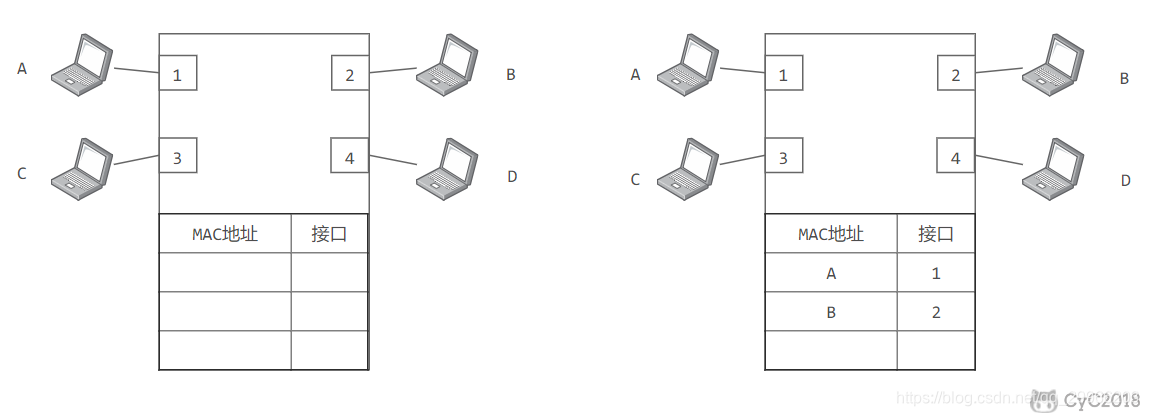
三. 网络层
网络层主要任务:
- 通过路由选择算法,为分组通过通信子网选择最适当的路径;
- 网络层使用数据链路层的服务,实现路由选择、拥塞控制与网络互连等基本功能,向传输层的端到端传输连接提供服务。
异构网络互联(互联网)
互联网是使用IP协议,通过路由器(网关)将各种物理网络互连起来的虚拟互连网络。
互连起来的各种物理网络的异构性是客观存在的,利用IP协议可以使这些性能各异的网络从用户看起来好像是一个统一的网络(屏蔽物理网络的异构性)。
从网络层看IP数据报:
- 网络地址不变(源IP地址、目的IP地址)
- 链路层地址变化(源MAC地址、目的MAC地址)
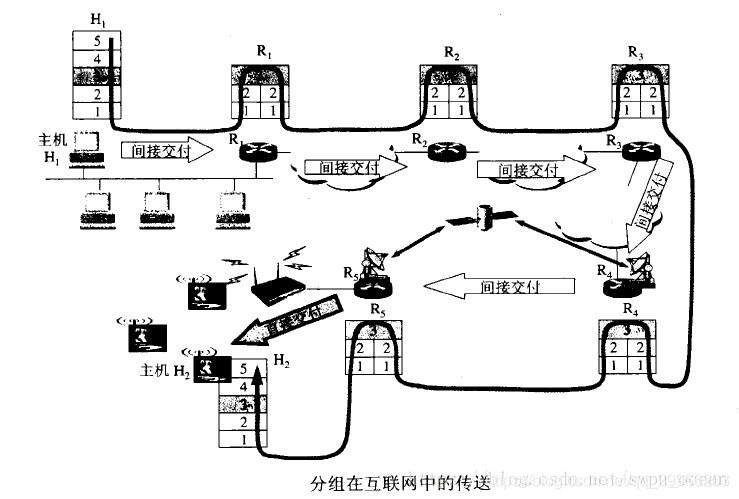
路由选择 & 分组转发
- 分组转发
转发就是路由器根据路由/转发表将用户的IP数据报从合适的端口转发出去。 - 路由选择
按照分布式算法根据从各相邻的路由器得到关于网络拓扑的变化情况,动态地改变所选择地路由。路由表是根据李由选择算法得出地。
路由表
为什么不用目的主机号制作路由表 / 为什么不直接用MAC地址/寻址?
(1)根据目的主机的MAC地址制作路由表,使得路由表过于庞大。
(2)由于物理网络的异构性使不同链路主机的地址不统一,需要转化。
有四个A类网络通过三个路由器连接在一起。每一个网络上都可能有成千上万个主机。可以想象,若按目的主机号来制作路由表,则所得出路由表就会过于庞大。但若按主机所在网络地址来制作路由表,那么每一个路由器中的路由表就只包含4个项目。可以使路由表简化。
内部结构 / 工作原理
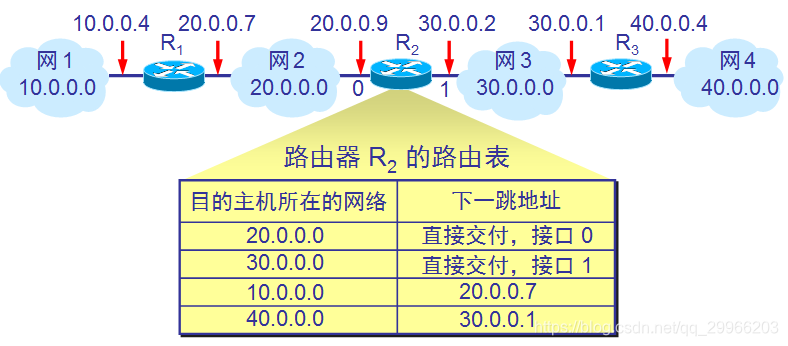
在路由表中,对每一条路由,包含(目的网络地址,下一跳地址)
路由表项主要字段:目的网络、子网掩码、下一跳路由、经由接口
根据目的网络地址就能确定下一跳路由器,因此IP数据报最终一定可以找到目的主机所在目的网络上的路由器(可能经过多次间接交付)。只有到达最后一个路由器时,才试图向目的主机进行直接交付。
注:
IP数据报首部中没有地方用来指明”下一跳路由器的IP地址”
当路由器收到待转发的数据报,不是将下一跳路由器的IP地址填入IP数据报,而是送交下层的网络接口软件。网络接口软件使用ARP负责将下一跳路由器的IP地址转换成硬件地址,并将此硬件地址放在链路层MAC帧首部,然后根据这个硬件地址找到下一跳路由器。
因此IP数据报在网络层IP(逻辑)地址不变,MAC(物理)地址不断变化。
分组转发算法
(1)从数据报的首部提取目的主机的IP地址D,得出目的网络地址为N;
(2)若网络N与此路由器直接相连,则把数据报直接交付目的主机D;否则是间接交付,执行(3);
(3)若路由表中有目的地址为D的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则执行(4);
(4)若路由表中有到大网络N的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5);
(5)若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由;否则,执行(6);
默认路由:若匹配路由表中其他项都不匹配,则走默认路由指明的路由。
(6)报告转发分组出错。
若路由表项皆不匹配且无默认路由,主机发出错的ICMP包。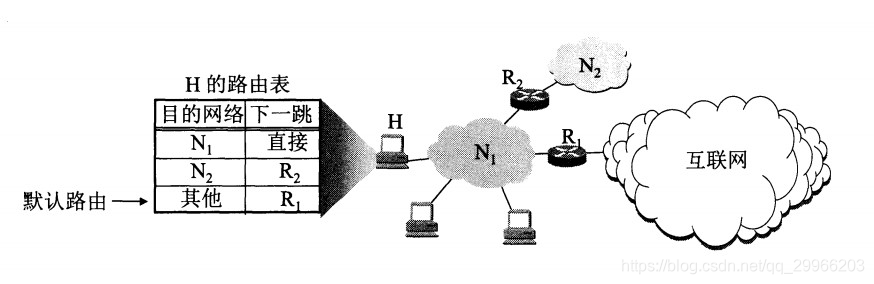
IPv4 & IPv6
IP数据报格式
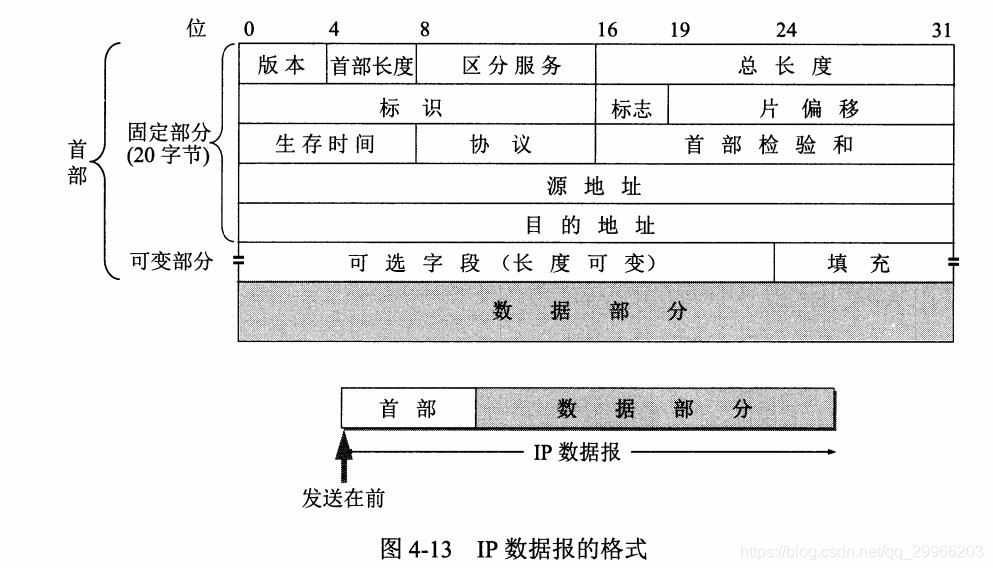
一个IP数据报由首部和数据两部分组成。首部的前一部分是固定长度,共20字节,是所有IP数据报必须具有的。在首部的固定部分的后面是一些可选字段,其长度是可变的。
- IP数据报的分片与重组
IP数据报作为网络层数据必然要通过帧来传输。一个数据报可能要通过多个不同的物理网络。每一个路由器都要将接收到的帧进行拆包和处理,然后封装成另外一个帧。每一种物理网络都规定了各自帧的数据域最大字节长度的最大传输单元。其中帧的格式与长度取决于物理网络所采用的协议。
分片、重组的基本方法——标识、标志和片偏移
在IP数据报的报头,与一个数据报的分片、组装相关的域有标识域、标志域和片偏移域
IP地址编址方式
- IPv4地址
TCP/IP协议的网络层使用的地址标识符叫做IP地址。IPv4中IP地址是一个32位的二进制地址,采用点分十进制。网络中的每一个主机或路由器至少有一个IP地址(连接到多个物理网络时,可以用有多个处于不同网络的IP地址)。在Internet中每个设备的IP地址全网唯一。 - 编址方式
第一阶段 1981:分类IP地址(2级结构)
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
IP 地址 ::= {< 网络号 >, < 主机号 >}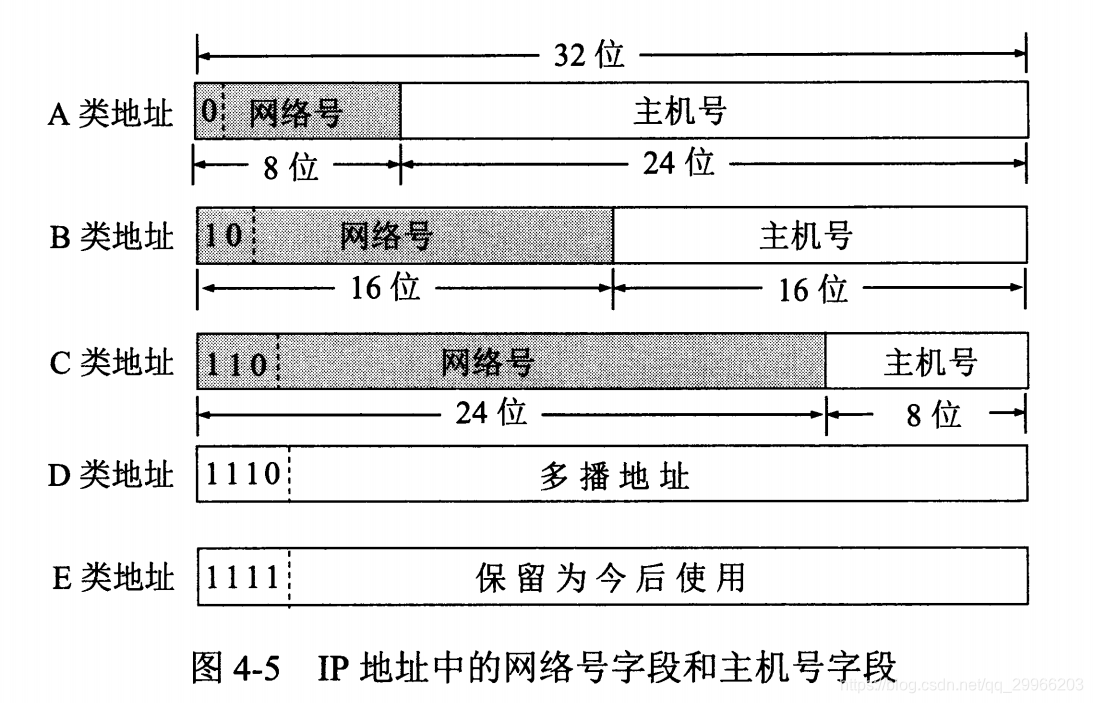
| 类别 | 地址范围 | 使用 |
|---|---|---|
| A类 | 0.0.0.0到127.255.255.255 | |
| B类 | 128.0.0.0到191.255.255.255 | |
| C类 | 192.0.0.0到223.255.255.255 | |
| D类 | 224.0.0.0到239.255.255.255 | 多用于组播,它并不指向特定的网络,多点广播地址用来一次寻址一组计算机,它标识共享同一协议的一组计算机(如直播) |
| E类 | 240.0.0.0到247.255.255.255 | 保留为今后使用 |
(1)IP地址是一种分等级的地址结构。好处在于:网络号由IP地址管理机构在分配IP地址时分配;主机号由得到该网络号的单位自行分配。且路由器仅根据目的主机所连接的网络号转发分组,减少路由表表项。
(2)IP地址标志一个主机(或路由器)和一条链路的接口。一个路由器应当连接到两个或多个网络上(将IP数据报从一个网络转发到另一个网络),因此一个路由器的每个接口都有一个不同网络号的IP地址。
(3)用转发器或网桥(链路层)连接起来的若干局域网仍为一个网络,因此这些局域网都具有相同的网络号。
(4)同一局域网上主机域路由器IP地址网络号必须相同(才能通过路由器转发数据 => 上网)
第二阶段 1985:子网划分(3级结构)
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。使一个大的网络(如A、B类网络划分成几个较小的网络)
注意,外部网络看不到子网的存在(划分子网属于单位内部的事 => 单位内部对分类得到地址()进一步进行划分)
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}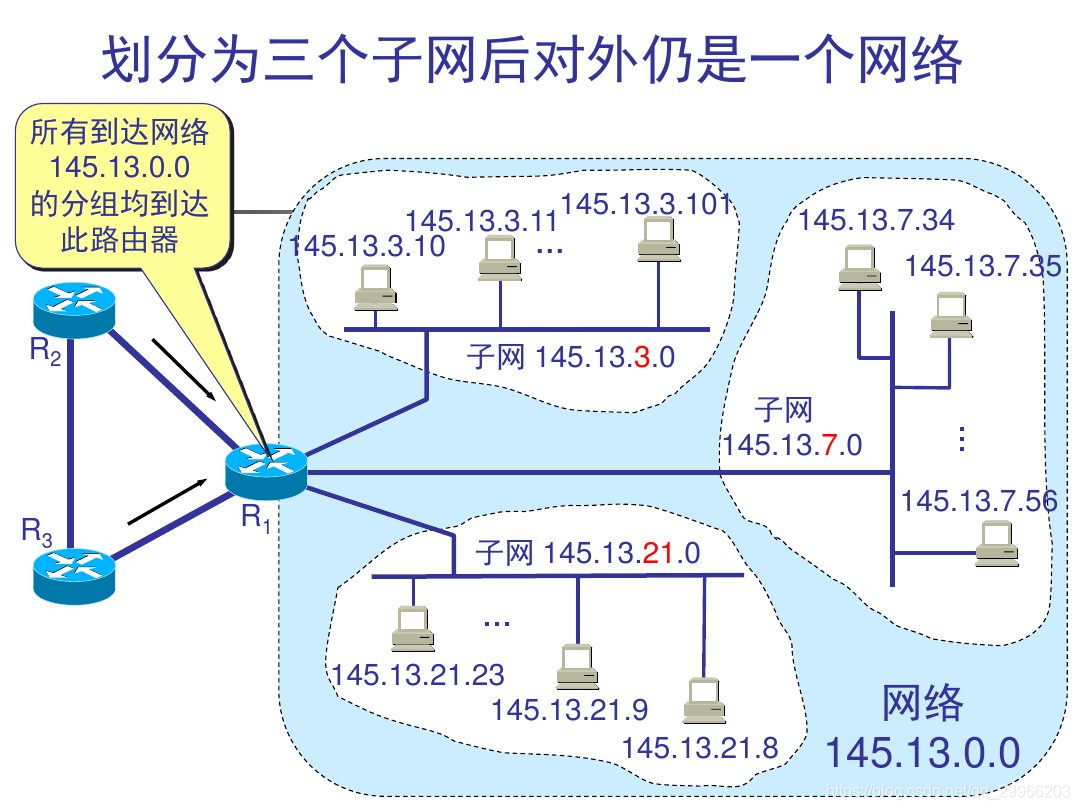
- 子网掩码
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。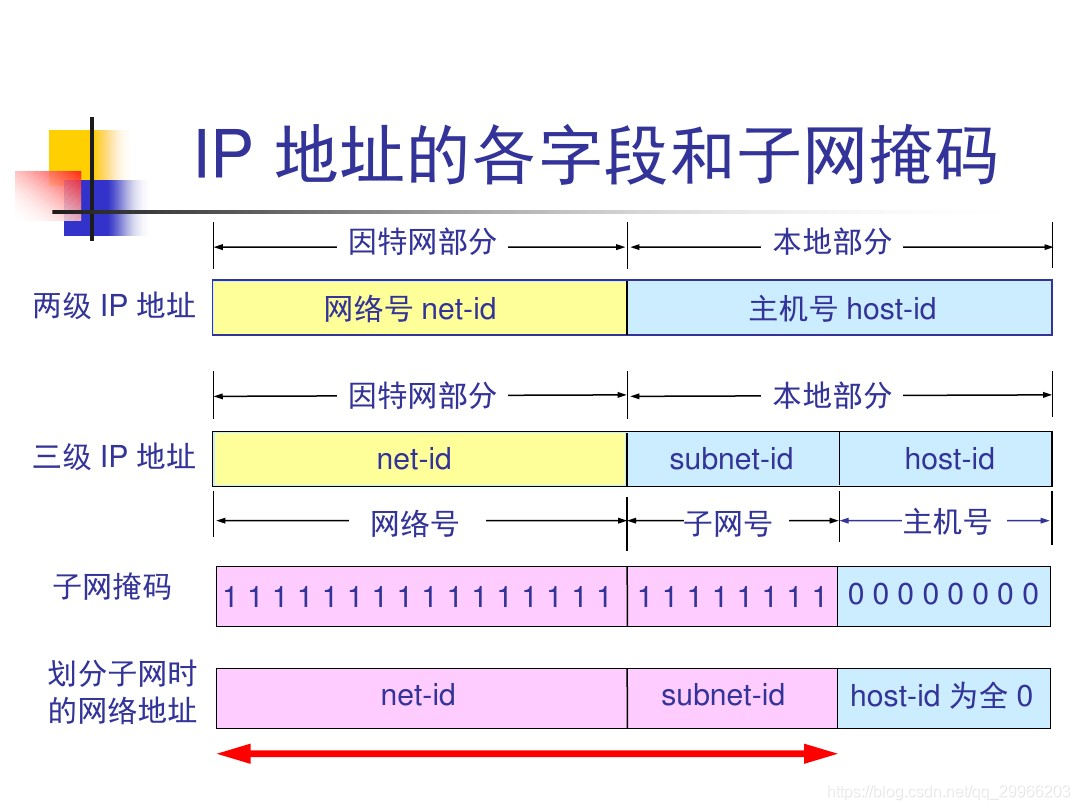
网络地址 = (IP地址) AND (子网地址)
划分子网的基本思路:根据子网中主机的个数最大值(保证为子网中所有主机分配IP地址) => 子网域位数
划分子网实例(重点):
某企业分配到一个C类IP地址201.222.5.0。假设需要6个子网,每个子网20台主机,给出网络规划。
(1)确定子网域位数,从主机借位:2^3-2=8-2 >= 6,从主机位借3位。
C类默认掩码255.255.255.0,即1111 1111.1111 1111.1111 1111.0000 0000
借3位后子网掩码 1111 1111.1111 1111.1111 1111.1110 0000 = 255.255.255.224
此时主机号5位,每个子网可以分配2^5 = 32 > 20台主机,满足要求。
分配的每个子网:000(X)、001、010、011、100、101、110、111(X)
- 划分子网情况下路由器转发分组算法
路由表的每一项:{目的网络地址、子网掩码、下一跳(下一跳地址、接口)}
(1)从分组的首部提取目的IP地址D;
(2)先用与该路由器直接相连的网络的子网掩码与D进行与运算,看结果是否与相应的网络
地址相匹配。若匹配,则进行直接交付。
否则就是间接交付,马上执行(3);
(3)若路由表中有一条到目的主机D的特定路由,则将分组转发给其指明的下一跳路由器。
否则执行(4);
(4)对路由表中每一行的子网掩码和D进行与运算,若结果与该行的目的网络地址匹配,则将
分组传给该行指明的下一跳路由器。
否则执行(5);
(5)若路由表中有一个默认路由,则将分组传给路由表中指明的默认路由器。
否则执行(6);
(6)报告转发分组出错。
第三阶段 1987:CIDR(无分类 / 网络前缀)
- 无分类编址
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化,用于代替分类地址中的网络号和子网号,使IP地址从三级编址回到了两级编址。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。 - 路由聚合、构成超网
网络前缀相同的连续IP地址 称为一个CIDR地址块。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。如/20地址块的掩码是20个连续的1。
一个 CIDR 地址块中有很多地址,一个 CIDR 地址块表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
目的地址D = 206.0.71.130 = 206.0.0100 0111.1000 0010
路由表中项目 : 206.0.68.0/22(ISP) 与目的地址匹配长度 = 22
206.0.71.128/25(四系) 与目的地址匹配长度 = 25
根据最长匹配原则,查找路由表中第二项
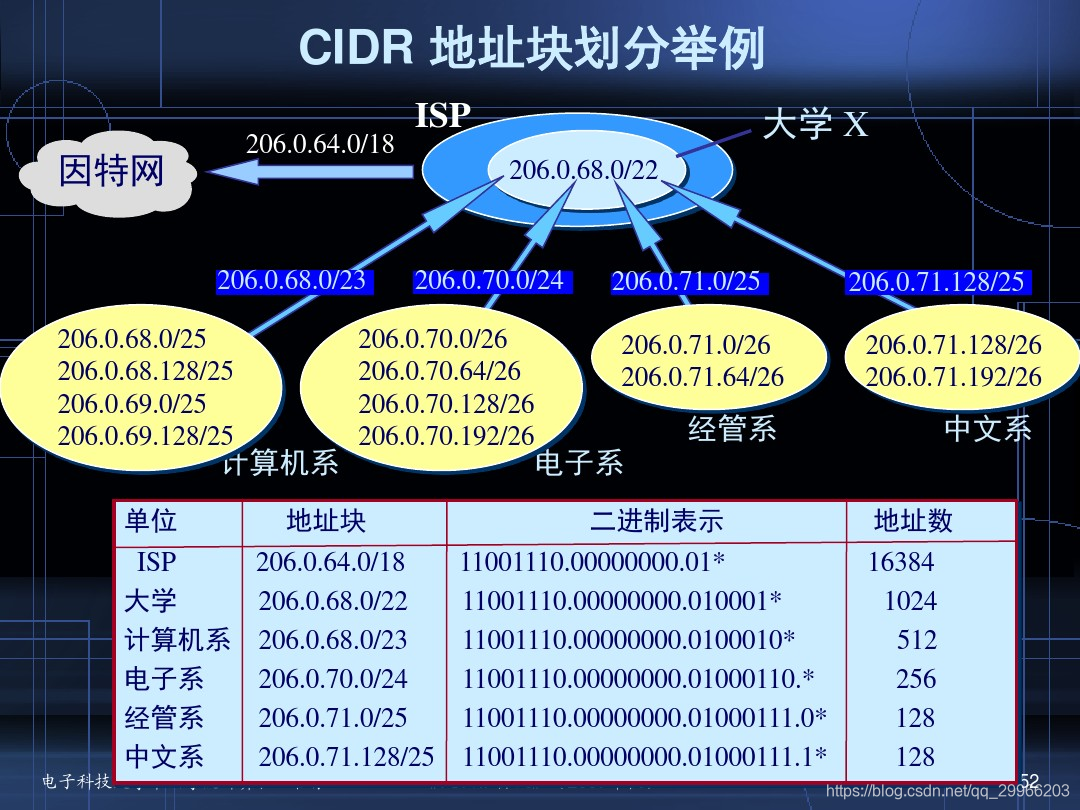
第四阶段 1994:NAT(地址转换)
需要在专用网连接到因特网的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器,它至少有一个有效的外部全球地址IP。所有使用本地地址的主机在和外界通信时都要在NAT路由器上将本地地址转化成IP地址才能和因特网连接。
- 专用/私有地址(RFC1918定义一系列私有地址)为只用于机构内部的网络或主机IP。Internet中的路由器不转发目的地址为私有地址的IP数据报
10.0.0.0 ~ 10.255.255.255(CIDR:10.0/8)
172.16.0.0 ~ 172.31.255.255(CIDR:172.16/12)
192.168.0.0 ~ 192.168.255.255(CIDR:192.168/16) - 公有地址:全网唯一IP地址,向ISP/注册中心申请,由因特网分配。
通过使用少量的公有IP 地址代表较多的私有IP 地址的方式,将有助于减缓可用的IP地址空间的枯竭。
- 工作原理
借助于NAT,私有(保留)地址的”内部”网络通过路由器发送数据包时,私有地址被转换成合法的IP地址,一个局域网只需使用少量IP地址(甚至是1个)即可实现私有地址网络内所有计算机与Internet的通信需求。
(1)内部主机ClientA用本地地址192.168.1.2和因特网主机202.20.65.4通信所发送数据报必须经过NAT路由器
(2)NAT路由器将数据报源地址192.168.1.2转换成全球地址202.20.65.2,目的地址保持不变,然后发送到因特网。
(3)NAT路由器收到因特网主机发回的数据报时,知道数据报中源地址是202.20.65.4,目的地址是202.20.65.2
(4)根据NAT转换表,NAT路由器将目的地址202.20.65.2转换为192.168.1.2,并转发给最终的内部主机ClientA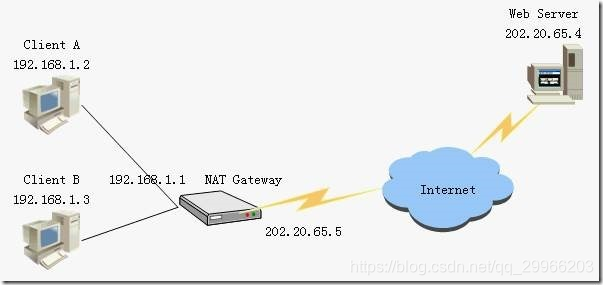
- IPv6
从计算机本身发展以及从因特网规模和网络传输速率来看,IPv4已不适用。最主要的问题就是32位的IP地址不够用。因此采用具有更大地址控件的新版本IP协议IPv6解决这个问题。(无类别编址CIDR、网络转换协议NAT也可解决地址耗尽问题)
IPv6的地址长度为128位,是IPv4地址长度的4倍,首部长度位固定40字节。于是IPv4点分十进制格式不再适用,采用十六进制表示。
相关协议
ARP 地址解析协议(Adress Resolution Protocol)
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。在实际网络的链路上传送数据帧时,最终使用硬件地址。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
ARP 实现由 IP 地址得到 MAC 地址。RARP实现由MAC地址得到IP地址。
实现(同一个局域网上路由器/主机)IP地址和MAC地址转换。
如果目的主机和源主机不在同一个局域网,应该通过ARP找到一个位于本局域网上某个路由器的硬件地址,通过分组发送给这个路由器,让这个路由器将分组转发给下一个网络。此时目的主机不变,源主机为该路由器的硬件地址,剩下工作交给下一个网络链路层处理。
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址。查找ARP 高速缓存中有没有该 IP 地址到 MAC 地址的映射
(1)如果有,查找出对应的MAC地址,并将该硬件地址写入MAC帧,就可以通过局域网将该MAC帧发送到此硬件地址。
(2)如果没有,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会通过单播的方式发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。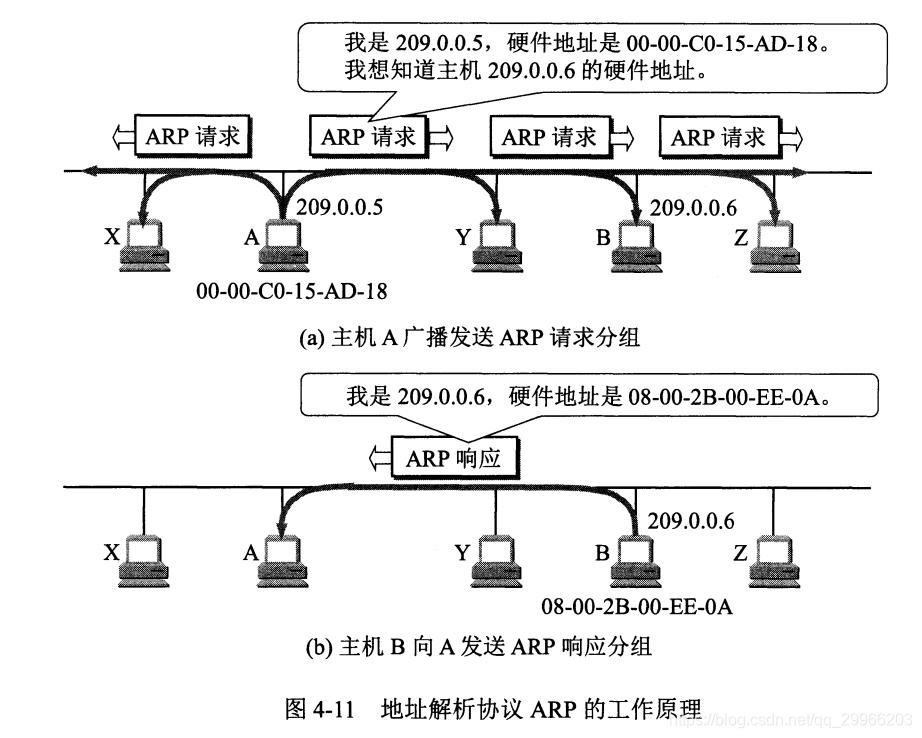
DHCP 动态主机设置协议(Dynamic Host Configuration Protocol)
动态主机配置协议DHCP提供即插即用连网机制。允许一台计算机加入新的网络和获取IP地址而不用手工参与。
- DHCP使用客户服务器方式,使用UDP传输数据
(1)需要IP地址的主机在启动时就向DHCP服务器广播发送发现报文(DHCPDISCOVER),这时主机就称为DHCP客户
(2)本地网络上所有主机都能收到此广播报文,但只有DHCP服务器才能回答此广播报文。
(3)DHCP服务器先在其数据库中查找该计算机的配置,若找到,则返回找到的信息。若找不到则从IP 地址池(address pool)中取出一个地址分配给该计算机。DHCP服务器的回答报文叫做提供报文(DHCPOFFER)
(4)DHCP客户 会检查得到的IP信息是否完整并发送广播DHCPREQUEST通知DHCP服务器已获得IP地址
(5)DHCP服务端发送广播DHCPACK确认客户的请求,表示分配成功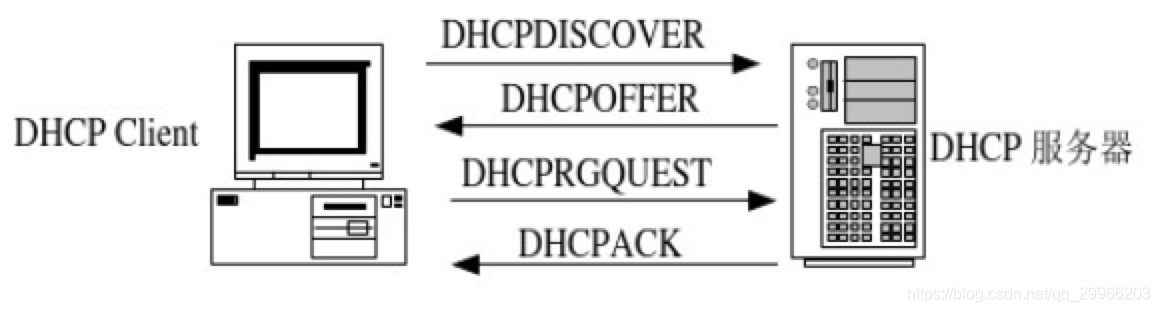
DHCP服务器分配给DHCP客户的IP地址是临时的,因此DHCP客户只能在一段有限的时间使用这个分配到的IP地址。这段有限的时间称为租用期。
ICMP 网络控制报文协议(Internet Control Message Protocol)
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。ICMP允许主机活路由器报告差错情况和提供异常情况的报告。它作为IP数据报的数据,加上数据报的首部,封装在 IP 数据报中,不属于高层协议。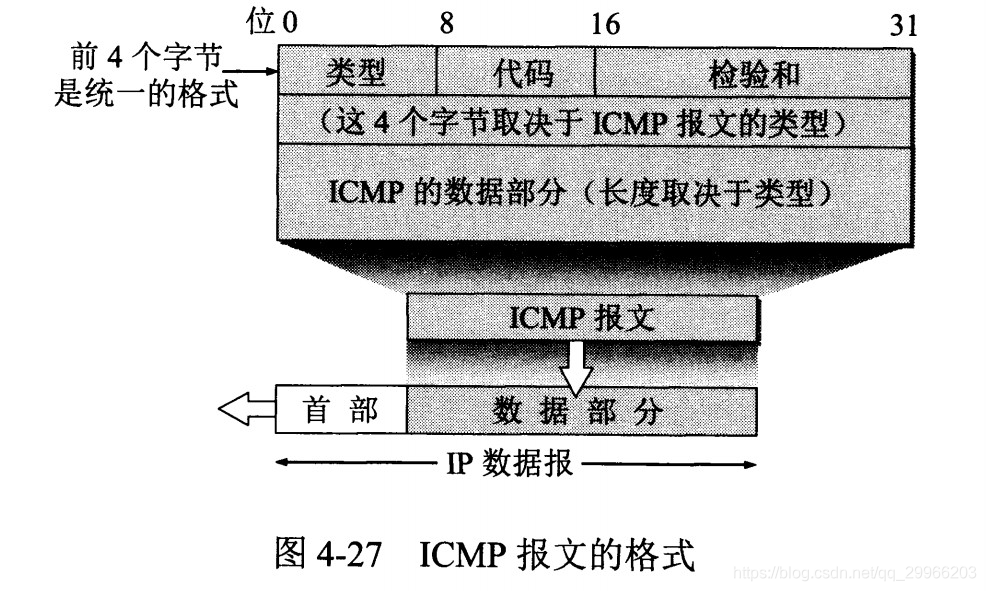
ICMP 报文分为差错报告报文和询问报文。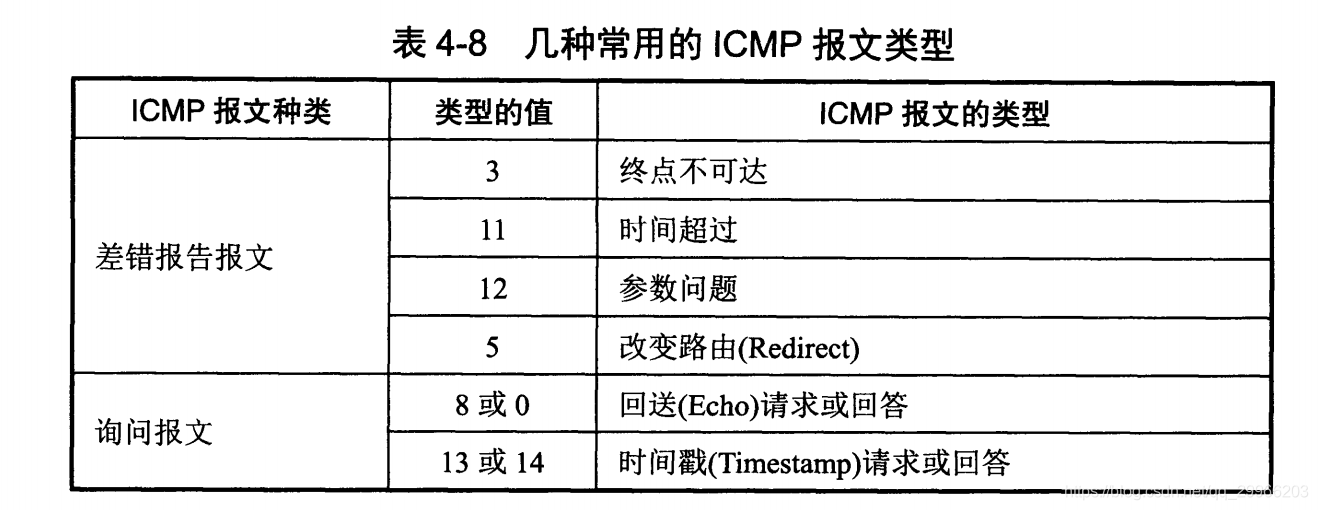
(1)Ping
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
(2)Traceroute
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
VPN 虚拟专用网
VPN 可以使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
- 专用地址
由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
有三个专用地址块:
10.0.0.0 ~ 10.255.255.255
172.16.0.0 ~ 172.31.255.255
192.168.0.0 ~ 192.168.255.255 - VPN 机制
VPN通过在公用网络上建立专用网络,进行加密通讯。VPN网关通过对数据包的加密和数据包目标地址的转换实现远程访问。VPN可通过服务器、硬件、软件等多种方式实现。
例如某公司员工出差到外地,他想访问企业内网的服务器资源,这种访问就属于远程访问。让外地员工访问到内网资源,利用VPN的解决方法就是在内网中架设一台VPN服务器。外地员工在当地连上互联网后,通过互联网连接VPN服务器,然后通过VPN服务器进入企业内网。为了保证数据安全,VPN服务器和客户机之间的通讯数据都进行了加密处理。有了数据加密,就可以认为数据是在一条专用的数据链路上进行安全传输,就如同专门架设了一个专用网络一样,但实际上VPN使用的是互联网上的公用链路,因此VPN称为虚拟专用网络,其实质上就是利用加密技术在公网上封装出一个数据通讯隧道。有了VPN技术,用户无论是在外地出差还是在家中办公,只要能上互联网就能利用VPN访问内网资源,这就是VPN在企业中应用得如此广泛的原因。
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。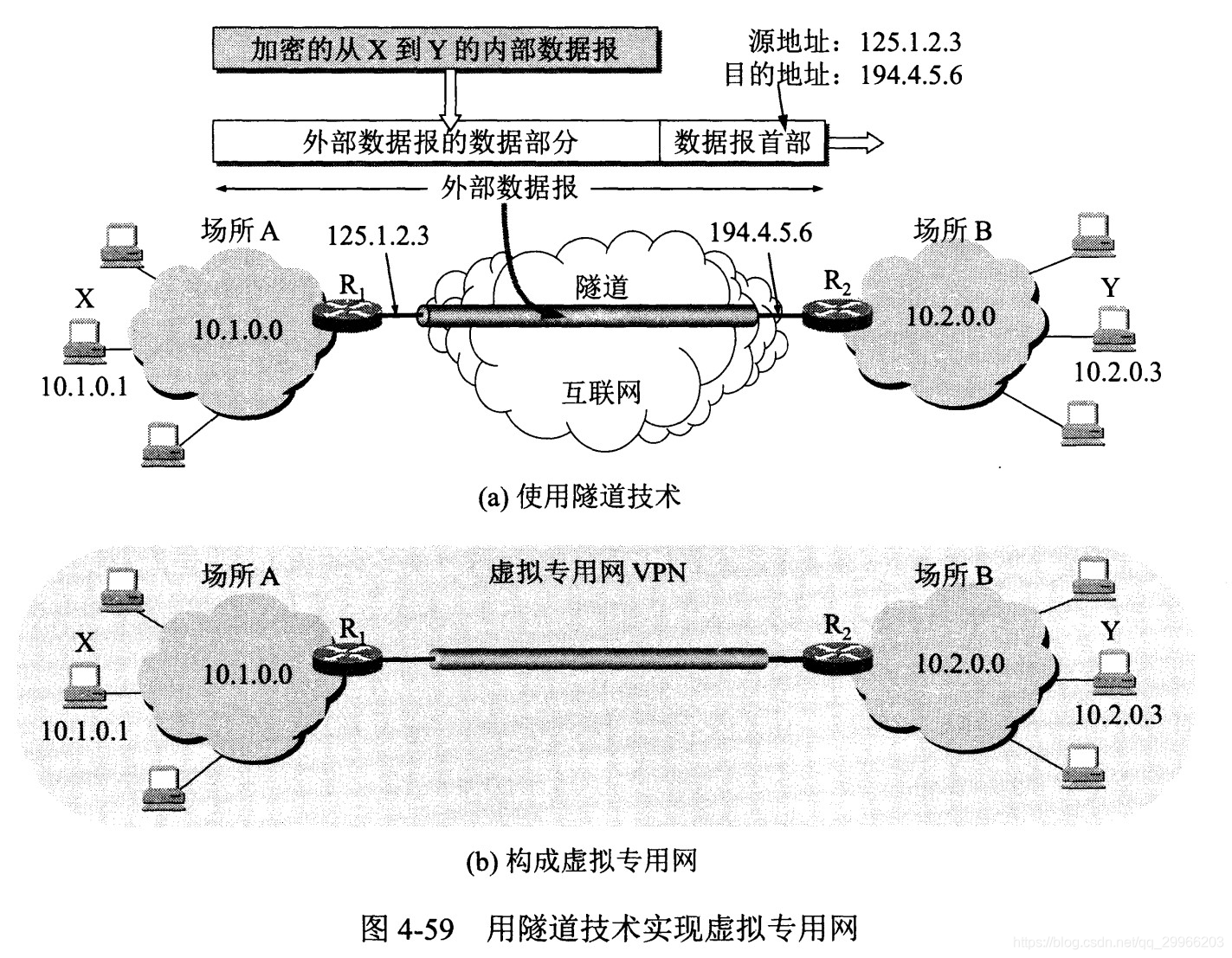
路由协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
自治系统(AS):一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位。这个网络单位可以是一个简单的网络也可以是一个由一个或多个普通的网络管理员来控制的网络群体,它是一个单独的可管理的网络单元(例如一所大学,一个企业或者一个公司个体)。一个自治系统有时也被称为是一个路由选择域(routing domain)。
内部网关协议IGP(RIP、OSPF)
- RIP
RIP 是一种基于距离向量的路由选择协议,要求网络中每一个路由器都要维护从自己到其他每一个目的网络的距离记录。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表全部信息,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
RIP认为一个好的路由就是通过的路由器数目少,即距离短。
距离向量算法:
对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
对修改后的 RIP 报文中的每一个项目,进行以下步骤:
若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。且有”坏消息传播慢”这一问题。 - ODPF
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
OSPF 具有以下特点:
(1)向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
(2)发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
(3)只有当链路状态发生变化时,路由器才会发送信息。
(4)所有路由器都具有全网的拓扑结构图,并且是一致的(链路状态数据库的同步)。相比于 RIP,OSPF 的更新过程收敛的很快。
外部网关协议EGP(BGP)
- BGP
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
(1)互联网规模很大;
(2)各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
(3)AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置至少一个 BGP 发言人,两个BGP发言人都是通过一个共享网络连接在一起的,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息(使用TCP连接能提供可靠服务,保证数据可达)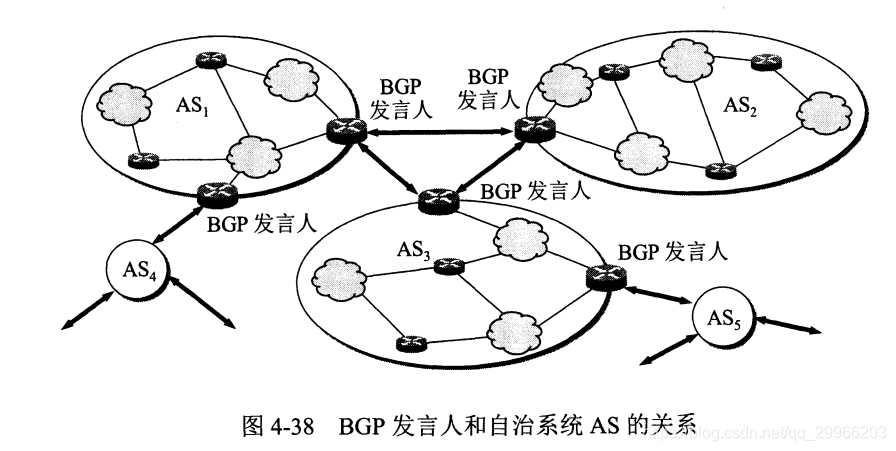
网络层设备:路由器
路由器的组成与功能
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是路由选择和转发分组。
- 转发
转发就是路由器根据路由/转发表将用户的IP数据报从合适的端口转发出去。 - 路由选择
按照分布式算法根据从各相邻的路由器得到关于网络拓扑的变化情况,动态地改变所选择地路由。路由表是根据李由选择算法得出地。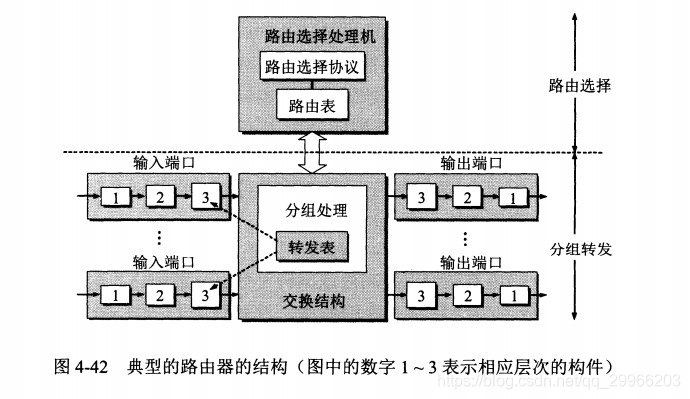
四. 传输层
传输层的目标是向应用层应用程序进程之间的通信,提供有效、可靠、保证质量的服务;
传输层在网络分层结构中起着承上启下的作用,通过执行传输层协议,屏蔽通信子网(信息传输)在技术、设计上的差异和服务质量的不足,向资源子网(信息处理)提供一个标准的、完善的通信服务;
传输层提供端到端(主机的应用进程之间)的通信
网络层提供点到点(主机之间)的通信
传输层寻址 && 端口
端口用一个16位端口号进行标志,只具有本地意义,即端口号只是为了标志本计算机应用层中的各个进程,作为通信的终点。
TCP && UDP
TCP/UDP 特点
- 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
- 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
首部格式
- UDP 首部格式
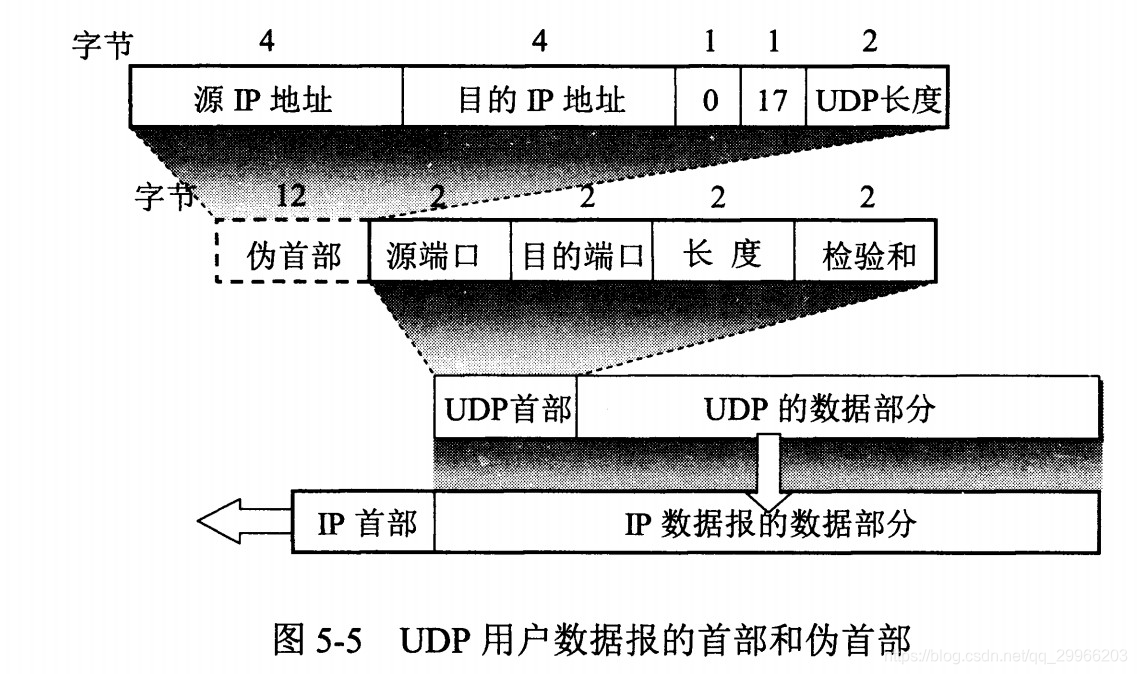
首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。 - TCP 首部格式
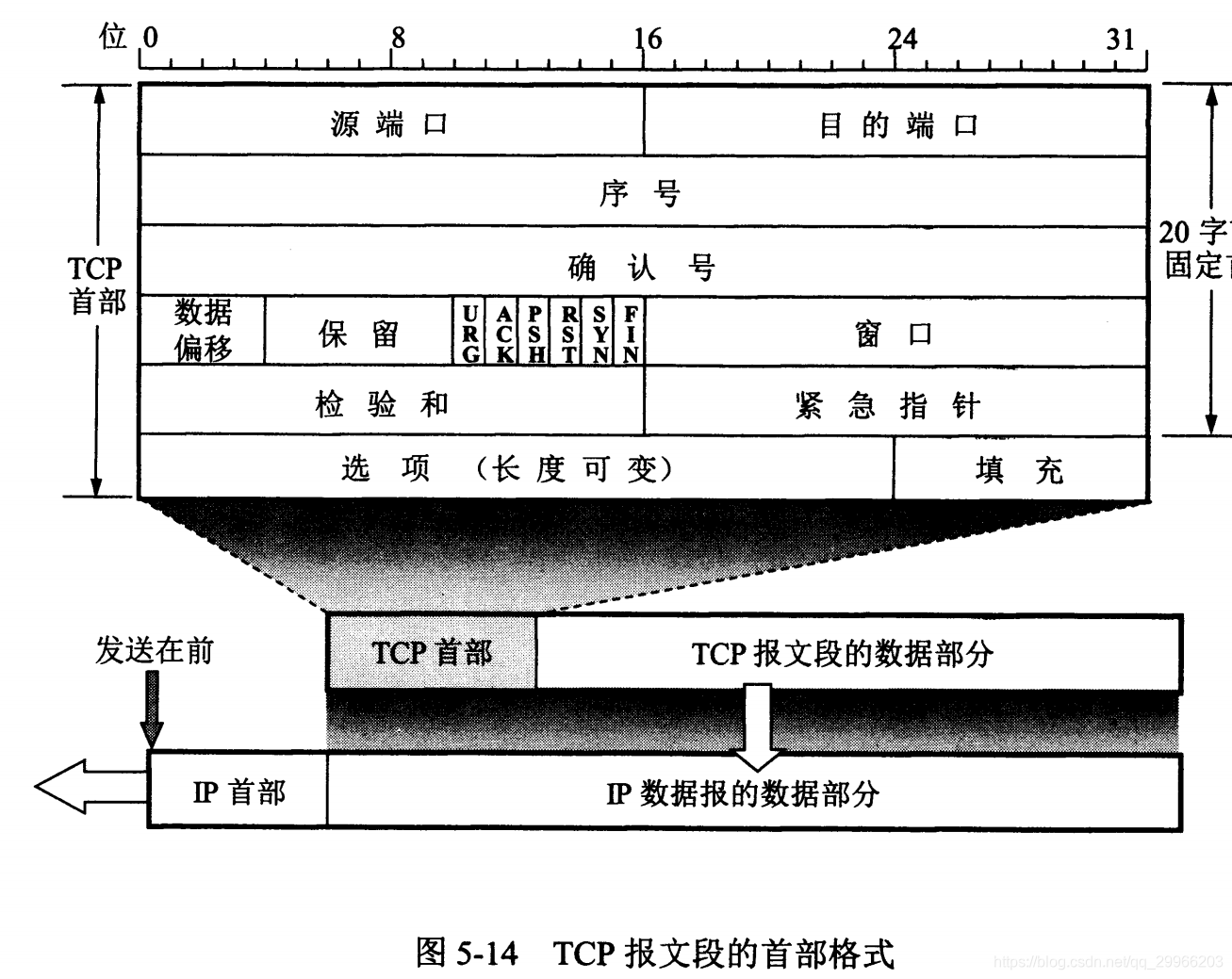
序号 :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
确认号 :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
数据偏移 :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
同步 SYN :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
终止 FIN :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
窗口 :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
三次握手 & 四次挥手
[第五章 网络 之 TCP/IP][_ _ TCP_IP]
TCP可靠传输
超时重传
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
滑动窗口
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。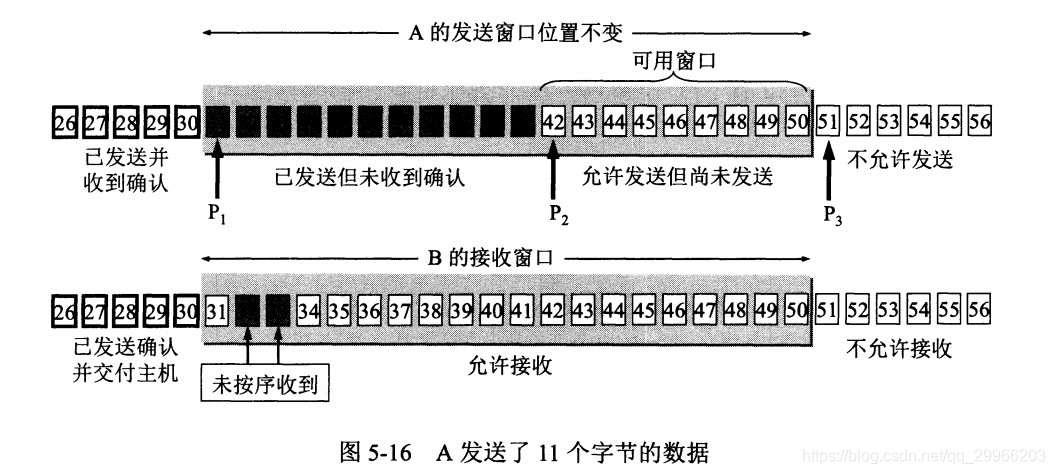
流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
拥塞控制
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。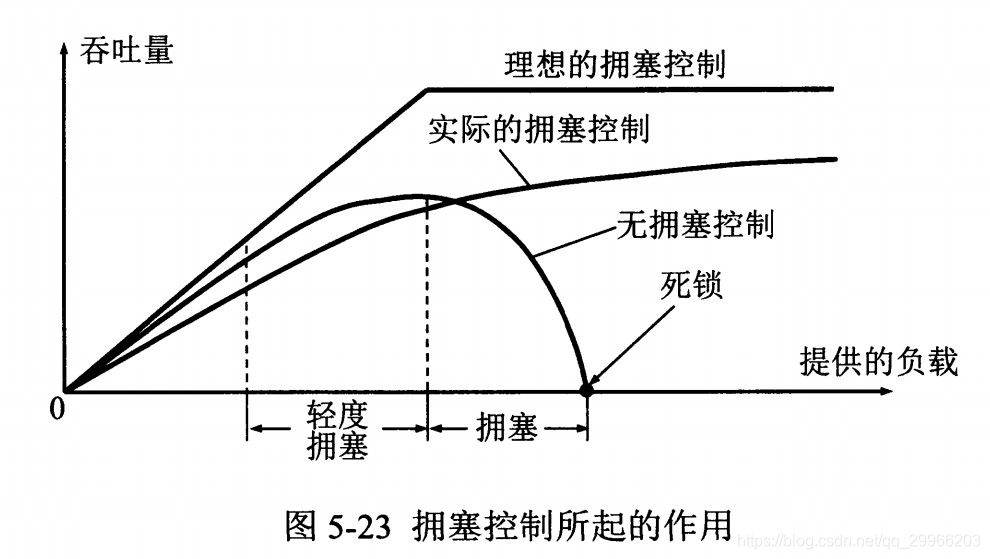
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
为了便于讨论,做如下假设:
接收方有足够大的接收缓存,因此不会发生流量控制;
虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。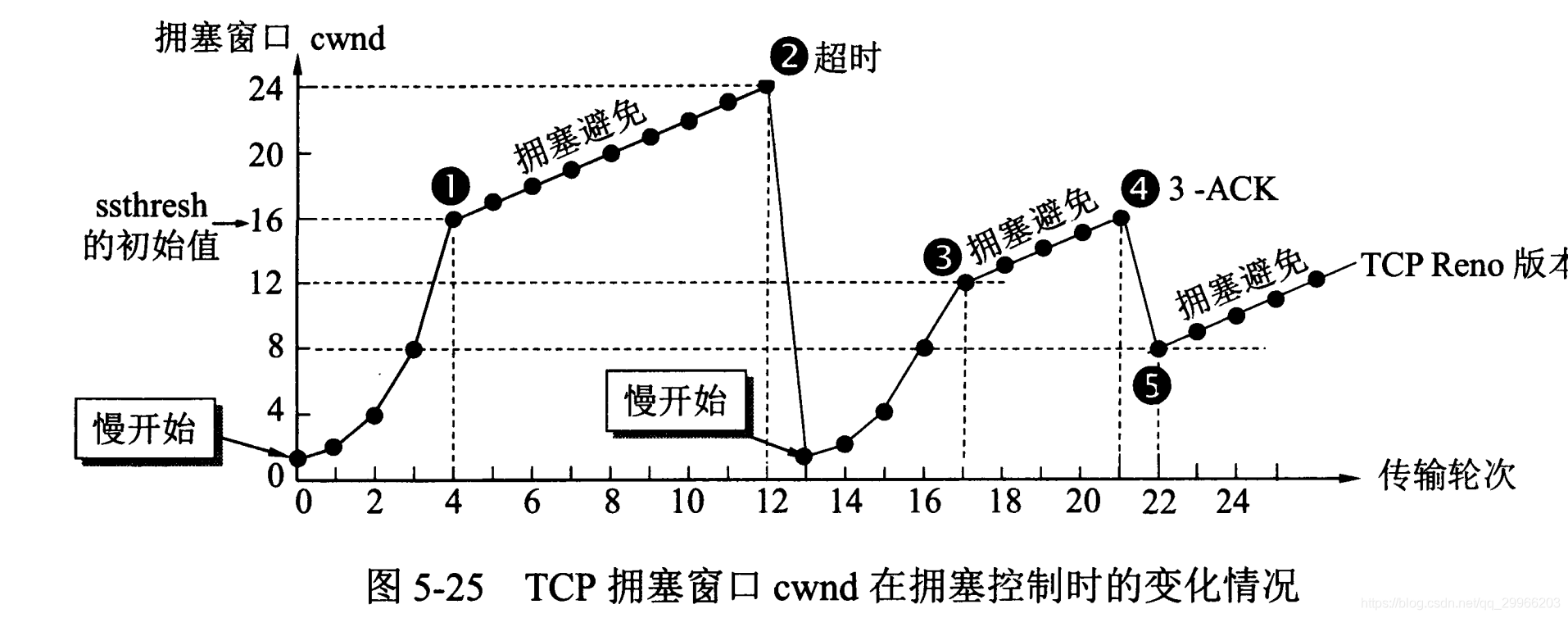
- 慢开始与拥塞避免
发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 …
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。 - 快重传与快恢复
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。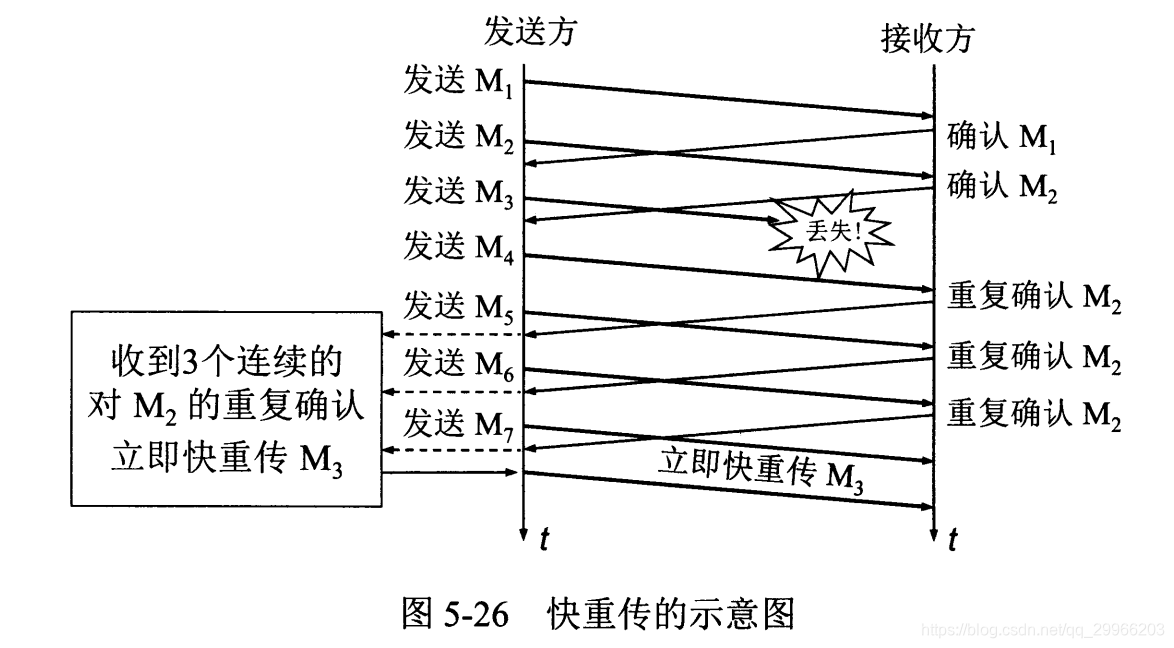
五. 应用层
网络应用模型
在网络应用层运行的应用程序之间通信方式可划分成两大类:
C/S(客户端/服务器)方式
客户client和服务器server都是指通信中所设计的两个应用进程。客户服务器方式所描述的是进程之间服务和被服务的关系。客户是服务的请求方,服务器是服务的提供方。
P2P(peer to peer 对等)方式
对等连接是指两个主机在通信时并不区分哪一个是服务请求方,提供方。只要两个主机运行了对等连接软件,它们就可以进行平等的、对等连接通信。双方都可以下载对方已经存储在硬盘中的共享文档。
相关协议
DNS系统
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用UDP端口53。
因特网采用层次结构的命名树作为主机的名字,并使用分布式域名系统DNS。
名字到IP地址的解析是由若干个域名服务器完成。域名服务器在专设的结点上运行,运行该程序的机器称为域名服务器。
DNS基于UDP协议实现:DNS的一个客户向本地域名服务器发送域名解析请求(UDP报文),其中包含待解析的域名,本地域名服务器在查找域名后,返回应答报文,其中包含对应的IP地址。
- 层次域名空间
- 域名
因特网采用了层次树状结构的命名方法,任何一个连接在因特网上的主机活路由器,都有一个唯一的层次结构的名称,即域名。
域名的结构由标号序列组成,各标号分别代表不同层次的域名,每个层次只需要负责该层次级别的独立功能(层次之间相互独立),各标号之间用点隔开:
- 因特网的域名空间
- 域名服务器
树状结构的DNS域名服务器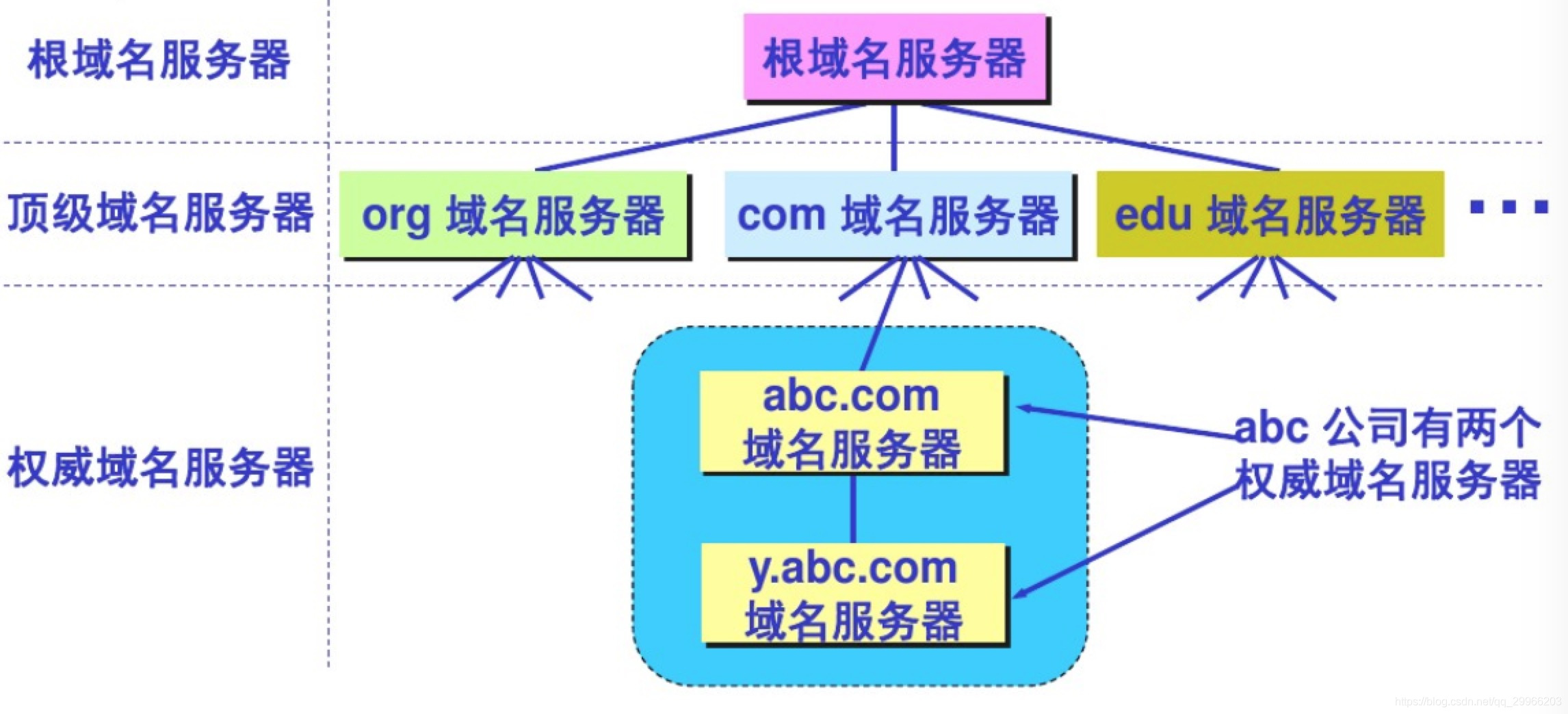
域名服务器四种类型
(1)根域名服务器:13个(A~M)。在使用迭代查询时,根域名服务器把下一步应当查找的顶级域名服务器的IP地址告诉本地域名服务器。
(2)顶级域名服务器:负责顶级域名和所有国家域名。
(3)权威DNS服务器:在因特网上具有公共可访问主机(如Web服务器和邮件服务器)的每个组织机构必须提供公共可访问的DNS记录,这些记录将这些主机的名字映射为IP地址。
当一个权威域名服务器还不能给出最后的查询回答时,就会告诉发出查询请求的DNS客户,下一步应该查找哪一个权威域名服务器。多数大学、企业实现和维护他们自己的权威DNS服务器。
(4)本地域名服务器:当一个主机发出DNS查询请求时,这个查询报文就发送给本地域名服务器。 - 域名解析过程
主机向本地域名服务器的查询一般采用递归查询。如果主机所询问的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以DNS客户的身份,向其他根域名服务器继续发出查询请求报文。
本地域名服务器向根/顶级/权威域名服务器的查询通常是采用迭代查询。当根域名服务器收到本地域名服务器查询请求报文时,要么给出所要查询的IP地址,要么告诉本地域名服务器下一步应当向哪一个域名服务器进行查询,然后让本地域名服务器进行后续查询。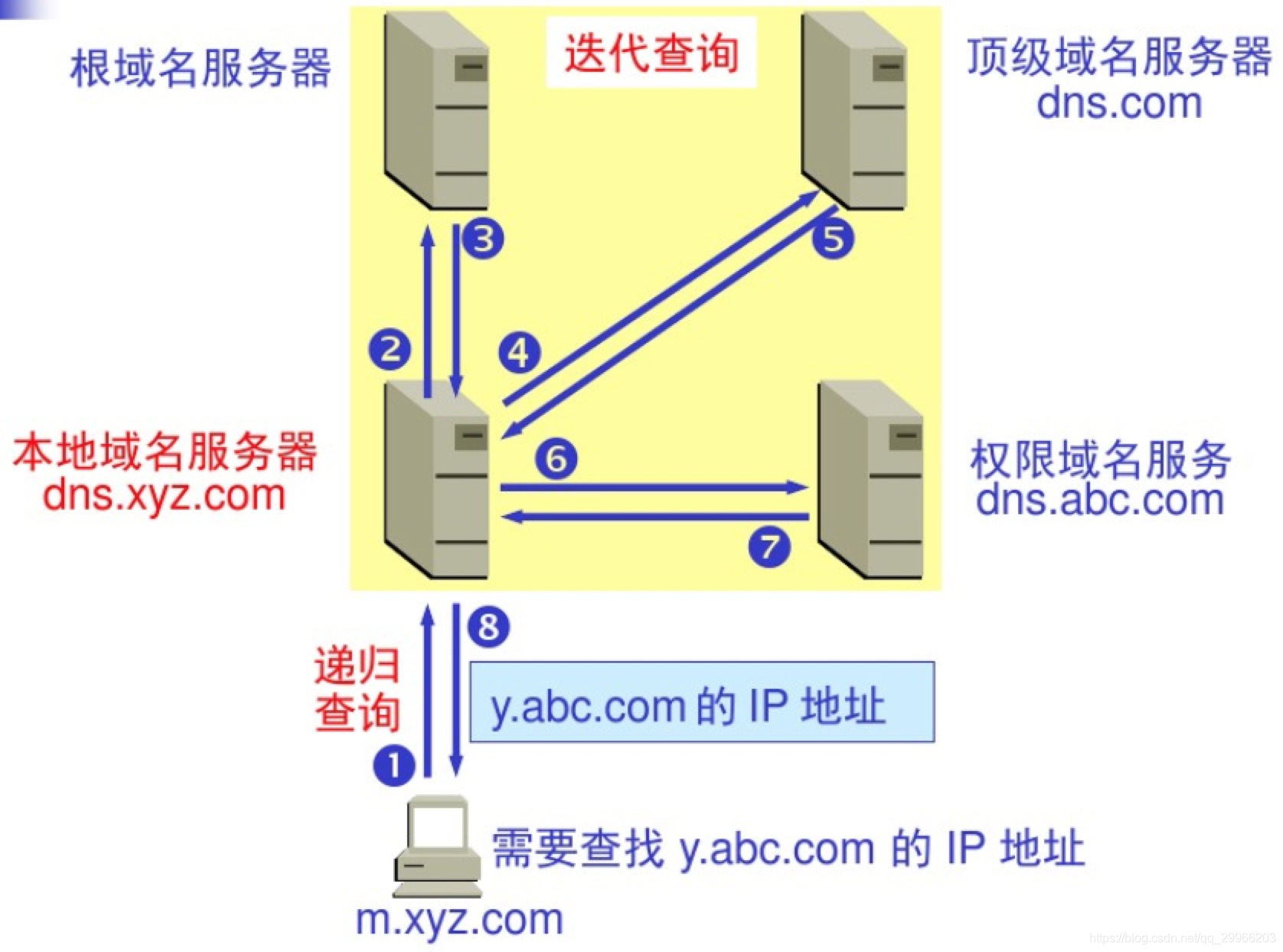
FTP
文件传送协议FTP只提供文件传送的一些基本的服务,它使用TCP可靠的运输服务。FTP的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。
FTP使用客户服务器方式。一个FTP服务器进程可同时为多个客户进程提供服务。FTP的服务器进程由两大部分组成:一个主进程,负责接收新的请求;另外有若干个从属进程,负责处理单个请求。
FTP 两个连接
- 控制连接(20端口)
当用户主机与远程主机开始一个FTP会话前,FTP的客户机端(用户)在21端口发起一个用于控制的与服务器(远程主机)的TCP连接。
控制连接在整个会话期间一直保持打开,FTP客户发出的传送请求通过控制连接发送给服务器端的控制进程,但控制连接不用于传送文件。 - 数据连接(21端口)
当FTP服务器端从该连接上收到一个文件传输的命令后,就发起20端口到客户机的数据连接。数据连接用于传输文件。FTP在该数据连接上准确地传送一个文件并关闭连接。
电子邮件(SMTP、POP3、IMAP)
电子邮件系统的组成结构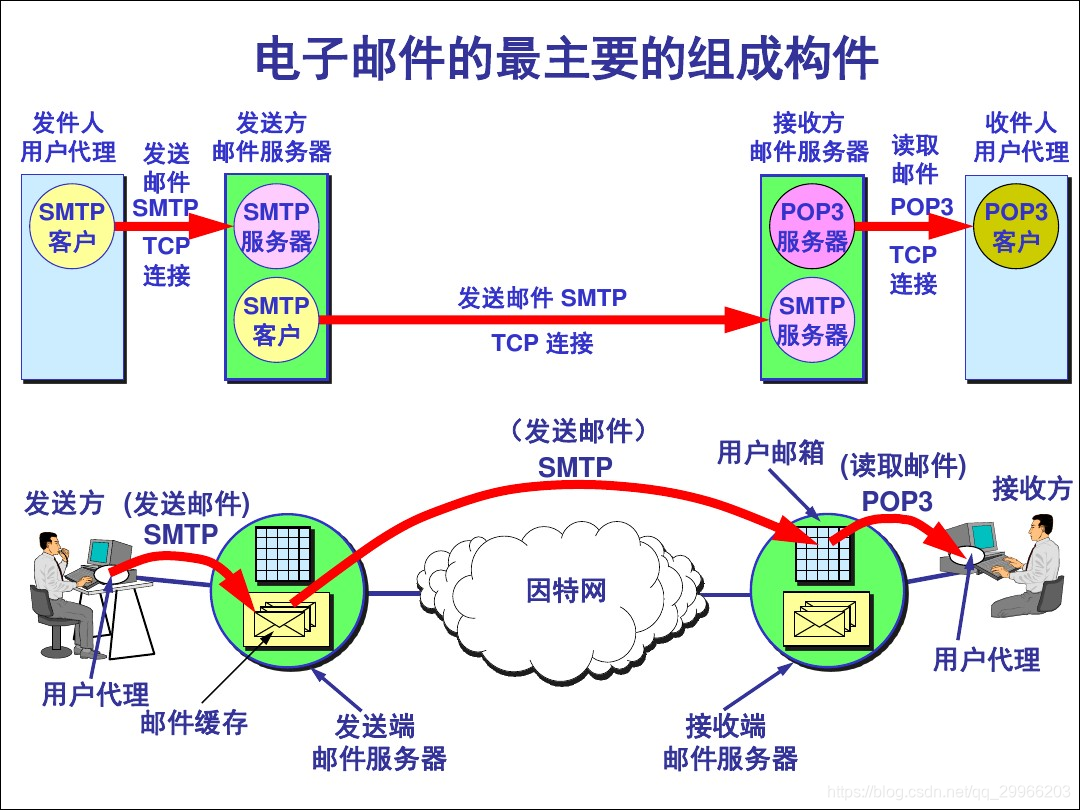
(1)用户代理(UA)
用户与电子邮件系统的接口,是电子邮件客户端软件。用户代理的功能:撰写、显示、处理和通信。
(2)邮件服务器(MS)
发送和接收邮件,同时还要向发信人报告邮件传送的情况(已交付、被拒绝、丢失等)。邮件服务器按照客户/服务器方式工作。邮件服务器需要使用发送和读取两个不同协议。
- 发送邮件协议:SMTP
使用TCP可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件,也用来将邮件从发送方的用户代理传送到发送方的邮件服务器。限制邮件报文主体部分只能采用简单的7位ASCII码表示。
为发送非ASCII文本的内容,发送方的用户代理可在报文中使用附加的首部行,即多用途因特网邮件扩展(MIME)
MIME 在其邮件首部说明了邮件数据类型(如文本、声音、图像、视频等),使用MIME可在邮件中同时传送多种类型的数据。 - 读取邮件协议:POP3
POP3允许用户从服务器上把邮件存储到本地主机(即自己的计算机)上,同时删除保存在邮件服务器上的邮件。 - 读取邮件服务器:IMAP
IMAP全称是Internet Mail Access Protocol,即交互式邮件存取协议,它是跟POP3类似邮件访问标准协议之一。不同的是,开启了IMAP后,您在电子邮件客户端收取的邮件仍然保留在服务器上,同时在客户端上的操作都会反馈到服务器上,如:删除邮件,标记已读等,服务器上的邮件也会做相应的动作。所以无论从浏览器登录邮箱或者客户端软件登录邮箱,看到的邮件以及状态都是一致的。 - POP3与IMAP区别
POP3协议允许电子邮件客户端下载服务器上的邮件,但是在客户端的操作(如移动邮件、标记已读等),不会反馈到服务器上,比如通过客户端收取了邮箱中的3封邮件并移动到其他文件夹,邮箱服务器上的这些邮件是没有同时被移动的 。
而IMAP提供webmail 与电子邮件客户端之间的双向通信,客户端的操作都会反馈到服务器上,对邮件进行的操作,服务器上的邮件也会做相应的动作。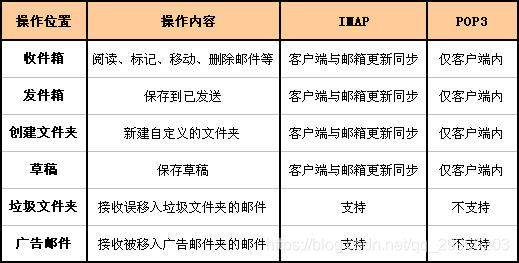
总之,IMAP 整体上为用户带来更为便捷和可靠的体验。POP3 更易丢失邮件或多次下载相同的邮件,但 IMAP 通过邮件客户端与webmail 之间的双向同步功能很好地避免了这些问题。
WWW(HTTP)
- 万维网
万维网以客户服务器方式工作。
浏览器就是在用户计算机上的万维网客户程序。万维网文档所驻留的计算机则运行服务器程序,这个计算机也称为万维网服务器。
客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所需要的万维网文档。在一个客户程序主窗口上显示出的万维网文档称为页面(page)。
万维网使用统一资源定位符URL来标志万维网上的各种文档,使每一个文档在整个因特网的范围具有唯一的标识符URL。 - HTTP
Web的应用层协议是超文本传输协议HTTP。定义了HTTP报文的格式以及客户端服务器如何进行报文交换。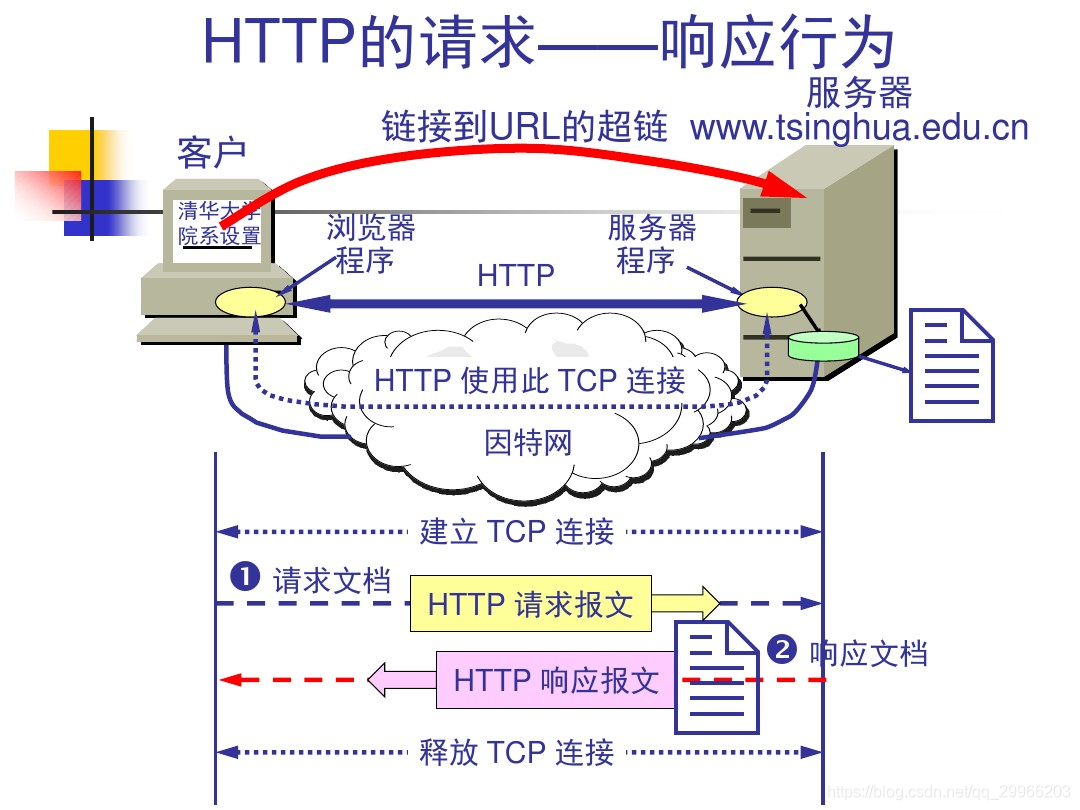
用户点击鼠标后发生的事件
Telent
Telnet协议是TCP/IP协议族中的一员,是Internet远程登录服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制Web服务器的方法。
面试
MAC / IP地址 & 作用?
- mac地址 & ip地址?
| mac地址 | ip地址 | |
|---|---|---|
| 定义 | 物理/硬件地址,由网络设备制造商生产时写在硬件内部 | 网络地址 |
| 格式 | 08:00:20:0A:8C:6D 长度为48位(6个字节),通常表示为12个16进制数,每2个16进制数之间用冒号隔开 |
192.168.0.1 长度为32位。用点分隔开的4个8八位组构成 |
| 组成 | 前6位16进制数08:00:20代表网络硬件制造商的编号,它由IEEE分配,而后3位16进制数0A:8C:6D代表该制造商所制造的某个网络产品(如网卡)的系列号 | IP地址由网络地址和主机地址两部分组成,分配给这两部分的位数随地址类(A类、B类、C类等)的不同而不同。网络地址用于路由选择,而主机地址用于在网络或子网内部寻找一个单独的主机 |
| 所属层 | 数据链路层 | 网络层 |
| 说明 | 每个网络制造商必须确保它所制造的每个以太网设备都具有相同的前三个字节以及不同的后三个字节。这样就可保证世界上每个以太网设备都具有唯一的MAC地址。MAC地址与网络无关。 | IP地址只是逻辑上的标识,用于路由器将数据从源地址传送到目的地址。会根据网络而变化,也可以被用户任意修改 |
- MAC地址的作用?
- 既然每个以太网设备在出厂时都有一个唯一的MAC地址了,那为什么还需要为每台主机再分配一个IP地址呢?=> IP地址作用?
(1)IP地址的分配是根据网络的拓朴结构,而不是根据谁制造了网络设置。若将高效的路由选择方案建立在设备制造商的基础上而不是网络所处的拓朴位置基础上,这种方案是不可行的。
(2)当存在一个附加层的地址寻址时,设备更易于移动和维修。例如,如果一个以太网卡坏了,可以被更换,而无须取得一个新的IP地址。如果一个IP主机从一个网络移到另一个网络,可以给它一个新的IP地址,而无须换一个新的网卡。 - 为什么每台主机都分配唯一的IP地址了,为什么还要在网络设备(如网卡,集线器,路由器等)生产时内嵌一个唯一的MAC地址呢?=> mac地址作用?
这是由组网方式决定的,如今比较流行的接入Internet的方式(也是未来发展的方向)是把主机通过局域网组织在一起,然后再通过交换机和 Internet相连接。这样一来就出现了如何区分具体用户,防止盗用的问题。由于IP只是逻辑上标识,任何人都随意修改,因此不能用来标识用户;而 MAC地址则不然,它是固化在网卡里面的。
基于MAC地址的这种特点,局域网采用了用MAC地址来标识具体用户的方法。 - 因此计算机的通信,需要 MAC地址 与 IP地址 结合 传送数据包
无论是局域网,还是广域网中的计算机之间的通信,最终都表现为将数据包从某种形式的链路上的初始节点出发,从一个节点传递到另一个节点,最终传送到目的节点。数据包在这些节点之间的移动都是由ARP(Address Resolution Protocol:地址解析协议)负责将IP地址映射到MAC地址上来完成的(交换机内部通过”表”将MAC地址与IP地址一一对应实现绑定)。
假设网络上要将一个数据包(名为PAC)由临沭的一台主机(名称为A,IP地址为IP_A,MAC地址为MAC_A)发送到北京的一台主机(名称为B,IP地址为IP_B,MAC地址为MAC_B)。这两台主机之间不可能是直接连接起来的,因而数据包在传递时必然要经过许多中间节点(如路由器,服务器等等),我们假定在传输过程中要经过C1、C2、C3(其MAC地址分别为M1,M2,M3)三个节点。
A在将PAC发出之前,先发送一个 ARP(Address Resolution Protocol:地址解析协议)请求,找到其要到达IP_B所必须经历的第一个中间节点C1的MAC地址M1,然后在其数据包中封装(Encapsulation)这些地址: IP_A、IP_B,MAC_A和M1。当PAC传到C1后,再由ARP根据其目的IP地址IP_B,找到其要经历的第二个中间节点C2的MAC地址 M2,然后再将带有M2的数据包传送到C2。如此类推,直到最后找到带有IP地址为IP_B的B主机的地址MAC_B,最终传送给主机B。在传输过程中, IP_A、IP_B和MAC_A不变,而中间节点的MAC地址通过ARP在不断改变(M1,M2,M3),直至目的地址MAC_B。
具体的通信方式:接收过程,当有发给本地局域网内一台主机的数据包时,交换机接收下来,然后把数据包中的IP地址按照“表”中的对应关系映射成MAC地址,转发到对应的MAC地址的主机上,这样一来,即使某台主机盗用了这个IP地址,但由于他没有这个MAC地址,因此也不会收到数据包。
描述一次网络请求的流程/浏览器访问一个url网址所经历的过程?
- 域名解析(DNS查找)
- 建立TCP连接(TCP的三次握手和四次挥手)
- 建立TCP连接后客户端向服务端发起HTTP请求(HTTP请求报文:请求行、请求头、空行、消息体)
- 服务器接受并处理请求,并返回HTTP响应消息,HTTP响应报文的消息体为服务端返回给客户端的HTML文本内容(或其他格式数据)(HTTP响应报文:状态行、响应头、空行、消息体)
- 浏览器解析HTML代码,同时请求HTML代码中的静态资源(如js、css、图片等)
遇到js/css/image等静态资源时,向服务器端发起一个HTTP请求,如果服务器端返回304状态码(告诉浏览器服务器端没有修改该资源),那么浏览器会直接读取本地的该资源的缓存文件。否则开启新线程向服务器端去请求下载。(这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源。) - 最后浏览器使用请求到的静态资源和HTML代码对页面进行渲染并呈现给用户
什么是DNS?作用是什么?工作机制?
DNS(Domain Name System)域名系统,用于进行域名解析的服务器,即进行域名与IP地址转换。
DNS查询过程
以查询 zh.wikipedia.org 为例:
- 输入域名”zh.wikipedia.org”,操作系统会先检查自己的本地hosts文件是否有这个网址映射关系。如果hosts没有这个域名的映射,则查询本地DNS解析器缓存。如果hosts与本地DNS服务器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器。
- 客户端发送查询报文”query zh.wikipedia.org”至DNS服务器,DNS服务器首先检查自身缓存,如果存在记录则直接返回结果。
- 如果记录老化或不存在,则:
- DNS服务器向根域名服务器发送查询报文”query zh.wikipedia.org”,根域名服务器返回顶级域.org 的权威域名服务器地址。
- DNS服务器向 .org 域的权威域名服务器发送查询报文”query zh.wikipedia.org”,得到二级域.wikipedia.org 的权威域名服务器地址。
- DNS服务器向 .wikipedia.org 域的权威域名服务器发送查询报文”query zh.wikipedia.org”,得到主机 zh 的A记录,存入自身缓存并返回给客户端。
从上图可以知道,客户端到本地DNS服务器是属于递归查询(只发送一次请求,得到一次准确结果(消耗资源)),而DNS服务器之间的交互查询就是迭代查询(发送多次请求,得到参考结果)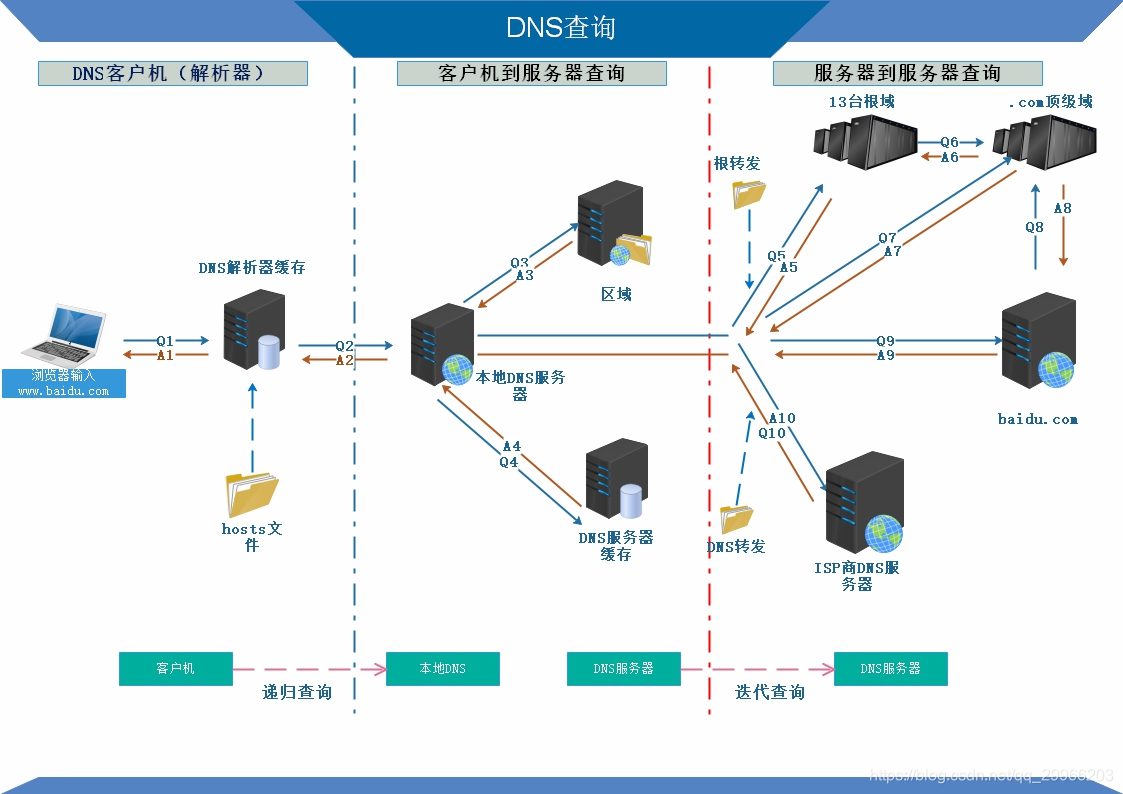
第五章 网络 之 TCP/IP
- TCP
- 什么是TCP协议?UDP协议?它们的区别?
- 说一下TCP/IP三次握手,四次挥手的具体细节?
- HTTP
- 描述一下HTTP协议?
- HTTP请求/响应报文?
- HTTP方法?(请求报文)
- 面试:POST与GET区别?
- HTTP状态码?(响应报文)
- HTTP首部?(请求 & 响应首部常用字段)
- HTTP 缓存机制?
- 浏览器缓存机制:cookie/session
- HTTP1.0 & HTTP1.x & HTTP2.0区别是什么?
- HTTPS
- 描述一下HTTPS?
- HTTPS 工作原理 / 连接 & 通信过程?
- HTTPS与HTTP区别?
- 对称加密 & 非对称加密?
- Socket
- 描述一下Socket?
- Socket 通信模型 / 原理 / 连接过程?
- Socket 使用?
- 描述一下WebSocket?
- Socket & WebSocket & HTTP 对比?
- 数据传输格式
- 序列化
- JSON、XML 解析方式
- Andorid 网络基础
- HttpClient & HttpURLConnection][HttpClient _ HttpURLConnection
TCP
什么是TCP协议?UDP协议?它们的区别?
TCP/UDP协议为传输层协议,传输层用于向用户提供可靠的端到端(每个进程都用一个端口号唯一标识)的通信,通过提供流量控制和差错控制保证报文的正确传输。
传输单位是报文段或用户数据报。
主要协议包括TCP协议和UDP协议。
| 协议 | TCP协议 | UDP协议 |
|---|---|---|
| 简介 | 面向连接的、可靠的传输层协议。传输的数据无差错、不丢失、不重复、按序到达(有流量控制、拥塞控制、提供全双工通信) | 无连接的、不可靠的传输层协议。尽最大努力交付,不保证可靠性 |
| 连接 | 面向连接(发送数据前三次握手建立连接,发送结束四次挥手释放连接) | 无连接的 |
| 传输数据 | 面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块) | 面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部) |
| 交互 | 点对点(一对一) | 一对一,一对多,多对多 |
| 大小 | TCP首部(开销20字节,包括源端口号、目的端口号等以及确认ACK、同步SYN、终止FIN等用于连接建立与数据传输)+TCP数据部分 | UDP首部开销8字节(包括源端口号、目的端口号等)+UDP数据部分 |
| 适用情景 | TCP用于在传输层有必要实现可靠传输的情景 | UDP主要用于那些对高速传输和实时性有较高要求的通信或广播通信:1.包总量较少的通信(DNS、SNMP等)2.视频、音频等多媒体通信(即时通信)3.限定于LAN等特定网络中的应用通信4.广播通信(广播、多播) |
| 传输 | 可靠传输: (1)传输信道无差错,保证传输数据正确; (2)不管发送方以多快的速度发送数据,接收方总是来得及处理收到的数据; 可靠性原理: (1)使用三次握手建立TCP连接,四次握手释放TCP连接,保证建立的传输信道是可靠的。 (2)使用连续ARQ协议(超时自动重传:如果一个已经发送的报文段在超时时间内没没有收到确认,那么就重传这个报文段)来保证数据传输的正确性, (3)使用滑动窗口协议来保证接收方能够及时处理所接收到的数据,进行流量控制 (4)使用慢开始、拥塞避免、快重传和快恢复来进行拥塞控制,避免网络拥塞 |
不可靠传输: UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务 并且它是将应用程序发来的数据在收到的那一刻,立即按照原样发送到网络上的一种机制。 即使是出现网络拥堵的情况,UDP也无法进行流量控制等避免网络拥塞行为。 此外传输途中出现丢包,UDP也不负责重发(发送后不管其是否会到达接收方)。甚至当包的到达顺序出现乱序也没有纠正的功能。 如果需要以上的细节控制,不得不交由采用UDP的应用程序去处理。 |
| 协议 | FTP、HTTP、POP3、TELNET… | SMTP(网络管理)、DNS(域名转换)、TFTP(文件传输)、NFS(远程文件服务器)、DHCP… |
说一下TCP/IP三次握手,四次挥手的具体细节?
- 报文段标识符
- 确认ACK :TCP协议规定只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1。
- 同步SYN:在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1,因此SYN置1就表示这是一个连接请求或连接接受报文。
- 终止FIN:用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
- 序号seq:用于对字节流进行编号。例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
- 确认号ack:期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
- 三次握手
最初两端的TCP进程都处于CLOSED关闭状态,Client(A)主动打开连接,而Server(B)处于LISTEN(监听状态),等待A的连接请求并被动打开连接(由客户端执行connect触发)。
- 第一次握手:由Client发出请求连接数据包: SYN=1 ACK=0 seq=x(TCP规定SYN=1时不能携带数据,但要消耗一个序号,因此声明自己的序号是 seq=x)此时Client进入SYN-SENT(同步已发送)状态,等待Server确认;
- 第二次握手:Server收到请求报文后,如果统一建立连接,则向A发送连接确认报文,即 SYN=1 ACK=1 seq=y,ack=x+1,此时Server进入SYN-RCVD(同步收到)状态;
- 第三次握手:Client收到Server的确认(SYN+ACK)后,向Server发出确认报文段,即 ACK=1,seq=x+1, ack=y+1,TCP连接已经建立,Client进入ESTABLISHED(已建立连接)状态;
Server收到Client的确认后,也进入ESTABLISHED状态,完成三次握手;此时Client和Server可以开始传输数据。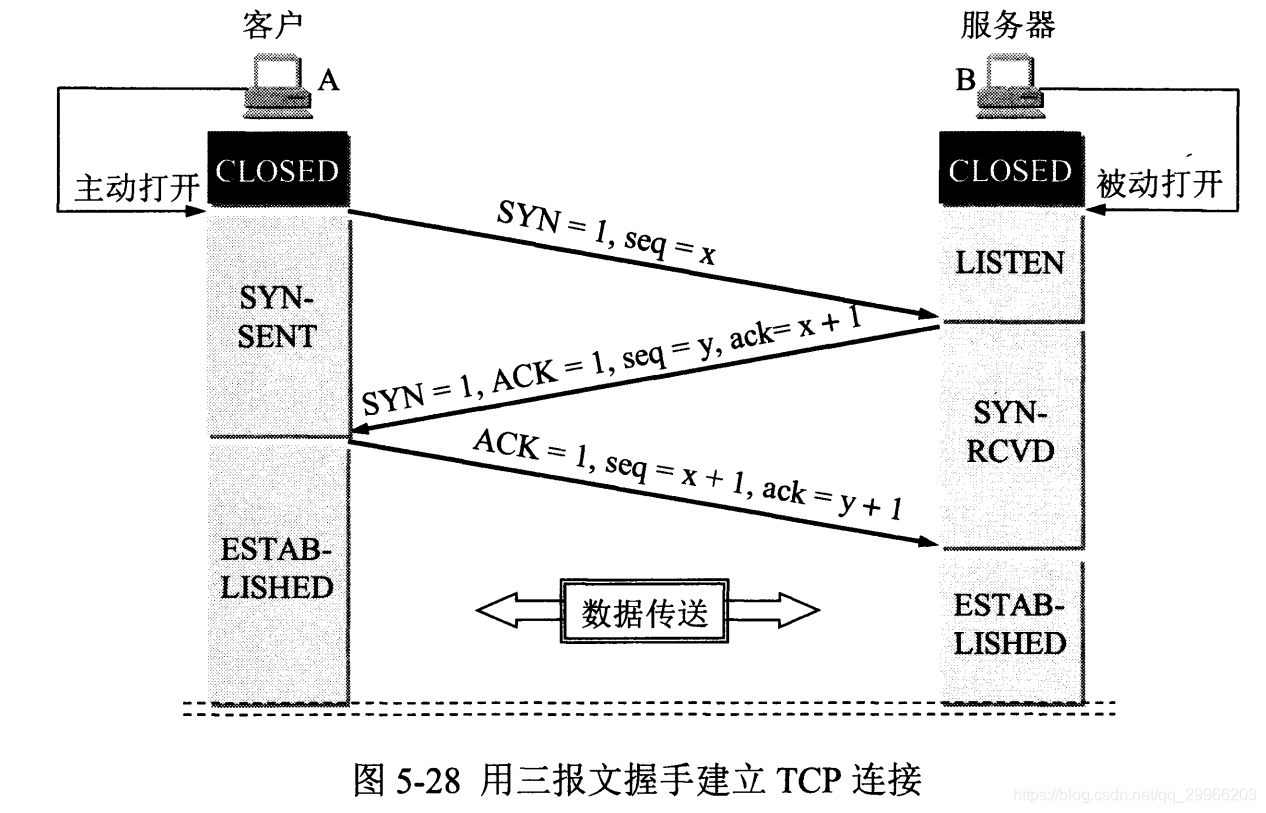
(理解版)
我们假设A和B是通信的双方。我理解的握手实际上就是通信,发一次信息就是进行一次握手。则对于三次握手:
第一次握手: A给B打电话说,你可以听到我说话吗?
第二次握手: B收到了A的信息,然后对A说: 我可以听得到你说话啊,你能听得到我说话吗?
第三次握手: A收到了B的信息,然后说可以的,我要给你发信息啦!
在三次握手之后,A和B都能确定这么一件事: 我说的话,你能听到; 你说的话,我也能听到。 这样,就可以开始正常通信了。
如果两次,那么B无法确定B的信息A是否能收到,所以如果B先说话,可能后面的A都收不到,会出现问题 。
如果四次,那么就造成了浪费,因为在三次结束之后,就已经可以保证A可以给B发信息,A可以收到B的信息; B可以给A发信息,B可以收到A的信息。
- 四次挥手
数据传输结束后,通信的双方都可释放连接,A和B都处于ESTABLISHED状态。当Client没有数据再需要发送给服务端时,就需要释放客户端的连接,整个过程为:
- 第一次挥手:当Client发起终止连接请求的时候,会发送一个(FIN为1,seq=u)的没有数据的报文,这时Client停止发送数据(但仍可以接受数据) ,进入FIN_WAIT1(终止等待1)状态,等待Server确认
- 第二次挥手:Server收到连接释放报文后会给Client一个确认报文段(ACK=1,ack=u+1,seq=v), 进入CLOSE-WAIT(关闭等待)状态
Client收到Server的确认后进入FIN_WAIT2状态,等待Server请求释放连接,Server仍可向Client发送数据。 - 第三次挥手:Server数据发送完成后,向Client发起请求连接释放报文(FIN=1,ACK=1,seq=w,ack = u+1),Server进入LAST-ACK(最后确认)状态,等待Client确认
- 第四次挥手:Client收到连接释放报文段后,回复一个确认报文段(ACK=1,seq=u+1,ack=w+1),进入 TIME_WAIT(时间等待) 状态,Server收到后进入CLOSED(连接关闭)状态。经过等待2MSL 时间(最大报文生存时间),Client进入CLOSED状态。
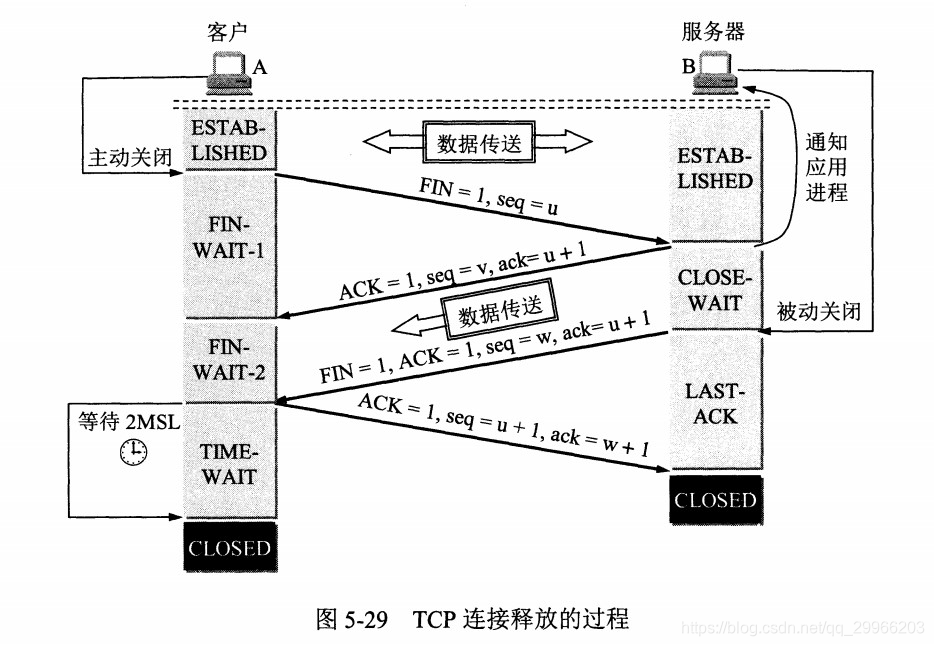
(理解版)
A:“喂,我不说了 (FIN)。”A->FIN_WAIT1
B:“我知道了(ACK)。等下,上一句还没说完。Balabala……(传输数据)”B->CLOSE_WAIT | A->FIN_WAIT2
B:”好了,说完了,我也不说了(FIN)。”B->LAST_ACK
A:”我知道了(ACK)。”A->TIME_WAIT | B->CLOSED
A等待2MSL,保证B收到了消息,否则重说一次”我知道了”,A->CLOSED
这样,通过四次挥手,可以把该说的话都说完,并且A和B都知道自己没话说了,对方也没花说了,然后就挂掉电话(断开链接)了 。
- 面试问题
- 为什么需要握手?
这里就引出了 TCP 与 UDP 的一个基本区别, TCP 是可靠通信协议, 而 UDP 是不可靠通信协议。
TCP 的可靠性含义: 接收方收到的数据是完整, 有序, 无差错的。
UDP 不可靠性含义: 接收方接收到的数据可能存在部分丢失, 顺序也不一定能保证。
UDP 和 TCP 协议都是基于同样的互联网基础设施, 且都基于 IP 协议实现, 互联网基础设施中对于数据包的发送过程是会发生丢包现象的, 为什么 TCP 就可以实现可靠传输, 而 UDP 不行? - 为什么需要三次握手?
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤。
如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。 - 为什么需要四次挥手?
为了让服务器发送还未传送完毕的数据。只有传送完毕后,服务器会发送FIN连接释放报文。
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET(服务端数据未传输完毕),FIN报文仅仅表示Client没有需要发送的数据,但是仍能接受数据,Server的数据未必全部发送出去,需要等待Server的数据发送完毕后发送FIN报文给Client才能表示同意关闭连接。
所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
建立连接时候ACK和SYN可以放在一个报文里发送给客户端。
连接关闭时ACK和FIN一般分开发送。
- 为什么A在TIME-WAIT状态必须等待2MSL的时间?
MSL最长报文段寿命Maximum Segment Lifetime,MSL=2
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由: - 保证A发送的最后一个ACK报文段能够到达B。
如果 B 没收到 A 发送来的确认报文(A发送的最后一个ACK报文段可能丢失),那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。 - 防止“防止本次已失效的连接请求报文段出现在新的连接中。
等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
- 整体通信流程
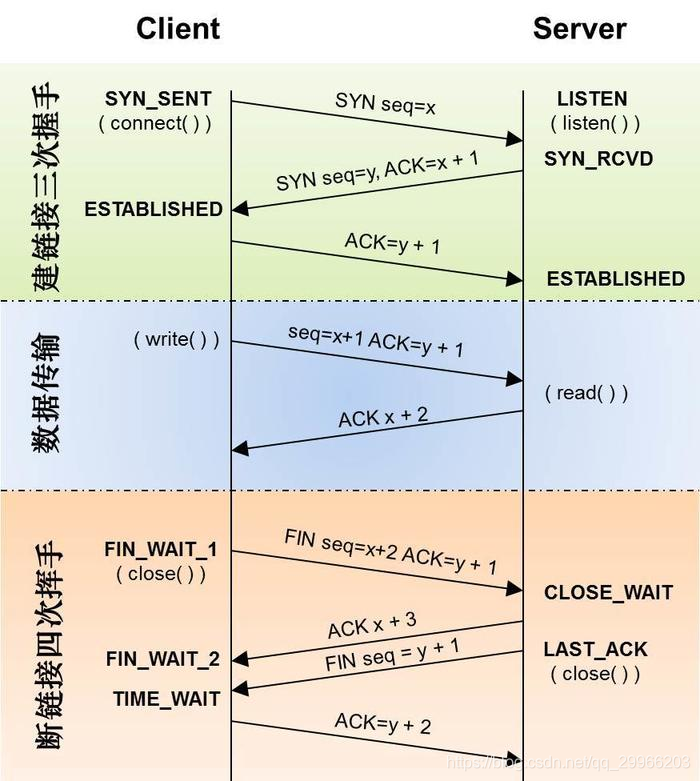
HTTP
描述一下HTTP协议?
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从万维网(WWW)Web服务器 传输超文本到 本地客户浏览器 的传输协议。
在Internet上的Web服务器上存放的都是超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息。
HTTP协议特点:
- 基于TCP/IP通信协议传递数据(HTML、图片文件,查询结果等)
- 属于应用层协议
- 采用客户端-服务端(请求-响应 C/S)工作方式,具体工作流程如下:
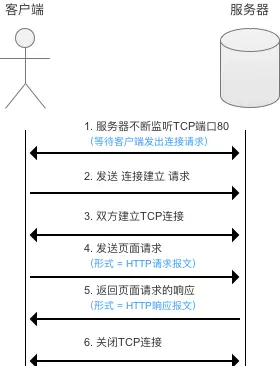
HTTP请求/响应报文?
HTTP在应用层通过报文交互数据,分为请求报文和响应报文,分别用于发送请求&响应请求。
- 请求报文
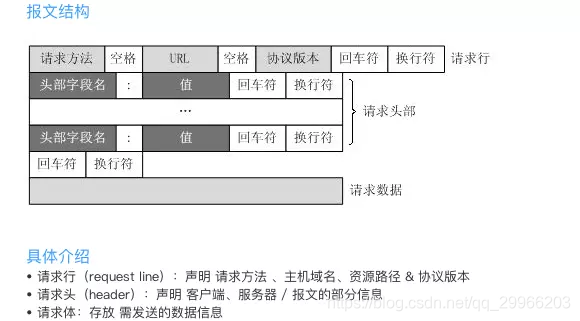
如
- 响应报文
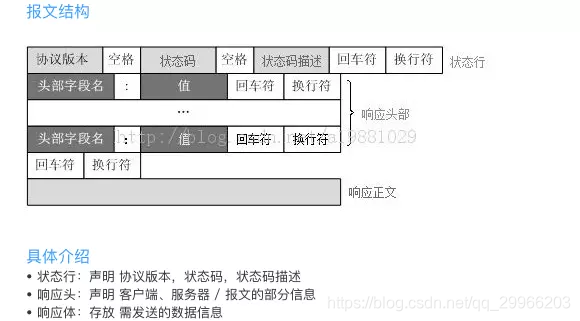
如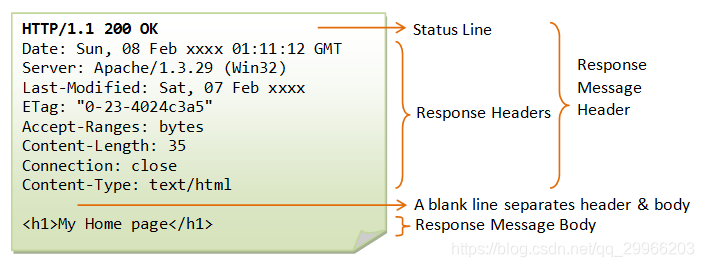
HTTP方法?(请求报文)
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
| 请求方法 | 用法 | 说明 |
|---|---|---|
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方法 | 返回:Allow: GET,POST,HEAD等 |
| HEAD | 获取报文首部 | 与GET方法类似,但不返回报文实体主体部分。用于确认URL的有效性以及资源更新日期时间等 |
| GET | 获取资源 | 当前网络请求中,绝大部分使用GET方法 |
| POST | 传输实体主体 | 向指定资源传输数据(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改 |
| PUT | 上传文件 | 由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法 PUT /new.html HTTP/1.1 |
| DELETE | 删除文件 | 与 PUT 功能相反,并且同样不带验证机制 DELETE /file.html HTTP/1.1 |
| TRACE | 追踪路径 | 回显服务器收到的请求,主要用于测试或诊断。 |
面试:POST与GET区别?
| GET提交 | POST提交 | |
|---|---|---|
| 作用 | 获取资源 | 传输实体数据 |
| 参数位置 | 附在URL之后(将数据放在HTTP请求行),以?代表URL结尾,多个参数用&连接。例如:login.action?name=chy&password=123 | 提交的数据放在HTTP报文的请求体中 |
| 参数长度 | 提交的数据大小有限制(因为浏览器对URL的长度有限制) | 提交的数据没有限制(GET提交的数据会在地址栏中显示,而POST提交,地址不会改变) |
| 参数形式 | 键值对形式(作为查询字符串) | 表单形式,因此必须将Content-type设置为:application/x-www-form- urlencoded |
| 参数类型 | 只允许ASCII字符 | 任何类型 |
| 安全性 | 安全性低 请求参数直接在URL上可见 报文可缓存在浏览器内 |
安全性高 请求参数在HTTP请求数据中 浏览器无缓存 |
| 应用场景 | 传递小量、不敏感的数据。用于从指定资源请求数据 | 传递大量、敏感数据。用于向指定资源提交数据 |
| 实例 | GET /bookes/?name=chy&password=123 HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 Gecko/20050225 Connection: Keep-Alive |
POST / HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 Gecko/20050225 Content-type: application/x-www-form- urlencoded Connection: Keep-Alive name=chy&password=123 |
HTTP状态码?(响应报文)
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
| 状态码 | 类别 | 含义 | 常见类型 |
|---|---|---|---|
| 1xx | Informational(信息性状态码) | 接收的请求正在处理 | |
| 2xx | Success(成功状态码) | 请求正常处理完毕 | 200:OK |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作以完成请求 | 304 Not Modified :如果请求报文首部包含例如:If-None-Match,If-Modified-Since等HTTP缓存相关数据 当服务器数据未修改时,则返回304告知客户可以使用缓存数据 |
| 4xx | Client Error(客户端错误状态码) | 服务器无法处理请求 | 400 Bad Request:请求报文出现语法错误 403 Forbidden:请求被拒绝 404 Not Found:没有找到服务器 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 | 500 Internal Server Error:服务器正在执行请求时内部发生错误 |
HTTP首部?(请求 & 响应首部常用字段)
有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。
- 请求 & 响应报文 的 通用首部字段
| 首部字段名 | 用法 | 说明 |
|---|---|---|
| Cache-Control | 指定请求和响应遵循的缓存机制 | 取值一般为no-cache或max-age=XX(XX为整数,表示资源缓存有效期(秒)) |
| Content-Type | 请求体/响应体类型 | text/plain:数据以纯文本形式(text/json/xml/html)进行编码,其中不含任何控件或格式字符 application/json(x-www-form-urlencoded):数据被编码为名称/值对。是标准的编码格式,如消息主体是序列化后的JSON字符串 multipart/form-data:数据被编码为一条消息,页上的每个控件对应消息中的一个部分,如文件上传 |
| Content-Length | 请求体/响应体长度 | 单位字节 |
| Content-Encoding | 请求体/响应体编码格式 | 如gzip,deflate |
| Accept | 说明接收的类型。可以多个值,用,分开 | Accept:text/plain,text/html |
| Accept-Encoding | 告诉对方我方接受的Content-Encoding | 如gzip,deflate |
| ETag | 当前资源的标识 | 与Last-Modified、If-None-Match、If-Modified-Since配合,用于缓存控制 |
- 请求报文 的 请求首部字段
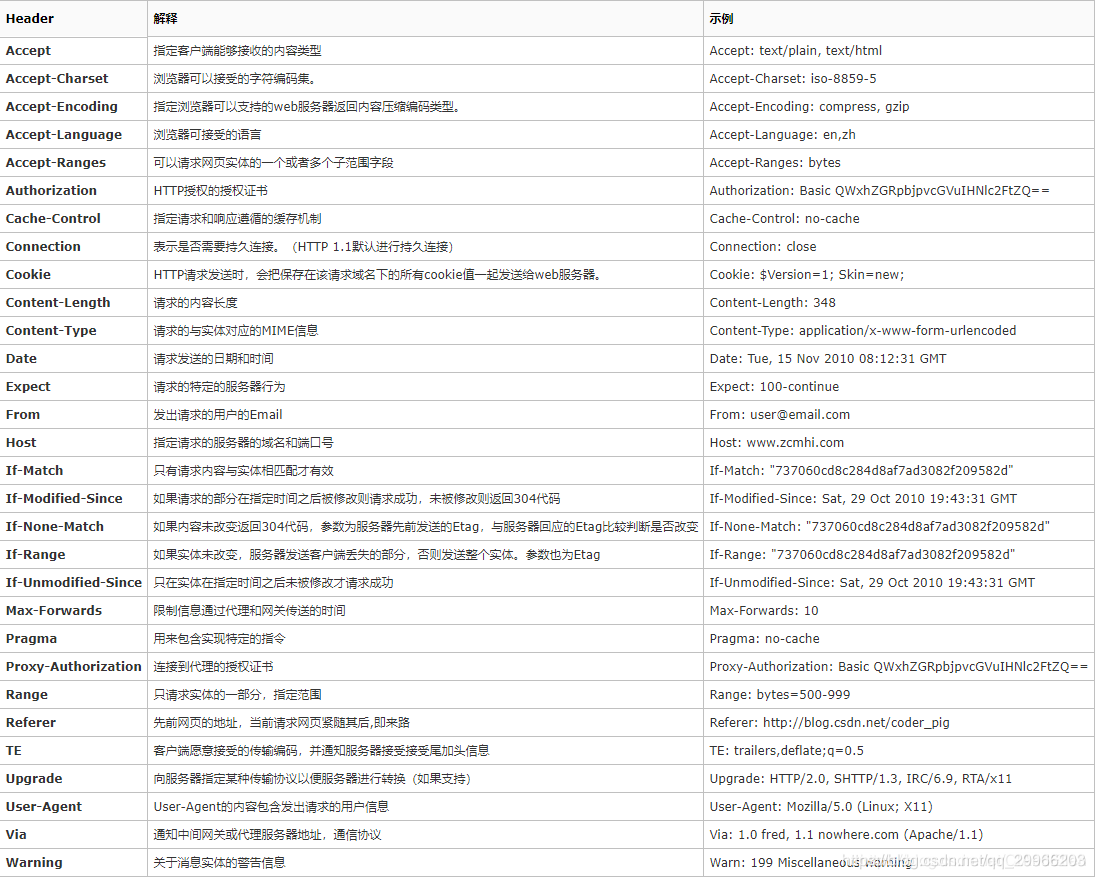
- 响应报文 的 响应首部字段
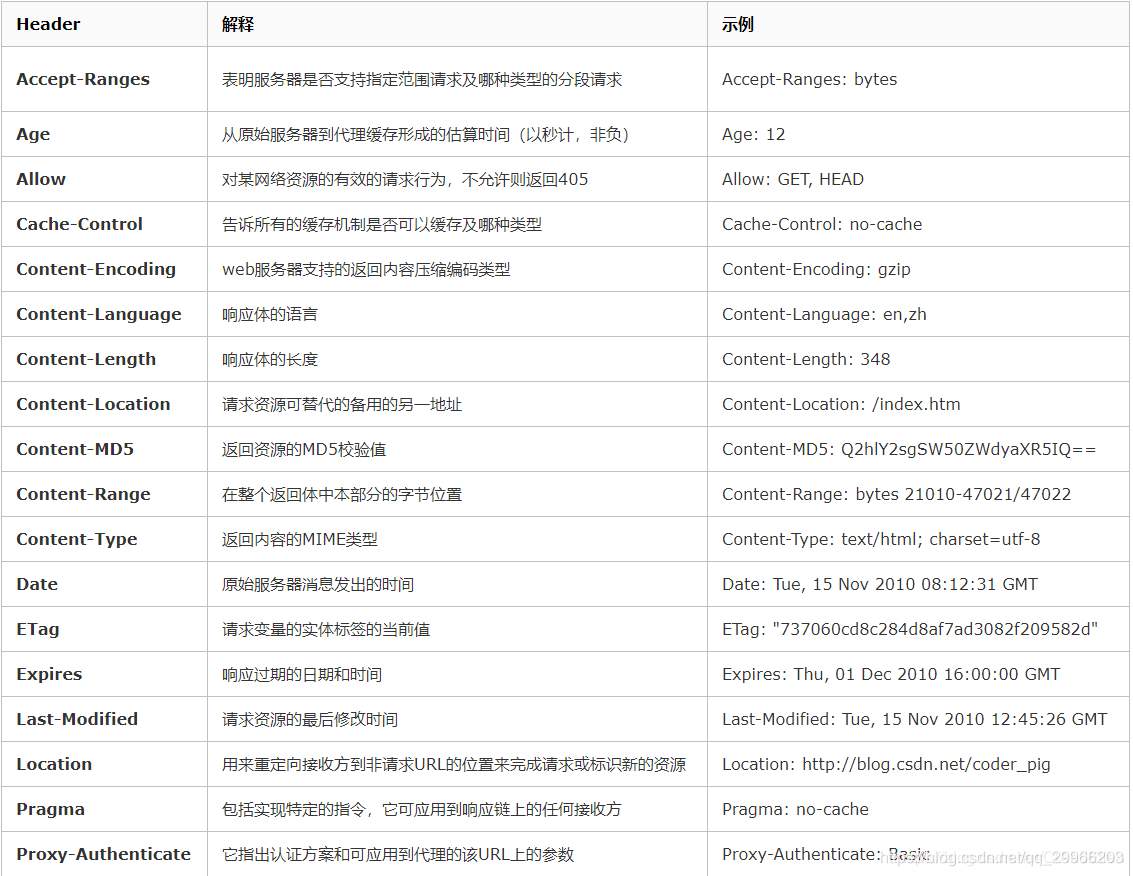
- 实体首部字段
| 首部字段名 | 用法 |
|---|---|
| Allow | 资源可支持的HTTP方法 |
| Content-Encoding | 实体主体使用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
HTTP 缓存机制?
- 浏览器第一次请求
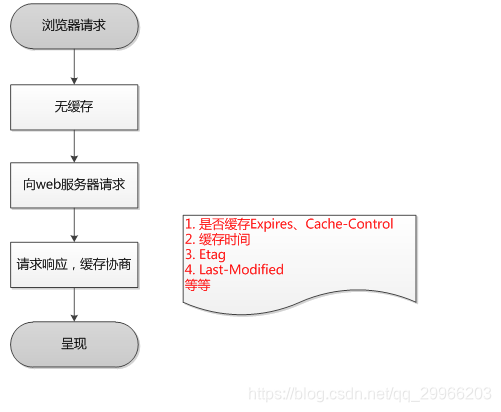
在浏览器第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回相应的数据(主体body)和缓存规则(响应头Header)后,浏览器将数据和缓存规则存储至缓存数据库中。
HTTP缓存规则包括:Expires、Cache-Control(强制缓存规则),Etag、Last-Modified(对比缓存规则)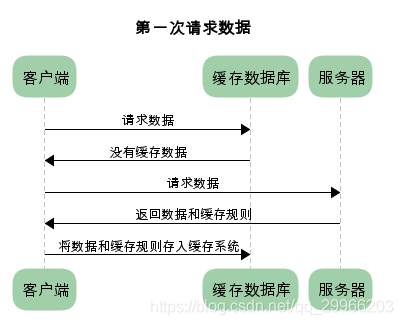
- 浏览器第二次请求
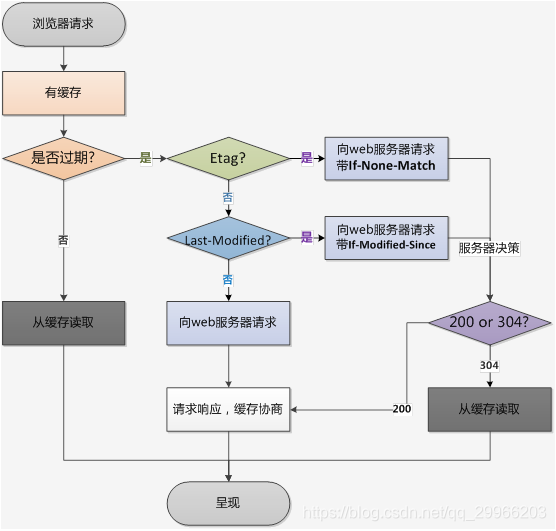
浏览器第二次请求数据时,会根据是否需要向服务器发起请求分为 强制缓存 & 对比缓存
- 首先执行强制缓存,服务器响应浏览器一个缓存时间(Expires/Cache-Control)
- Expires:服务器返回的到期时间。
- Cache-Control:
| Cache-Control类型 | 描述 |
|---|---|
| private | 客户端可缓存 |
| public | 客户端和代理服务器均可缓存 |
| max-age = xxx | 缓存内容在xxx秒后失效 |
| no-cache | 需要使用对比缓存来验证缓存数据 |
| no-store | 所有内容均不会缓存,不出发强制缓存与对比缓存 |
- 如果强制缓存命中(在缓存时间内),则直接使用缓存,不需与服务器发生交互,不再执行对比缓存规则。
- 若超出缓存时间,则执行比较缓存策略。
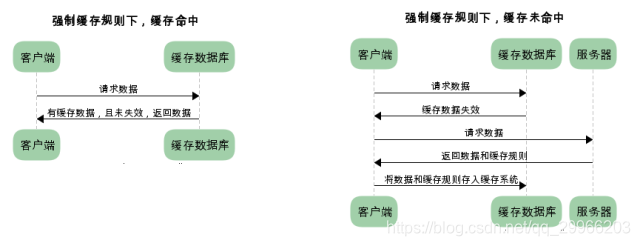
- 再执行比较缓存策略,浏览器将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验
- Last-Modified/If-Modified-Since:
Last-Modified 为服务器相应请求时,告诉浏览器资源的最后修改时间。当浏览器再次请求服务器时,将在请求中添加参数 If-Modified-Since(值为上次响应里面的Last-Modified值),服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间 大于 If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;若资源的最后修改时间 小于或等于 If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。 - Etag/If-None-Match:
Etag 为服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对。
若不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
为什么比较校验要访问服务器?
服务端在进行标识比较后,只返回header部分,通过状态码通知客户端使用缓存,不再需要将报文主体部分返回给客户端。因此报文大小和请求时间打打减少
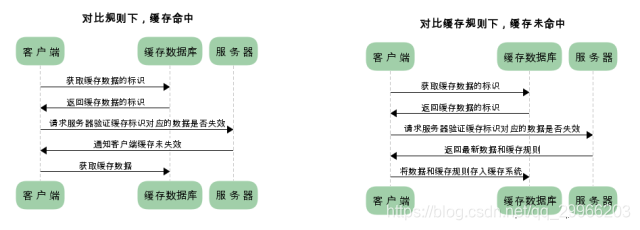
浏览器缓存机制:cookie/session
cookie & session均是解决HTTP无状态协议的一种记录客户状态的机制。
cookie——客户端的通行证
Cookie 是服务器发送到用户浏览器并保存在本地浏览器的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
创建过程:
- 服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
- 客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
session——服务端的客户档案
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID; - 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
cookie 与 session 区别
| cookie | session | |
|---|---|---|
| 存放位置 | 客户端 | 服务端 |
| 存储数据 | 只能存储 ASCII 码字符串 | 可以存储任何类型数据(考虑存储数据的复杂性) |
| 安全性 | 低(存储在浏览器中,对用户可见,容易被恶意查看、修改) | 高(session存储在服务器上,不存在敏感信息泄露的风险) |
| 开销 | 较小 | 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。 |
HTTP1.0 & HTTP1.x & HTTP2.0区别是什么?
| 协议 | HTTP1.0 | HTTP1.X | HTTP2.0 |
|---|---|---|---|
| 特点 | 无状态、无连接 HTTP1.0规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。 |
1. 持久连接:通过请求管道化实现,多个http 请求可以复用一个TCP连接,服务器端按照FIFO原则来处理不同的Request(实现"并行"传输) 2. 缓存处理:cache-control 3. 一个服务器能够创建多个Web站点:Host 4. 断点续传、身份认证、状态管理等 |
1. 二进制分帧:在应用层和传输层之间增加一个二进制分帧,在不改动 HTTP/1.x 的语义、方法、状态码、URI 以及首部字段的情况下, 解决了HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量 2. 实现多路复用:多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。即HTTP/2 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流,实现真正的并行传输 3. 头部压缩 4. 服务器推送:是一种在客户端请求之前发送数据的机制。 |
| 痛点 | 连接无法复用:每次请求都要经历三次握手和慢启动 队头阻塞:由于HTTP1.0规定下一个请求必须在前一个请求响应到达之前才能发送。假设前一个请求响应一直不到达,那么下一个请求就不发送,同样的后面的请求也给阻塞了 |
请求管道化并没有真正地实现"并行",且在 HTTP/1.1 协议中浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制。超过限制数目的请求会被阻塞 |
图1为短连接(http 1.0),图2为持久连接(多路复用 http 2.0),图3为持久连接(管道化http 1.1)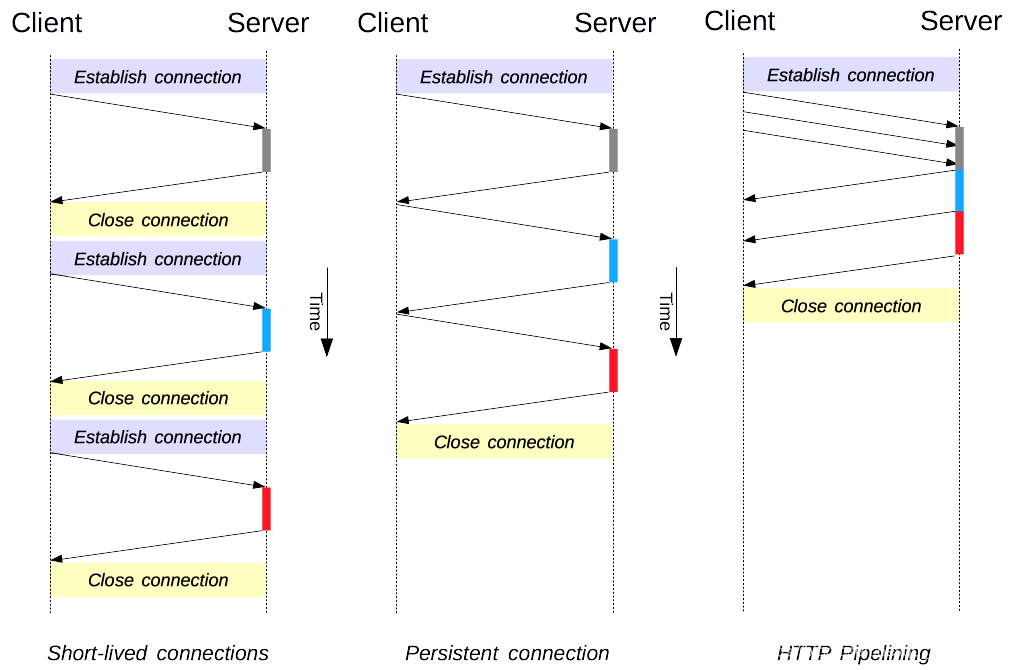
HTTPS
描述一下HTTPS?
- HTTP传输数据的安全性问题
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
- HTTPS简介
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)不是新协议,是以安全为目标的HTTP通道,可理解为HTTP的加强版。实现原理是让 HTTP 先和 SSL(Secure Sockets Layer 安全套接字层,TLS(传输层安全)是更为安全的升级版 SSL)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了SSL/TLS建立信道,加密数据包。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。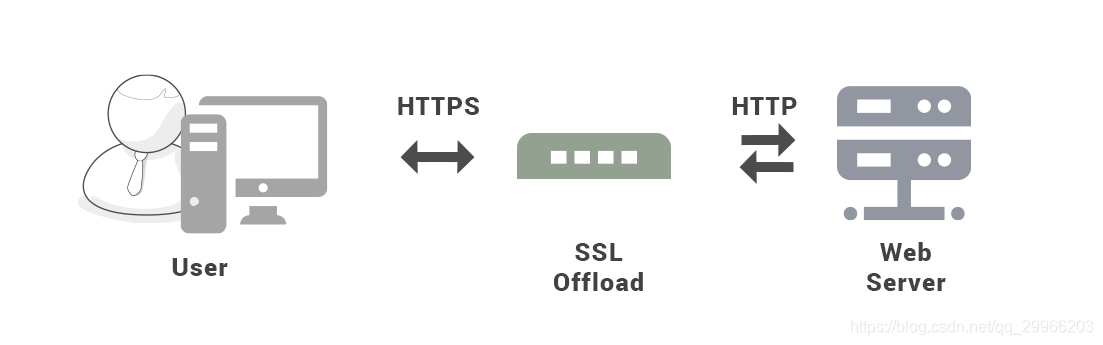
HTTPS特点: - 内容加密:采用混合加密技术,中间者无法直接查看明文内容。
混合加密:结合对称加密和非对称加密技术。使用非对称密钥加密用于传输对称密钥来保证传输过程的安全性,之后使用对称密钥加密进行通信来保证通信过程的效率。所以网络上传输的数据是被对称加密过的密文和用非对称加密后的密钥。即使被黑客截取。由于没有私钥,所以无法获取加密明文的密钥,也无法获取明文数据。 - 身份认证:确保浏览器访问的网站是经过CA(数字证书认证机构)验证的可信任网站。
- 数据完整性:SSL 提供报文摘要功能来进行完整性保护。
报文摘要:用于对发送的报文生成一个非常小的摘要信息。这个摘要信息保证原报文的完整性,即原报文只要有一位被改变,则摘要信息就会不匹配。
HTTPS 工作原理 / 连接 & 通信过程?
- 对称加密
使用一个密钥加密,使用相同的密钥才能解密。计算量小,加密解密速度快,但在传输加密数据时需传输密钥,密钥容易泄露,安全性低。 - 非对称加密
有一个公钥,一个私钥。公钥加密只能私钥解密,私钥加密只能公钥解密。计算量大,加密解密速度慢,在传输数据时只需传输公钥和公钥加密的数据,即时被截取,由于没有私钥所以无法获取明文数据,安全性高。 - HTTPS工作原理(SSL/TLS认证+加密过程)
发送方将对称加密的密钥通过非对称加密的公钥进行加密,接收方使用私钥进行解密得到对称加密的密钥,再通过对称加密交换数据。Https协议通过对称加密(传输快,传输交换数据)和非对称加密(安全,传输密钥)结合处理实现的。
- 浏览器发起往服务器的443端口发起请求”https://www.baidu.com"(及之后的对称加密算法)。
- 服务器中有公钥和私钥,收到请求,会将公钥和服务器身份认证信息通过SSL数字证书返回给浏览器(证书包含公钥和身份认证信息);
服务端,都有公钥、私钥和证书:
证书用来对通信方进行身份认证的。一般证书包含公钥以及身份认证信息。这里的证书可以是向某个权威机构申请的,也可以是自制的。区别在于自己办法的证书需要客户端验证通过,才可以继续访问;而使用受信任的公司申请的证书则不会弹出提示页面。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
- 浏览器进入数字证书认证环节,这一部分是浏览器内置的TLS完成的:
(1)证书可信度认证:首先浏览器会从内置的证书列表中索引,找到服务器下发证书对应的机构,如果没有找到,此时就会警告用户该证书不是由权威机构颁发,是不可信任的(浏览器显示https警告)。如果查到了对应的机构,则取出该机构颁发的证书公钥。
(2)服务端身份认证:用机构的证书公钥解密得到证书的内容和证书签名,内容包括网站的网址、网站的公钥、证书的有效期等。浏览器会先验证证书签名的合法性。签名通过后,浏览器验证证书记录的网址是否和当前网址是一致的,不一致会警告用户。如果网址一致会检查证书有效期,证书过期了也会警告用户。这些都通过认证时,浏览器就可以安全使用证书中的网站公钥了。
(3)浏览器生成一个随机数R,并使用证书公钥对R进行加密。(R就是之后数据传输的对称密钥) - 浏览器将加密的R传送给服务器。
- 服务器用自己的私钥解密得到R。
- 服务器以R为密钥使用了对称加密算法加密网页内容并传输给浏览器。
- 浏览器以R为密钥使用对应的对称解密算法获取网页内容。
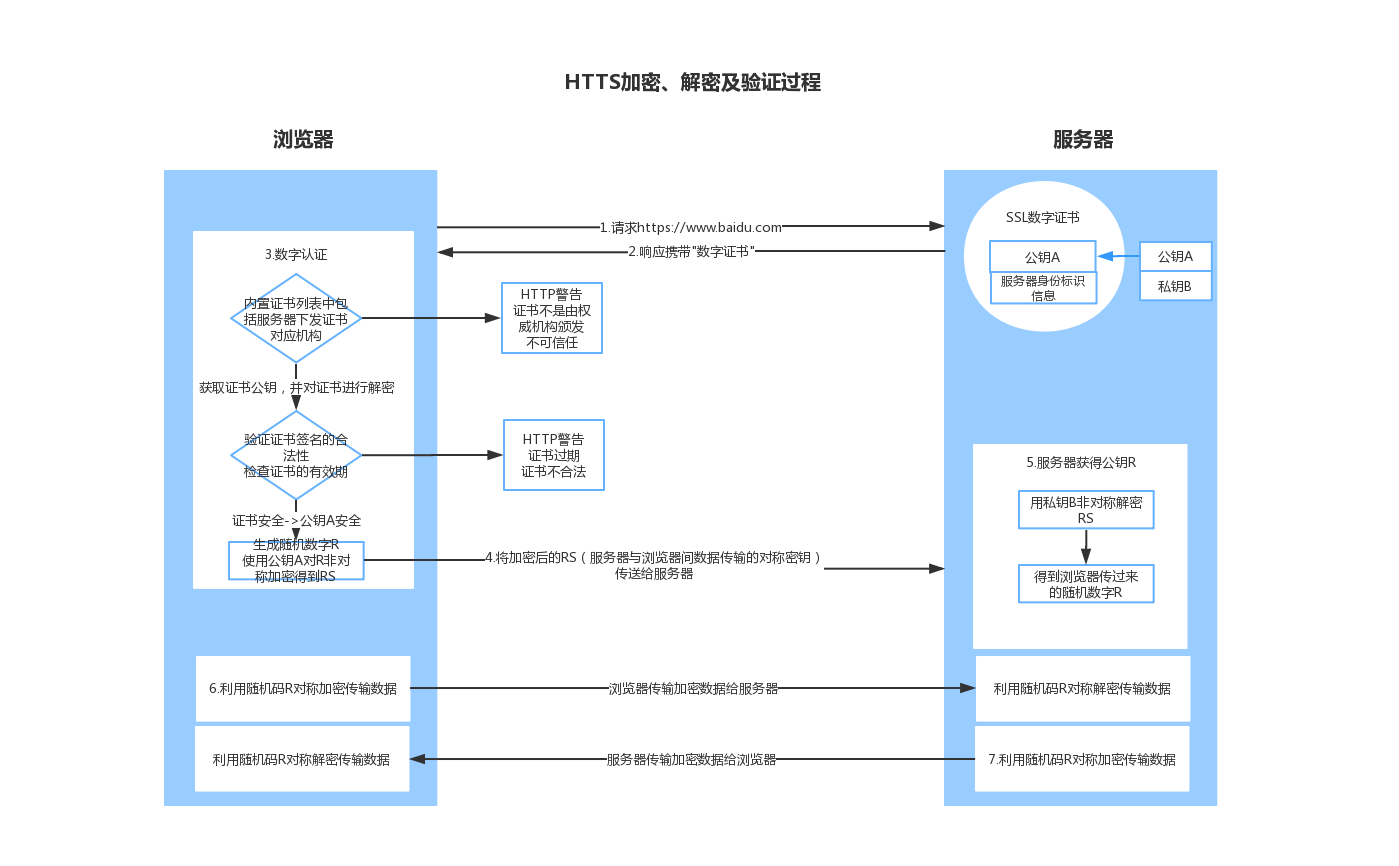
- HTTPS中那里使用对称加密?哪里使用非对称加密
前5步其实就是HTTPS的握手过程,这个过程主要是认证服务端证书的合法性。
因为非对称加密计算量较大,整个通信过程只会用到一次非对称加密算法(主要是用来保护传输客户端生成的用于对称加密的随机数私钥)。后续内容的加解密都是通过一开始约定好的对称加密算法进行的。
握手过程采用了一次非对称加密,对对称密钥加密。使得浏览器与服务器双方知道传输数据过程对称加密算法的规则。
数据传输过程采用多次对称加密,对传输数据加密。浏览器和服务器用握手过程获得的对称加密规则加密/解密传输数据。
HTTPS与HTTP区别?
| HTTP | HTTPS | |
|---|---|---|
| 定义 | 超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议 | HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性 |
| 成本 | 成本低 | 服务器的运营人员需要向CA申请证书,SSL的专业证书需要购买,功能越强大,费用越高 |
| 安全性 | 安全性较低 | HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比HTTP协议安全,防止数据在传输过程中被窃取,确保数据的完整性 |
| 端口 | 80 | 443 |
| 效率 | 效率较高 | 因为需要进行加密解密等过程,因此速度会更慢 |
对称加密 & 非对称加密?
| 加密算法 | 对称加密 | 非对称加密 |
|---|---|---|
| 原理 | 加密算法是公开的,靠的是密钥来加密数据。使用一个密钥加密,使用相同的密钥才能解密 | 加密算法是公开的,有一个公钥,一个私钥(公钥和私钥不是随机的,由加密算法生成);公钥加密只能私钥解密,私钥加密只能公钥解密,加密解密需要不同密钥 |
| 常用算法 | DES,3DES,AES | RSA |
| 优点 | 计算量小,加密和解密速度较快,适合加密较大数据 | 可以传输公钥(服务器—>客户端)和公钥加密的数据(客户端->服务器),数据传输安全 |
| 缺点 | 在传输加密数据之前需要传递密钥,密钥传输容易泄露;一个用户需要对应一个密钥,服务器管理密钥比较麻烦 | 计算量大,加密和解密速度慢 |
Socket
描述一下Socket?
Socket 即 套接字,是通信的基石,是应用层 与 TCP/IP 协议族通信的中间软件抽象层,本质为一个封装了 TCP / IP协议族 的编程接口(属于传输层)。网络上的两个进程端口通过Socket实现一个双向的通信连接从而进行数据交换。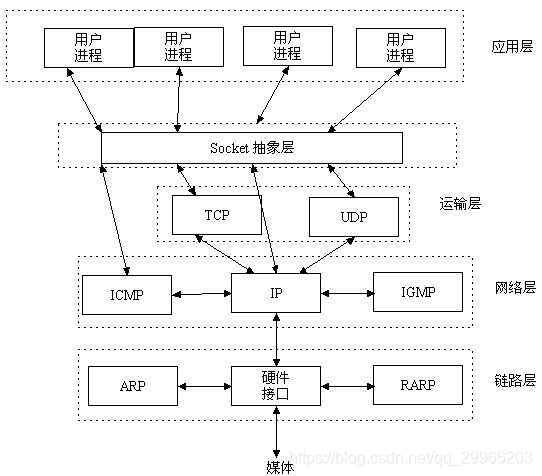
- 表示
Socket是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用协议、(本地主机IP地址,本地进程的协议端口)、(远地主机IP地址,远地进程协议端口)。
Socket一般成对出现,一对套接字(其中一个运行在服务端一个运行在客户端)
1 | Socket ={ |
- 适用场景:即时通讯,替代轮询
网站上的即时通讯是很常见的,比如网页的QQ,聊天系统等。按照以往的技术能力通常是采用轮询、Comet技术解决。
HTTP协议是非持久化的,单向的网络协议,在建立连接后只允许浏览器向服务器发出请求后,服务器才能返回相应的数据。当需要即时通讯时,通过轮询在特定的时间间隔(如1秒),由浏览器向服务器发送Request请求,然后将最新的数据返回给浏览器。这样的方法最明显的缺点就是需要不断的发送请求,而且通常HTTP request的Header是非常长的,为了传输一个很小的数据 需要付出巨大的代价,是很不合算的,占用了很多的宽带。
缺点:会导致过多不必要的请求,浪费流量和服务器资源,每一次请求、应答,都浪费了一定流量在相同的头部信息上
然而WebSocket的出现可以弥补这一缺点。在WebSocket中,只需要服务器和浏览器通过HTTP协议进行一个握手的动作,然后单独建立一条TCP的通信通道进行数据的传送。
Socket 通信模型 / 原理 / 连接过程?
ServerSocket:服务器端类
Socket:客户端类
服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。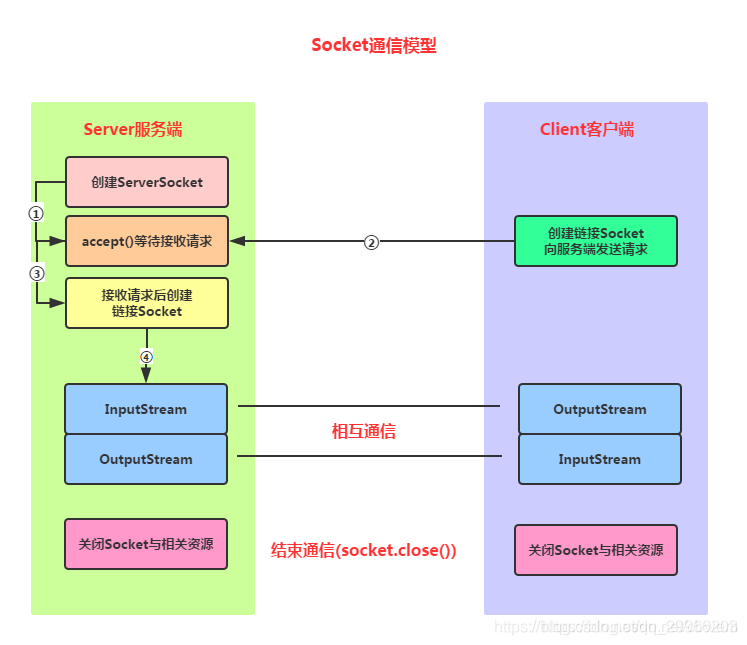
(1)连接过程
- 服务端监听
服务端创建 ServerSocket 实例,绑定监听的端口;调用accept()方法,进入等待状态,等待客户请求
1 | ServerSocket ss =new ServerSocket(30000); |
- 客户端请求
客户端创建 Socket 实例,指明需要连接的服务端IP地址和端口号(即指明需要连接服务端套接字),并向服务端Socket提出连接请求
1 | Socket s = new Socket("192.168.1.88",30000); |
- 连接确认
当 服务端Socket 监听到 客户端Socket 的连接请求后,为该连接创建一个服务端Socket。此时连接就建立好了。
(2)通信过程
- 连接建立后,服务端/客户端通过入流InputStream读取接收到的数据;通过OutputStream向对方发送信息。
- 调用close()方法关闭相应资源
Socket 使用?
(1)使用 ServerSocket 创建服务端
1 | public class SocketServer { |
(2)使用 Socket 创建客户端
1 | public class MainActivity extends AppCompatActivity implements View.OnClickListener { |
描述一下WebSocket?
WebSocket是HTML5一种新的协议。它借鉴了Socket这种思想,为web应用程序客户端和服务端之间(注意是客户端服务端)提供了一种全双工通信机制(full-duplex)。同时,它又是一种新的应用层协议。一开始的握手需要借助HTTP请求完成。
WebSocket同HTTP一样也是应用层的协议,但是它是一种双向通信协议,是建立在TCP之上的。连接过程需要进行握手:
浏览器、服务器建立TCP连接,三次握手。这是通信的基础,传输控制层,若失败后续都不执行。
TCP连接成功后,需要进行浏览器与服务器的一次握手(开始前的HTTP握手):
- 浏览器通过HTTP协议向服务器传送WebSocket支持的版本号等信息。
- 服务器收到客户端的握手请求后,同样采用HTTP协议回馈数据。
当收到了连接成功的消息后,通过TCP通道进行传输通信。并且这个连接会持续存在直到客户端或者服务器端的某一方主动的关闭连接。
现在,很多网站为了实现推送技术,所用的技术都是 Ajax 轮询。轮询是在特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP请求,然后由服务器返回最新的数据给客户端的浏览器。这种传统的模式带来很明显的缺点,即浏览器需要不断的向服务器发出请求,然而HTTP请求可能包含较长的头部,其中真正有效的数据可能只是很小的一部分,显然这样会浪费很多的带宽等资源。
HTML5 定义的 WebSocket 协议,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。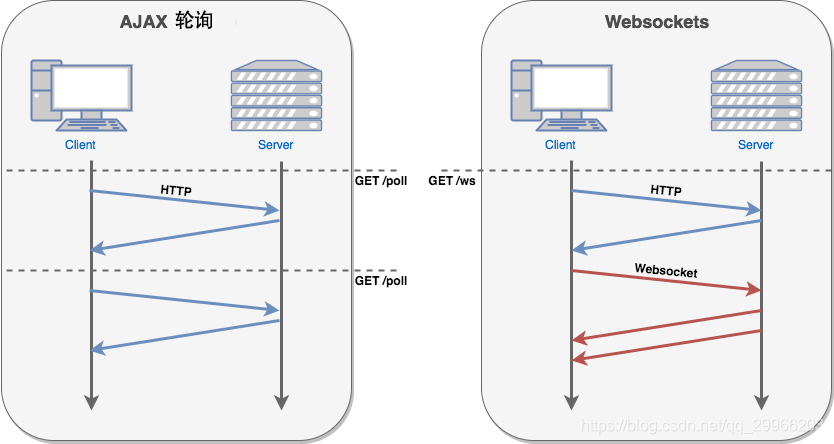
1 | function WebSocketTest() |
Socket & WebSocket & HTTP 对比?
| Socket | WebSocket | HTTP | |
| 定义 | 封装了 TCP / IP协议族 的编程接口(API) | 借鉴了Socket这种思想,为web服务器和浏览器之间提供了一种全双工通信机制的数据传输协议 | 利用TCP在Web服务器和浏览器之间数据传输的协议 |
| 工作层 | 传输层 | 应用层 | |
| 数据传输 | 全双工通信机制(双向) 即建立网络连接后,通信双方都能主动向对方发送或接受数据,直到双方连接断开。即服务器可主动发送消息给客户端,实现信息的主动推送;而不需要由客户端向服务器发送请求 |
请求-响应(单向) 客户端向服务端发送请求后,服务端才能向客户端返回数据 |
|
| 持久性 | 持久化 (Socket 的 TCP 长连接的通讯模式:一旦 Socket 连接建立后,后续数据都以帧序列的形式传输。在客户端或服务端断开Socket 连接前,不需要客户端和服务端重新发起连接请求。) |
非持久化 | |
| 连接建立 & 数据传输 | 1. 创建ServerSocket对象,绑定监听的端口 2. 调用accept()方法监听客户端的请求 3. 连接建立后,通过输入流InputStream、OutputStream进行数据交互 |
TCP连接建立后,借助HTTP协议进行WebSocket三次握手,之后数据传输使用WebSocket协议 | TCP连接建立后,客户端发送请求报文,服务端返回响应报文 |
数据传输格式
序列化
序列化:把java对象转化为二进制字节码写入IO流中。
反序列化:将IO流中的二进制字节恢复成java对象。
序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
应用场景:
- 所有可在网络上传输的对象都必须是可序列化的。
- 所有需要保存到磁盘的java对象都必须是可序列化的。
通常建议:程序创建的每个JavaBean类都实现Serializeable接口
JSON、XML 解析方式
- Json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。 - 代码格式
1 | { |
- 解析方式
| 解析方式 | JSONObject | FastJson | Gson |
|---|---|---|---|
| 介绍 | 原生 | 阿里巴巴FastJson是一个Json处理工具包 | GSON是Google提供的用来在Java对象和JSON数据之间进行映射的Java类库 |
| 序列化 | String jsonStr = jsonObject.toString(); String jsonStr = jsonArray.toString(); |
String jsonString = JSON.toJSONString(person); | String gsonString = gson.toJson(object); |
| 反序列化 | JSONObject jsonObject = new JSONObject(jsonStr); JSONArray jsonArray = new JSONArray(jsonStr); |
person =JSON.parseObject(jsonString,Person.class); List persons2 = JSON.parseArray(jsonString,Person.class); |
T t = gson.fromJson(gsonString, cls); |
| 特点 | 性能好,速度快 | 功能全面 |
- XML
- 代码格式
1 | <?xml version="1.0" encoding="utf-8"?> |
- 解析方式
- Dom
- Sax
- Pull
Andorid 网络基础
HttpClient & HttpURLConnection
Android主要提供了两种方式进行网络请求:HttpClient与HttpUrlConnection。
| HttpClient | HttpUrlConnection | |
| 相同 | 都支持https协议,以流的形式进行上传和下载、配置超时事件、IPV6、以及连接池等功能。 | |
| 不同 | 拥有众多API,实现较稳定,bug数量少。但难以扩展,维护成本高。Android6.0后被移除。 | 提供简单、轻量级API,易于扩展。但Android2.2前有个重大bug。2.3后修改了bug并且提供了压缩和缓存机制,有效提升了网络性能。 |
常见网络框架总结
- Volley
Volley是Google推出的网络通信框架,适合数据量小但通信频繁的网络操作。但不适合大文件下载。
特点是:(1)可进行Post、Get网络请求与图像异步处理请求(2)对网络请求进行排序与优先级处理(3)对网络请求进行缓存(4)多级别取消请求(5)与Activity生命周期联动
它的工作原理是先将请求加入缓存队列,并通过cacheDispatcher查询本地是否缓存本次请求结果,如果命中,则从缓存中解析结果并返回主线程;如果没有命中则将请求添加到网络队列,并通过networkDispatcher发送网络请求,获得并解析响应结果,将结果写入缓存并返回主线程。 - OkHttp
OkHttp是Square团队开发的支持Http2/SPDY的网络通信框架,即支持共享同一个Socket处理同一个服务器的所有请求,若SPDY不可用,则通过连接池来减少请求延时。支持重连机制、缓存响应数据及GZIP减少数据流量。
OkHttp核心设计模式是拦截器责任链模式,采用责任链的模式来使每个功能分开,每个拦截器自行完成自己的任务,并且将不属于自己的任务交给下一个,简化了各自的责任和逻辑,实现了网络请求。这样设计的好处在于使每个责任链可以分层实现缓存、压缩、网络IO和请求等功能,并且可以对响应的数据做其他的逻辑处理。
OkHttp适用于数据量大的重量级网络请求。 - Retrofit
Retrofit是基于RESTful风格推出的网络请求框架封装,是基于OKHttp的网络请求框架的二次封装。其底层是通过OKHttp进行网络请求,而Retrofit仅负责网络请求接口的封装,从而简化了用户网络请求的参数配置,还能与Rxjava结合。
Retrofit采用了大量设计模式封装OkHttp,它的核心工作原理是将Http请求抽象为Java接口,在接口中用注解描述和配置网络请求参数。Retrofit使用动态代理的方式,动态地将网络请求接口的注解解析成HTTP请求。最终通过OKHttp执行Http请求。
Retrofit在任何场景下都优先选择,尤其是后台Api遵循RESTful风格且项目中使用RxJava的场景。
第五章 网络 之 Android网络知识&框架
- (一)HttpClient和HttpURLConnection的区别
- (二)Volley,OkHttp,Retrofit(三大常用Android网络框架)之间的区别和核心原理和使用场景
- (三)网络请求缓存处理,okhttp如何处理网络缓存的?
(一)HttpClient和HttpURLConnection的区别
Android主要提供了两种方式进行网络请求:HttpClient与HttpUrlConnection。这两种方式都支持https协议,以流的形式进行上传和下载、配置超时事件、IPV6、以及连接池等功能。
HttpClient拥有众多API,实现较稳定,bug数量少。但难以扩展,维护成本高。Android6.0后被移除。
HttpUrlConnection提供简单、轻量级API,易于扩展。但Android2.2前有个重大bug。2.3后修改了bug并且提供了压缩和缓存机制,有效提升了网络性能。
(二)Volley,OkHttp,Retrofit(三大常用Android网络框架)之间的区别和核心原理和使用场景
1、Volley是Google推出的网络通信框架,适合数据量小但通信频繁的网络操作。但不适合大文件下载。
特点是:(1)可进行Post、Get网络请求与图像异步处理请求(2)对网络请求进行排序与优先级处理(3)对网络请求进行缓存(4)多级别取消请求(5)与Activity生命周期联动
它的工作原理是先将请求加入缓存队列,并通过cacheDispatcher查询本地是否缓存本次请求结果,如果命中,则从缓存中解析结果并返回主线程;如果没有命中则将请求添加到网络队列,并通过networkDispatcher发送网络请求,获得并解析响应结果,将结果写入缓存并返回主线程。
2、OkHttp是Square团队开发的支持Http2/SPDY的网络通信框架,即支持共享同一个Socket处理同一个服务器的所有请求,若SPDY不可用,则通过连接池来减少请求延时。支持重连机制、缓存响应数据及GZIP减少数据流量。
OkHttp核心设计模式是拦截器责任链模式,采用责任链的模式来使每个功能分开,每个拦截器自行完成自己的任务,并且将不属于自己的任务交给下一个,简化了各自的责任和逻辑,实现了网络请求。这样设计的好处在于使每个责任链可以分层实现缓存、压缩、网络IO和请求等功能,并且可以对响应的数据做其他的逻辑处理。
OkHttp适用于数据量大的重量级网络请求。
3、Retrofit是基于RESTful风格推出的网络请求框架封装,是基于OKHttp的网络请求框架的二次封装。其底层是通过OKHttp进行网络请求,而Retrofit仅负责网络请求接口的封装,从而简化了用户网络请求的参数配置,还能与Rxjava结合。
Retrofit采用了大量设计模式封装OkHttp,它的核心工作原理是将Http请求抽象为Java接口,在接口中用注解描述和配置网络请求参数。Retrofit使用动态代理的方式,动态地将网络请求接口的注解解析成HTTP请求。最终通过OKHttp执行Http请求。
Retrofit在任何场景下都优先选择,尤其是后台Api遵循RESTful风格且项目中使用RxJava的场景。
(三)网络请求缓存处理,okhttp如何处理网络缓存的?
Http网络请求缓存处理:
强制缓存:当用户端第一次请求数据是,服务端返回了缓存的过期时间(Expires与Cache-Control),没有过期即可以继续使用缓存;如果过期则不使用缓存,无需再请求服务端。
对比缓存:当用户端第一次请求数据时,服务端会将缓存标识(Etag/If-None-Match与Last-Modified/If-Modified-Since)与数据一起返回给用户端,用户端将两者都备份到缓存中 ,再次请求数据时,用户端将上次备份的缓存
标识发送给服务端,服务端根据缓存标识进行判断缓存是否过期,假如返回304,则表示缓存可用,从缓存中读取数据;假如返回200,标识缓存不可用,请求服务端,并使用最新返回的数据。
第六章 图片
- Bitmap
- Bitmap 简介
- Bitmap 导致OOM 原因 & 性能优化
- Bitmap 压缩策略
- 大图加载:从网络加载一个10M的图片,说下注意事项?
- 说一下三级缓存的原理?
- LruCache & DiskLruCache原理?
- 如果让你设计一个图片加载库,你会如何设计?
Bitmap
Bitmap 简介
- 基本信息
- 简介
Bitmap位图包括像素以及长、宽、颜色等描述信息。长宽和像素位数是用来描述图片的,可以通过这些信息计算出图片的像素占用内存的大小。
位图可以理解为一个画架,把图放到上面然后可以对图片做一些列的处理。
位图文件图像显示效果好,但是非压缩格式,需要占用较大的存储空间。 - Config 图片像素类型
| 图片像素类型 | 解释 | 适用场景 |
|---|---|---|
| ARGB_8888 | 四个通道都是8位,每个像素占用4个字节,图片质量是最高的,但是占用的内存也是最大的 | 既要设置透明度,对图片质量要求又高,就用ARGB_8888 |
| ARGB_4444 | 四个通道都是4位,每个像素占用2个字节,图片的失真比较严重 | ARGB_4444失真严重,基本不用 |
| RGB_565 | 没有A通道,每个像素占用2个字节,图片失真小,但是没有透明度 | 不需要设置透明度,RGB_565是个不错的选择 |
| ALPHA_8 | 只有A通道,每个像素占用1个字节大大小,只有透明度,没有颜色值 | ALPHA_8使用场景特殊,比如设置遮盖效果等 |
- CompressFormat 图片压缩格式
| 图片压缩格式 | 解释 | 文件格式 | 优点 | 缺点 |
|---|---|---|---|---|
| JPEG | 一种有损压缩(JPEG2000既可以有损也可以无损) | .jpg 或者 .jpeg | 采用了直接色,有丰富的色彩,适合存储照片和生动图像效果 | 有损,不适合用来存储logo、线框类图 |
| PNG | 一种无损压缩 | .png | 支持透明、无损,主要用于小图标,透明背景等 | 若色彩复杂,则图片生成后文件很大 |
- 加载
BitmapFactory提供了四类方法:decodeFile、decodeResource、decodeStream、decodeByteArray
- 从文件中读取
1 | try { |
- 从资源中读取
1 | Bitmap bitmap = BitmapFactory.decodeResource(getContext().getResources(), R.drawable.sample); // 间接调用 BitmapFactory.decodeStream |
- 从字节序列中读取
1 | // InputStream转换成byte[] |
- 巨图加载:BitmapRegionDecoder,可以按照区域进行加载
- 存储
根据android sdk版本有所不同。
- 2.3以前
图片像素存储在native内存中。缺点是虚拟机无法自动进行垃圾回收,必须手动使用recycle,很容易导致内存泄露。也不方便调试等; - 3.0以后
图片像素存储在Java堆中,垃圾回收能够自动进行,内存占用也能方便的展示在monitor中; - 4.0以后
传输方式发生变化,大数据会通过ashmem(匿名共享内存)来传递(不占用Java内存),小数据通过直接拷贝的方式(在内存中操作),放宽了图片大小的限制; - 6.0以后
加强了ashmen存储图片的方式
- 绘图:Paint & Canvas & Bitmap
Bitmap可以理解为画架或者画布,它是像素的集合,是色彩的表现和承载者;
Canvas可以理解为画家的各种操作,通过操作Paint在Bitmap上进行创作;
Paint可以理解为画笔,可以自定义各种色彩等。
[Android利用canvas画各种图形][Android_canvas]
Canvas.drawBitmap 贴图
1 | /* |
Matrix 实现基本变换
1 | // 定义矩阵 |
canvas绘制圆角矩形
1 | // 准备画笔 |
- 开源框架
- Picasso包体积小、清晰,但功能有局限不能加载gif、只能缓存全尺寸;
- Glide功能全面,擅长大型图片流,提交较大;
- Fresco内存优化,减少oom,体积更大
Bitmap 导致OOM 原因 & 性能优化
[性能优化——Bitmap优化 原因 & 方案][Bitmap_ _ _]
Bitmap 压缩策略
- 更换图片格式
Android目前常用的图片格式有png,jpeg和webp,
- png:无损压缩图片格式,支持Alpha通道,Android切图素材多采用此格式
- jpeg:有损压缩图片格式,不支持背景透明,适用于照片等色彩丰富的大图压缩,不适合logo
- webp:是一种同时提供了有损压缩和无损压缩的图片格式,派生自视频编码格式VP8,从谷歌官网来看,无损webp平均比png小26%,有损的webp平均比jpeg小25%~34%,无损webp支持Alpha通道,有损webp在一定的条件下同样支持,有损webp在Android4.0(API 14)之后支持,无损和透明在Android4.3(API18)之后支持
采用webp能够在保持图片清晰度的情况下,可以有效减小图片所占有的磁盘空间大小
- 质量压缩
质量压缩并不会改变图片在内存中的大小,仅仅会减小图片所占用的磁盘空间的大小,因为质量压缩不会改变图片的分辨率,而图片在内存中的大小是根据widthheight一个像素的所占用的字节数计算的,宽高没变,在内存中占用的大小自然不会变,质量压缩的原理是通过改变图片的位深和透明度来减小图片占用的磁盘空间大小,所以不适合作为缩略图,可以用于想保持图片质量的同时减小图片所占用的磁盘空间大小。另外,由于png是无损压缩,所以设置quality无效
1 | originBitmap.compress(format, quality, bos); |
- 采样率压缩
采样率压缩是通过设置BitmapFactory.Options.inSampleSize,来减小图片的分辨率,进而减小图片所占用的磁盘空间和内存大小。
设置的inSampleSize会导致压缩的图片的宽高都为1/inSampleSize,整体大小变为原始图片的inSampleSize平方分之一,当然,这些有些注意点:
1、inSampleSize小于等于1会按照1处理
2、inSampleSize只能设置为2的平方,不是2的平方则最终会减小到最近的2的平方数,如设置7会按4进行压缩,设置15会按8进行压缩。
1 | options.inSampleSize = inSampleSize; |
- 缩放压缩
通过减少图片的像素来降低图片的磁盘空间大小和内存大小,可以用于缓存缩略图
实现方式如下:
1 | Bitmap bitmap = BitmapFactory.decodeFile(originFile.getAbsolutePath()); |
大图加载:从网络加载一个10M的图片,说下注意事项?
[Android高效加载大图、多图解决方案,有效避免程序OOM][Android_OOM]
由于Android加载大图时容易导致OOM,所以应该对大图的加载单独处理,共有3点需要注意:
- 图片压缩
由于图片的分辨率比手机屏幕分辨率高很多,因此应该根据ImageView控件大小对高分辨率的图片进行适当的压缩,防止OOM出现。 - 分块加载
如果图片尺寸过大,但指向获取图片的某一小块区域时,可以对图片分块加载。适用于地图绘制的场景。在Android中BitmapRegionDecoder类的功能就是加载一张图片的指定区域。
1 | // 创建实例 |
- 图片三级缓存机制——可以让组件快速地重新加载和处理图片,避免网络加载的性能损耗
图片的三级缓存机制是指加载图片时,分别访问内存、文件和网络而获取图片数据的机制。
- 一级:内存缓存LruCache
LruCache是Android提供的一个缓存工具类,采用最近最少使用算法。把最近使用的对象用强引用存储在LinkedHashMap中,并把最近最少使用的对象在缓存值达到预设定值之前从内存中移除。
Android先访问内存,如果内存中没有缓存数据,则访问缓存文件。 - 二级:文件缓存
DiskLruCache是缓存工具类,存储位置是外存。
缓存数据的存储路径优先考虑SD卡的缓存目录,在SD卡下新建一个缓存文件用来存储缓存数据。若缓存文件中没有缓存数据,则联网加载图片。 - 三级:联网加载
通过网络请求加载网络图片,并将图片数据保存到内存和缓存文件中。
说一下三级缓存的原理?
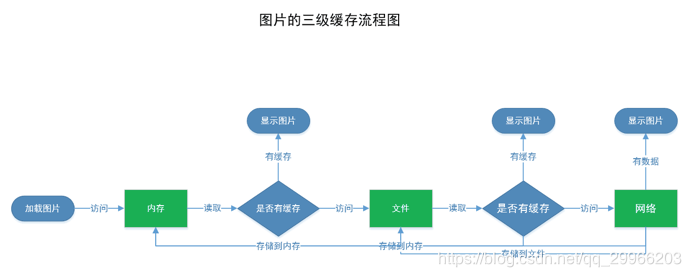
1 | /** |
LruCache & DiskLruCache原理?
- LruCache 内存缓存
LruCache是android提供的一个缓存工具类(android-support-v4包),其算法是LRU(最近最少使用)算法。
它把最近使用的对象用“强引用”存储在LinkedHashMap中,并且把最近最少使用的对象在缓存值达到预设定值之前就从内存中移除。
适用于缓存图片。 - 源码分析
算法原理:
LruCache把最近使用的对象用强引用存储在 LinkedHashMap 中,并且把最近最少使用的对象在缓存值达到预设定值之前从内存中移除。(最近使用的数据在尾部,老数据在头部)
put
1 | public class LruCache<K, V> { |
trimToSize(maxSize)
1 | public void trimToSize(int maxSize) { |
get
1 | public final V get(K key) { |
由此可见LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。
- 当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就删除队头元素,即近期最少访问的元素。
- 当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队尾。
- 使用
初始化缓存类,设定大小并重写sizeOf()方法
1 | /* 内存缓存 */ |
重写 添加/删除 缓存
1 | //将bitmap添加到内存中去 |
LruCache加载图片 实例
1 | public void loadBitmap(int resId, ImageView imageView) { |
- DiskLruCache 硬盘/外存缓存
不同于LruCache,LruCache是将数据缓存到内存中去,而DiskLruCache是外部缓存(默认位置:/sdcard/Android/data//cache),例如可以将网络下载的图片永久的缓存到手机外部存储中去,并可以将缓存数据取出来使用,DiskLruCache不是google官方所写,但是得到了官方推荐,DiskLruCache没有编写到SDK中去,是由square团队开发的一个第三方开源库。 - 打开缓存
首先调用getDiskCacheDir()方法获取到缓存地址的路径,然后判断一下该路径是否存在,如果不存在就创建一下。接着调用DiskLruCache的open()方法来创建实例,并把四个参数传入即可。
1 | DiskLruCache mDiskLruCache = null; |
getDiskCacheDir
缓存地址通常都会存放在 /sdcard/Android/data//cache 这个路径下面,但如果这个手机没有SD卡,或者SD正好被移除了的情况,应该专门写一个方法来获取缓存地址
1 | public File getDiskCacheDir(Context context, String uniqueName) { |
- 写入缓存
1 | new Thread(new Runnable() { |
hashKeyForDisk
写入的操作是借助DiskLruCache.Editor这个类完成,通过调用DiskLruCache的edit()方法来获取实例,edit(String key)接口需要传入一个参数key,这个key将会成为缓存文件的文件名,并且必须要和图片的URL是一一对应的。(不适合直接用URL作为key:1.过长2.含特殊字符)最简单的做法就是将图片的URL进行MD5编码,编码后的字符串肯定是唯一的,并且只会包含0-F这样的字符,完全符合文件的命名规则。
1 | public String hashKeyForDisk(String key) { |
访问urlString中传入的网址,并通过outputStream写入到本地
1 | private boolean downloadUrlToStream(String urlString, OutputStream outputStream) { |
- 读取缓存
1 | try { |
- LruCache & DiskLruCache 对比
| 缓存 | LruCache | DiskLruCache |
|---|---|---|
| 简介 | 内存缓存 | 硬盘/外存缓存 |
| 核心算法 | LRU | LRU |
| 存储位置 | 内存 | /sdcard/Android/data//cache SD卡 |
| 特点 | 读写速度快,存储空间小 | 读写速度稍慢,存储空间大 |
如果让你设计一个图片加载库,你会如何设计?
[Android高效异步图片加载框架][Android]
整体架构
- 单例实现:单例模式调用图片加载框架
- 缓存策略:三级缓存策略(LruCache内存缓存、DiskCache硬盘缓存、联网加载)
- 任务队列:每发起一个新的加载图片的请求,封装成Task添加到的任务队列TaskQueue中去(FIFO)
- 线程池:后台轮询线程。该线程在第一次初始化实例的时候启动,然后会一直在后台运行;当每发起一次加载图片请求的时候,除了会创建一个新的任务到任务队列TaskQueue中去,同时发一个消息到后台线程,后台线程去使用线程池去TaskQueue去取一个任务执行
(线程池:在任务众多的情况下,系统要为每一个任务创建一个线程,而任务执 行完毕后会销毁每一个线程,所以会造成线程频繁地创建与销毁。) - 图片压缩:将图片实际大小按缩放比进行压缩
具体实现
- 初始化 图片加载类
- 单例模式创建实例,并初始化信息
1 | public class XCImageLoader{ |
- 后台轮询线程
后台线程中,创建一个Handler用来处理图片加载任务发过来的图片显示消息
1 | /** |
- 加载图片
采用三级缓存策略处理图片加载
- 从内存LruCache中加载,如果存在则从LruCache中取出显示。否则,新建一个图片加载任务并添加到任务队列,此时会通知后台线程去线程池中取出一个线程来执行。
- 从硬盘DiskCache中加载,如果存在则从本地文件中加载显示。
- 否则从网络直接下载图片并显示。
- 将图片写入LruCache和DiskCache中
1 | /** |
1 | /** |
- 显示图片
很多情况下,网络或者本地的图片都比较大,而用于显示ImageView显示大小比较小,这时候就需要我们进行图片的压缩,再显示到ImageView上面去。节省内存。
1 | /** |
通过UIHandler发消息来显示Bitmap到ImageView上去
1 | /** |
Github 下载经典实例分析
1 | public class ImageLoader { |
第七章 布局
- 布局
- 六大布局 特点
- 约束布局
- LinearLayout,RelativeLayout性能对比
- 检测布局深度
- 布局优化
- include、merge、ViewStub标签
- 面试
- 你知道布局文件到控件对象的过程吗?(Android布局文件映射源码分析)
布局
六大布局 特点
[菜鸟教程][Link 7]
[Android知识体系总结之Android部分之Android中的布局篇][Android_Android_Android]
| 布局 | 介绍 | 常用属性 |
|---|---|---|
| LinearLayour 线性布局 |
LinearLayout容器中的组件一个挨一个排列,通过控制android:orientation属性,可控制各组件是横向排列还是纵向排列 | orientation:布局中组件排列方式 gravity:该组件所包含的子元素的对齐方式(horizontal/vertical) layout_gravity:该组件在父容器里的对齐方式 layout_width:布局的宽度(wrap_content(布局实际大小)/match_parent(填满父容器)) layout_height:布局的高度(参数同上) layout_weight:布局的权重(需要相应设置layout_height/width=0dp) |
| RelativeLayout 相对布局 |
相对布局可以让子控件以其兄弟控件或父控件为参考按照其相对位置进行布局,适用于复杂的嵌套布局 | 1. 根据父容器定位,如layout_alignParentLeft\Right\Top\Bottom(左\右\顶部\底部对齐)layout_centerHorizontal\Vertical\InParent(水平\垂直\整体居中) 2. 根据兄弟组件定位,如layout_toLeftOf\RightOf\above\below(参考组件左\右\上\下方)layout_alignTop\Bottom\Left\Right(顶部\底部\左\右对齐) 3. margin:偏移,设置该组件与父容器的边距 4. padding:填充,设置组件内部元素间的边距 |
| TableLayout 表格布局 |
TableLayout继承自Linearout,本质上仍然是线性布局管理器。表格布局采用行、列的形式来管理UI组件 每个TableLayout都是由一个或多个TableRow组成的,一个TableRow就代表TableLayout的一行 (不声明行数、列数。tablerow的个数为表格的行数,tablerow中组件个数为该行的列数) |
android:collapseColumns:设置需要被隐藏的列的序号 android:shrinkColumns:设置允许被收缩的列的列序号 android:stretchColumns:设置运行被拉伸的列的列序号 android:layout_column=“2”:表示的就是跳过第二个,直接显示到第三个格子处(从1开始计算) android:layout_span=“4”:表示合并4个单元格,也就说这个组件占4个单元格 |
| FrameLayout 帧布局 |
帧布局或叫层布局,从屏幕左上角按照层次堆叠方式布局,后面的控件覆盖前面的控件。帧布局为每个加入其中的组件创建一个空白的区域(称为一帧),每个子组件占据一帧,这些帧会根据gravity属性执行自动对齐 | android:foreground:设置改帧布局容器的前景图像 android:foregroundGravity:设置前景图像显示的位置 |
| GridLayout 表格布局 |
GridLayout把整个容器划分为rows × columns个网格,每个网格可以放置一个组件。提供了setRowCount(int)和setColumnCount(int)方法来控制该网格的行和列的数量 | android:orientation:子组件排列方式 android:layout_gravity:子组件对齐方式 android:rowCount:设置网格布局行数 android:columnCount:设置网格布局列数 android:layout_row:设置该组件位于第几行 android:layout_columnL设置该组件位于第几列 |
| AbsoluteLayout 绝对布局(过时) |
约束布局
ConstraintLayout则是使用约束的方式来指定各个控件的位置和关系的,它有点类似于RelativeLayout,但远比RelativeLayout要更强大。
ConstraintLayout非常适合使用可视化方式编写界面(而不适合用XML书写),且ConstraintLayout可以有效地解决布局嵌套过多的问题(复杂的布局总会伴随着多层的嵌套,而嵌套越多,程序的性能也就越差)
[Android新特性介绍:ConstraintLayout完全解析][Android_ConstraintLayout]
LinearLayout,RelativeLayout性能对比
- 在不影响层级深度的情况下,使用LinearLayout和FrameLayout而不是RelativeLayout
根据LinearLayout、FrameLayout和RelativeLayout的onMeasure()源码可分析得,相同层级下RelativeLayout性能最低:
- RelativeLayout会让子View调用2次onMeasure
- 若当前RelativeLayout布局的子View计算的高度与RelativeLayout布局不同,会引发效率问题
- 如果能用RelativeLayout减少LinearLayout布局的层级,则使用RelativeLayout
采用尽量少的View层级来表达布局以实现性能最优,因为复杂的View嵌套对性能的影响会更大一些。 - LinearLayout慎用layout_weight
LinearLayout 在有weight时,也会调用子View2次onMeasure
检测布局深度
- Dump UI Hierarchy for UI Atomator,分析UI层级
- HierachyViewer
布局优化
- 布局优化思想
减少Overdraw(过度绘制)(一般通过减少UI层级、简化布局实现)
Overdraw:描述的是屏幕上的某个像素在同一帧时间内被绘制了多次。在多层次的UI结构里面,如果不可见的UI也在做绘制的操作,就会导致某些像素区域被绘制了多次,浪费大量的CPU以及GPU资源。
- 布局优化方法
- 善用相对布局RelativeLayout
可以通过扁平的RelativeLayout降低LinearLayout嵌套所产生布局树的层级 - 使用抽象布局标签include、merge、ViewStub
- < include />
include标签常用于将布局中的公共部分提取出来 - < merge />
merge标签是作为include标签的一种辅助扩展来使用,它的主要作用是为了防止在引用布局文件时产生多余的布局嵌套(merge能够减少include可能产生的层级) - < ViewStub />
ViewStub是View的子类。他是一个轻量级View, 隐藏的,没有尺寸的View。他可以用来在程序运行时简单的填充布局文件
- 使用Android最新的布局方式ConstaintLayout
ConstraintLayout允许你在不适用任何嵌套的情况下创建大型而又复杂的布局。它与RelativeLayout非常相似,所有的view都依赖于兄弟控件和父控件的相对关系。但是,ConstraintLayout比RelativeLayout更加灵活
include、merge、ViewStub标签
- include
include标签常用于将布局中的公共部分提取出来,解决重复定义布局的问题。
下面是一个自定义的titlebar文件:
1 | <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" |
在应用中使用titlebar布局文件,我们通过标签,布局文件如下:
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
- merge
merge标签与include标签组合使用,可以有效减少View树的层次来优化布局
一个线性布局中嵌套一个文本视图,主布局如下:
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
(1)单独使用include标签的嵌套布局,下面是嵌套布局的include_text.xml文件:
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
通过hierarchyviewer我们可以看到主布局View树的部分层级结构如下图:
(2)merge与include标签组合使用的布局,下面是嵌套布局的include_text.xml文件:
1 | <merge xmlns:android="http://schemas.android.com/apk/res/android" > |
通过hierarchyviewer我们可以看到主布局View树的部分层级结构如下图:
对比截图就可以发现上面的四层结构,现在已经是三层结构了。当我们使用标签的时候,系统会自动忽略merge层级,而把TextView直接放置与平级。
- ViewStub
ViewStub 标签实质上是一个宽高都为 0 的不可见 的轻量级View,占用资源非常小。可以通过延迟加载布局的方式优化布局提升渲染性能。适用于布局复杂却很少用的布局,如网络请求失败提示,列表为空提示,引导界面等。
这里的延迟加载是指初始化时, 程序无需显示该标签所指向的布局文件(ViewStub 控件占用内存相比于其他控件很小)。 只有在特定的条件下(View.setVisibility(View.VISIBLE)或View.inflate()), 所指向的布局文件才需要被渲染, 且此布局文件直接将当前的 ViewStub 替换掉。
在开发过程中,经常会遇到这样一种情况,有些布局很复杂但是却很少使用。例如条目详情、进度条标识或者未读消息等,这些情况如果在一开始初始化,虽然设置可见性View.GONE,但是在Inflate的时候View仍然会被Inflate,仍然会创建对象,由于这些布局又相当复杂,所以会很消耗系统资源。
定义ViewStub布局文件
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
layout_image.xml文件如下
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
加载ViewStub布局文件:
动态加载ViewStub所包含的布局文件有两种方式,方式一使用使用inflate()方法,方式二就是使用setVisibility(View.VISIBLE)。
ViewStub一旦visible/inflated,此时ViewStub所指向的布局文件(layout_image.xml)替换掉当前的ViewStub控件,它自己就不在是View试图层级的一部分了。所以后面无法再使用ViewStub来控制布局。
1 | private ViewStub viewStub; |
示例View层级截图如下:
面试
你知道布局文件到控件对象的过程吗?(Android布局文件映射源码分析)
| 布局文件映射两种方式 | setContentView() | inflate() |
|---|---|---|
| 调用 | setContentView(R.layout.main) |
View view = inflate.inflate(R.layout.main,null); |
| 作用 | 将XML布局文件直接显示UI | 将XML布局文件转换为一个View对象 |
第八章 性能优化
- 内存优化
- ANR & CRASH 产生的原因是什么?如何解决?
- 内存溢出 & 内存泄漏 & 内存抖动 是什么?产生原因?解决方案?
- Bitmap优化 原因 & 方案?
- 谈谈你项目中内存优化的一些经验?
- 启动优化
- 什么是冷启动 & 热启动?启动流程?如何优化启动?
- 布局优化
- 你知道哪些布局优化的方案?
内存优化
[Carson_Ho:Android性能优化:这是一份全面&详细的内存优化指南][Carson_Ho_Android]
ANR & CRASH 产生的原因是什么?如何解决?
| 定义 | 原因 | 解决 | |
|---|---|---|---|
| ANR | application not response,应用程序的UI线程响应超时 | 一般是主线程未及时响应用户的输入事件(如触摸、按键);或者当前的事件正在被处理,但是由于耗时太长没有能够及时完成 常见:主线程频繁进行耗时操作 |
使用多线程,将耗时操作交给工作线程执行 |
| Crash | 应用程序崩溃 | 引起应用程序崩溃的很多原因时因为内存溢出OOM,因此需要避免OOM现象 | 内存优化,如: 1. 避免内存泄露 2. 避免内存抖动 3. 图片Bitmap优化 4. 提高代码质量 & 减少代码数量 |
内存溢出 & 内存泄漏 & 内存抖动 是什么?产生原因?解决方案?
- 内存泄露
- 定义
当一个对象已经不需要再使用本该被回收时,另外一个正在使用的对象持有它的引用从而导致它不能被回收,这导致本该被回收的对象不能被回收而停留在堆内存中,这就产生了内存泄漏。 - 本质原因
持有引用的对象的生命周期>被引用的对象的生命周期 - 内存泄露 原因 & 解决方案
(1)集合类 - 原因
集合中添加对象时,集合会存储着该对象的引用。导致该对象不可被回收,从而引起内存泄露。
1 | public void example(){ |
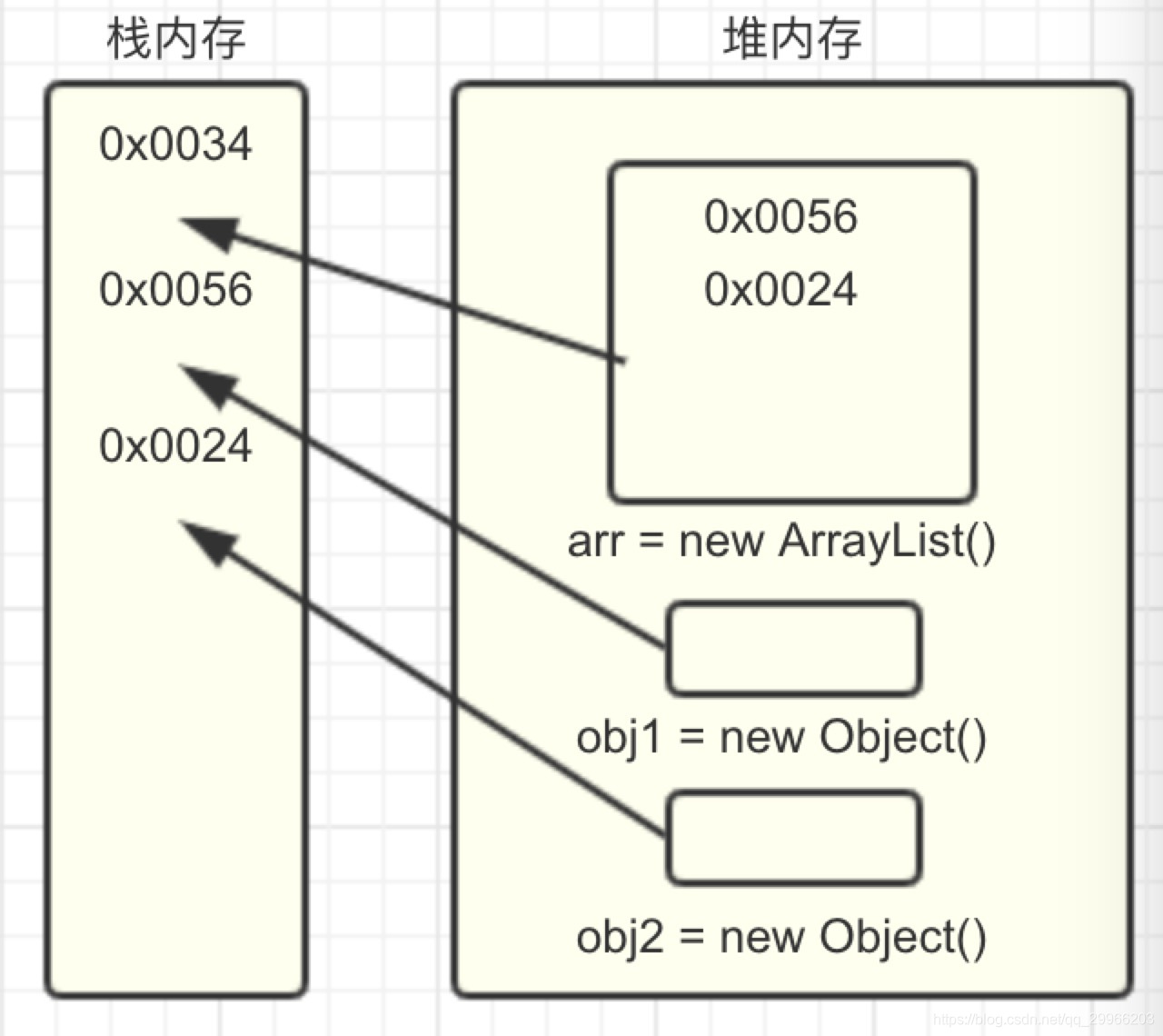
- 解决
集合类 添加集合元素对象 后,在使用后必须从集合中删除
1 | // 清空集合对象 & 设置为null |
(2)Static关键字修饰成员变量
- 原因
由于Static关键字修饰的成员变量的生命周期 = 应用程序的生命周期。若Static关键字所引用实例 < 应用程序的生命周期时,当引用实例需结束生命周期销毁时,会因静态变量的持有而无法被回收,从而出现内存泄露。
1 | // 单例模式 |
- 解决
- 尽量避免 Static 成员变量引用资源耗费过多的实例(如 Context)。若需引用 Context,则尽量使用Applicaiton的Context
- 使用 弱引用(WeakReference) 代替 强引用 持有实例
1 | public SingleInstance(context){ |
(3)非静态内部类/匿名类
[菜鸟教程:Java 内部类详解][Java]
非静态内部类 / 匿名类 默认持有 外部类的引用:因为非静态内部类依赖外部类,可以通过内部类对外部类的引用来访问外部类的成员变量和成员方法。
而静态内部类则不持有外部类的引用:静态内部类不依赖外部类。
(3.1)多线程:AsyncTask、实现Runnable接口、继承Thread类
- 原因
多线程类为非静态内部类/匿名类,实例化后默认持有外部类的引用。因此当工作线程正在处理任务时,当Activity被销毁时,由于工作线程持有外部类Activity的引用,导致Activity无法被垃圾回收器回收,从而造成内存泄露。
1 | public class MainActivity extends Activity{ |
- 解决
(1)将非静态内部类 设置为 静态内部类
静态内部类 不默认持有外部类的引用,因此工作线程不持有MainActivity的引用
1 | public static class MyThread extends Thread{ |
(2)当外部类结束生命周期时,强制结束线程
1 |
|
(3.2)消息传递机制Handler
- 原因
因为消息队列中的Message持有Handler实例的引用,Handler实例为 非静态内部类/匿名类 持有外部类Activity的引用。即Message->Handler->Activity。
因此当Handler 消息队列中仍有未处理的消息/正在处理消息时,若外部类MainActivity销毁(Handler 生命周期 > Activity 生命周期),由于Activity被引用,因此GC无法回收MainActivity导致内存泄露 - 解决
将Handler子类设置为静态内部类 ,则Handler不会引用MainActivity实例
使用WeakReference弱引用持有Activity实例,则垃圾回收期进行扫描时,只要发现了具有弱引用的对象,便会回收它的内存
1 | public class MainActivity extends Activity{ |
(4)资源对象使用后未关闭
- 原因
对于资源的使用(如 广播BraodcastReceiver、文件流File、数据库游标Cursor、图片资源Bitmap等),若在Activity销毁时无及时关闭 / 注销这些资源,则这些资源将不会被回收,从而造成内存泄漏 - 解决
在Activity销毁时 及时关闭 / 注销资源
1 | // 对于 广播BraodcastReceiver:注销注册 |
(5)其他
- Context
Context的生命周期大于Context所引用实例的生命周期时,会造成内存泄露。应该尽量使用ApplicationContext代替ActivityContext。 - ListView
在滑动ListView获取最新的View时,每次都在getView()中重新实例化一个View对象,不仅浪费资源、时间,也使内存占用越来越大。导致内存泄露。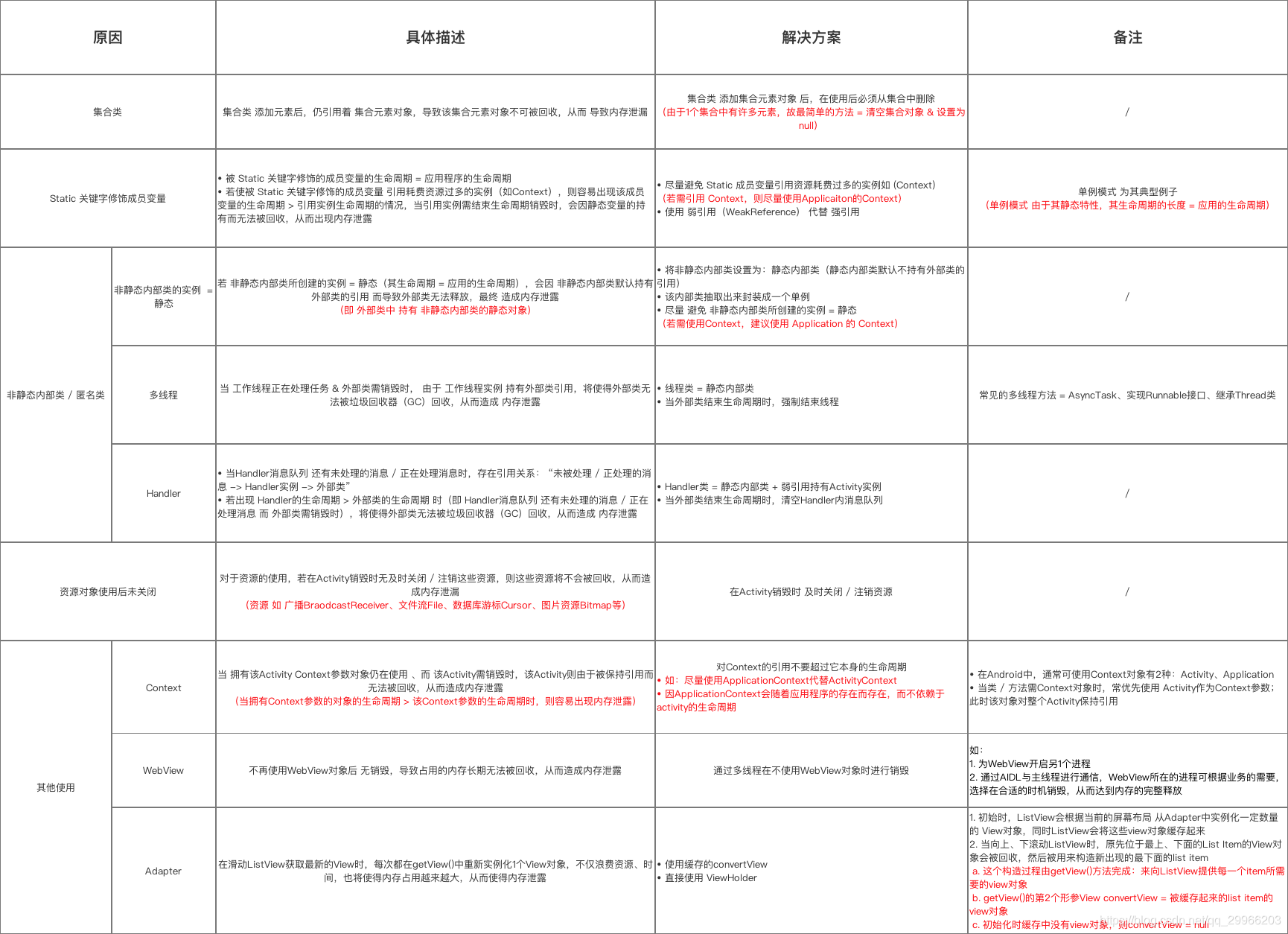
- 内存溢出 & 内存泄露 & 内存抖动 对比
| 定义 | 原因 | 解决 | |
|---|---|---|---|
| 内存溢出 | 应用程序所需内存超出系统分配的内存限额,从而导致内存溢出 | 内存中加载的数据量过于庞大,如一次从数据库取出过多数据 内存泄露 代码中存在死循环或循环产生过多重复的对象实体(内存抖动) 使用的第三方软件中的BUG 启动参数内存值设定的过小 |
|
| 内存泄露 | 当一个对象已经不需要再使用本该被回收时,另外一个正在使用的对象持有它的引用从而导致它不能被回收,这导致本该被回收的对象不能被回收而停留在堆内存中,这就产生了内存泄漏 | 持有引用者的生命周期>被引用者的生命周期: 集合类 Static关键字修饰成员变量 非静态内部类/匿名类 资源对象使用后未关闭 |
集合类:回收集合元素 Static关键字修饰的成员变量:避免Static引用过多实例 非静态内部类/匿名类:使用静态内部类 资源使用后未关闭:关闭资源对象 |
| 内存抖动 | 内存大小不断浮动的现象 | 由于大量、临时的小对象频繁创建,导致程序频繁地分配内存 & 垃圾回收器(GC)频繁回收内存 垃圾收集器(GC)频繁地回收内存会导致卡顿,甚至内存溢出(OOM)——大量、临时的小对象频繁创建会导致内存碎片,使得当需分配内存时,虽总体上有剩余内存可分配,但由于这些内存不连续,导致无法模块分配。系统则视为内存不够,故导致内存溢出OOM |
尽量避免频繁创建大量、临时的小对象 |
- 辅助分析内存泄露的工具
- MAT(Memory Analysis Tools)
- Heap Viewer
- Allocation Tracker
- Memory Monitor(Android Studio 自带 的图形化检测内存工具,用于跟踪系统 / 应用的内存使用情况)
- LeakCanary
Bitmap优化 原因 & 方案?
- 原因
图片资源(Bitmap)非常消耗内存,占用App内存大部分。Android系统分配给每个应用程序内存有限,因此可能引发内存溢出(OOM),导致应用崩溃(Crash) - 方案
- 使用完毕后释放图片资源
1 | // 方案1:采用软引用 |
- 根据分辨率适配 & 缩放图片
1 | public void decodeSampledBitmapFromResource(Resources res, int resId,int reqWidth, int reqHeight){ |
- 按需选择合适的解码方式
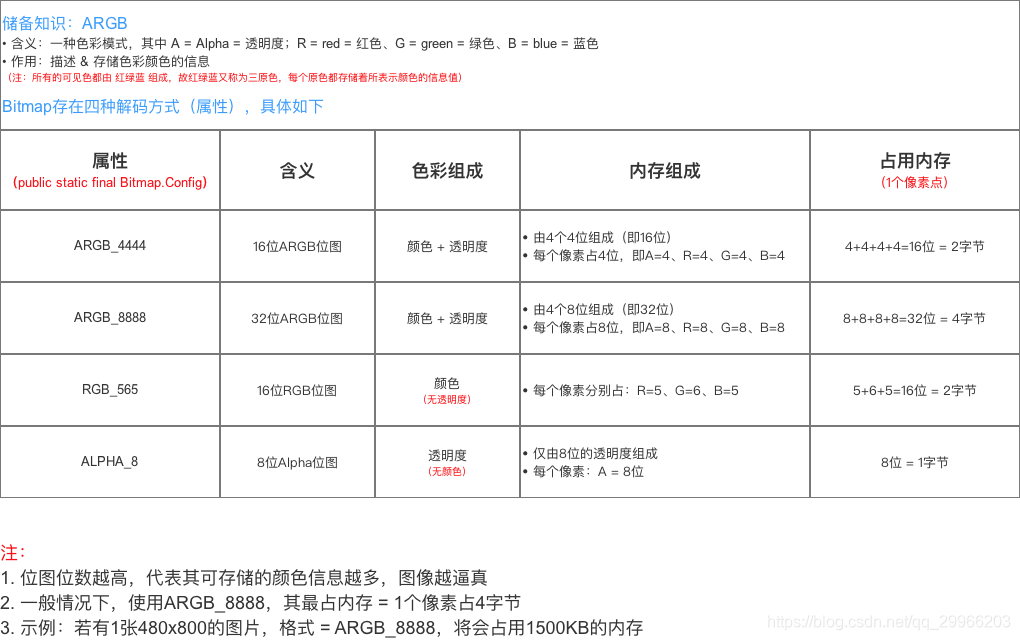
不同的图片解码方式 对应的 内存占用大小 相差很大。根据需求通过 BitmapFactory.inPreferredConfig 设置 合适的解码方式。(默认使用的解码方式:ARGB_8888) - 设置图片缓存——三级缓存机制
1 | /** |
谈谈你项目中内存优化的一些经验?
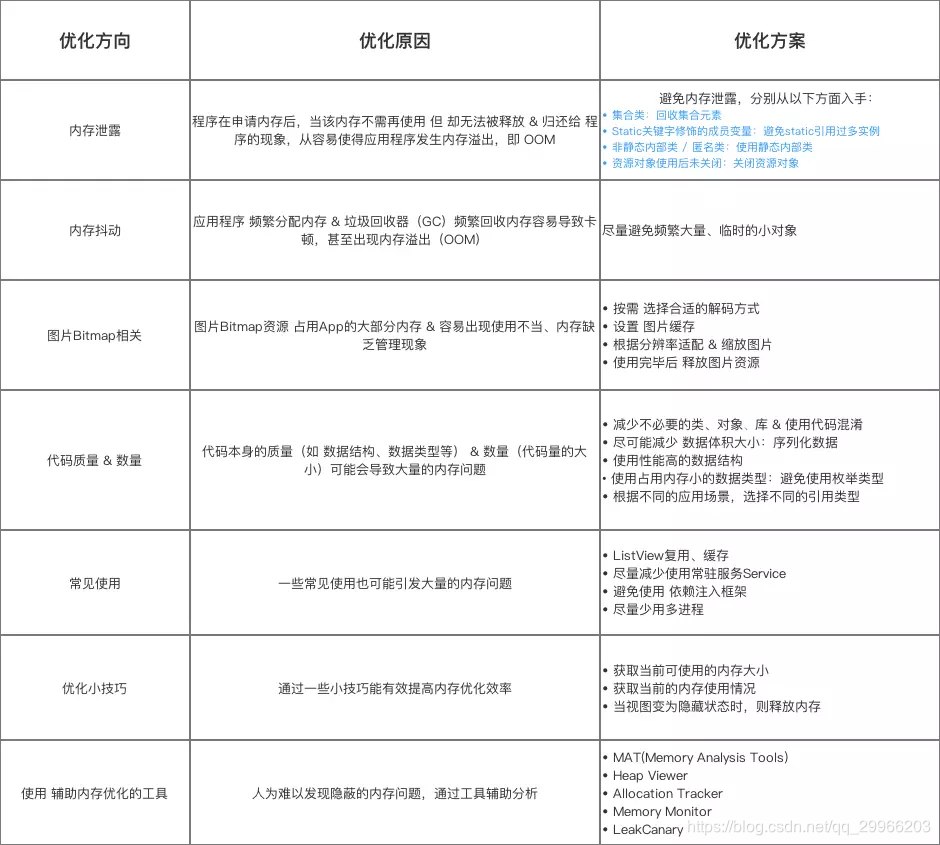
启动优化
什么是冷启动 & 热启动?启动流程?如何优化启动?
- 冷启动 & 热启动
| 方式 | 冷启动 | 热启动 |
|---|---|---|
| 定义 | 启动应用时,后台没有该应用的进程(例:第一次开启应用,上一次彻底退出应用),这时系统会重新创建一个新的进程分配给该应用,这种启动方式就是冷启动 | 启动应用时,后台已有该应用的进程(例:按back,home键,应用退出,但仍保留在后台,可进入任务列表查看),从已有的进程中启动应用,这种启动方式就是热启动 |
| 特点 | 系统会重新创建一个新进程分配给它。 因此会先创建和初始化Application类,再创建和初始化MainActivity类,包括一系列测量布局绘制,最后显示在界面上 |
系统直接从已有进程中启动应用。 因此不必创建和初始化Application,直接创建和初始化MainActivity,包括一系列测量不聚会知,显示在界面上 |
| 流程 | Zygote进程中fork创建出一个新的进程 –> Application构造器 –> attachBaseContext() –> onCreate() –> Activity构造器 –> onCreate –> 配置主题背景等属性 –> onStart() –> onResume –> 测量布局绘制显示在界面上 | (没有Application创建和初始化)Activity构造器 –> onCreate –> 配置主题背景等属性 –> onStart() –> onResume –> 测量布局绘制显示在界面上 |
- 优化启动方案
- 黑白屏优化
系统在启动Activity的setContentView之前绘制窗体,此时布局资源还未加载,于是使用了默认的背景色。
解决:把启动图bg_splash设置为窗体背景,避免刚刚启动App的时候出现,黑/白屏
1 | <style name="Theme.AppLauncher" parent="@android:style/Theme.NoTitleBar.Fullscreen"> |
配置启动页面SplashActivity的清单文件
1 | <activity android:name="tv.douyu.view.activity.SplashActivity" |
- onCreate优化
onCreate()耗时长会影响应用程序布局绘制的时间。因此应该减少onCreate工作量。
一般重写Application,在onCreate()方法中做一些初始化操作(如第三方SDK配置),可以将这些较大的第三方库通过开启一个异步线程中进行初始化。
布局优化
你知道哪些布局优化的方案?
[Android性能优化之布局优化][Android]
- 布局优化思想
减少Overdraw(过度绘制)(一般通过减少UI层级、简化布局实现)
Overdraw:描述的是屏幕上的某个像素在同一帧时间内被绘制了多次。在多层次的UI结构里面,如果不可见的UI也在做绘制的操作,就会导致某些像素区域被绘制了多次,浪费大量的CPU以及GPU资源。
- 布局优化方法
- 善用相对布局RelativeLayout
可以通过扁平的RelativeLayout降低LinearLayout嵌套所产生布局树的层级 - 使用抽象布局标签include、merge、ViewStub
[include、merge、ViewStub标签?][include_merge_ViewStub]
- < include />
include标签常用于将布局中的公共部分提取出来 - < merge />
merge标签是作为include标签的一种辅助扩展来使用,它的主要作用是为了防止在引用布局文件时产生多余的布局嵌套(merge能够减少include可能产生的层级)
直接使用include标签引入了之前的LinearLayout之后导致了界面多了一个层级,若引入merge标签则可以减少一个层级 - < ViewStub />
ViewStub是View的子类。他是一个轻量级View, 隐藏的,没有尺寸的View。他可以用来在程序运行时简单的填充布局文件
- 使用Android最新的布局方式ConstaintLayout
ConstraintLayout允许你在不适用任何嵌套的情况下创建大型而又复杂的布局。它与RelativeLayout非常相似,所有的view都依赖于兄弟控件和父控件的相对关系。但是,ConstraintLayout比RelativeLayout更加灵活
第九章 JNI
- JNI
- JNI & NDK
- JNI 原理 —— 为什么java能够调用c/c++函数
- JNI如何实现数据传递?
- 你用JNI实现过什么功能吗?怎么实现的?
[JNI:java native方法与JNI实现][JNI_java native_JNI]
JNI
JNI & NDK
JNI & NDK 定义 & 介绍 & 区别
| JNI | NDK | |
| 定义 | Java Native Interface,即 Java本地接口 | Native Development Kit,是 Android的一个工具开发包 |
| 简介 | 使得Java 与 本地其他类型语言(如C、C++)交互 即在 Java代码 里调用 C、C++等语言的代码 或 C、C++代码调用 Java 代码 |
快速开发C、 C++的动态库,并自动将so和应用一起打包成 APK 即可通过NDK在Android中使用JNI与本地代码(C/C++)交互 |
| 作用 | 因为Java具备跨平台的特点,所以Java与本地代码交互能力很弱,通过 JNI 增强Java与本地代码进行交互能力 1. 运行效率高:java是解释型语言,运行效率较低,C/C++效率高很多通过JNI把耗时操作交给C/C++能提高Java运行效率 2. 安全性高:java代码编译成的.class文件安全性较低,可通过JNI把重要的业务逻辑交给C/C++实现。由于C/C++反编译困难,因此安全性较高 3. 功能扩展性好:可以方便使用其他开发语言的开源哭 4. 易于代码复用和移植:使用本地代码(C/C++)开发的代码不仅可以在Android使用,还可以在别的平台上使用 |
|
| 使用 | 1. 在Java中声明Native方法(即需要调用的本地方法) 2. 编译上述 Java源文件javac(得到 .class文件) 3. 通过 javah 命令导出JNI的头文件(.h文件) 4. 使用 Java需要交互的本地代码 实现在 Java中声明的Native方法 5. 编译.so库文件 6. 通过Java命令执行 Java程序,最终实现Java调用本地代码 |
1. 配置 Android NDK环境 2. 创建 Android 项目,并与 NDK进行关联 3. 在 Android 项目中声明所需要调用的 Native方法 4. 使用 Android需要交互的本地代码 实现在Android中声明的Native方法(比如 Android 需要与 C++ 交互,那么就用C++ 实现 Java的Native方法) 5. 通过 ndk - bulid 命令编译产生.so库文件 6. 编译 Android Studio 工程,从而实现 Android 调用本地代码 |
| 联系 | JNI是实现的目的,NDK是Android中实现JNI的工具。 在Android开发环境中,通过 NDK开发工具包 实现 JNI 的功能(实现java 与本地语言交互) |
|
JNI 原理 —— 为什么java能够调用c/c++函数
(1)创建JNI函数并最终编译成.dll(Windows)/.so(Unix)(这里文件类型根据机器类型自动生成)
- 编写带有native声明的方法的java类,生成.java文件
- 使用javac命令编译所编写的java类,生成.class文件
- 使用javah -jni java类名生成扩展名为h的头文件,也即生成.h文件
- 使用C/C++(或者其他编程想语言)实现本地方法,创建.h文件的实现,也就是创建.cpp文件实现.h文件中的方法
- 将C/C++编写的文件生成动态连接库,生成dll文件
(2)当一个类第一次被使用到时,这个类的字节码会被加载到内存,并且只会加载一次。在这个被加载的字节码的入口维持着一个该类所有方法描述符的list,这些方法描述符包含这样一些信息:方法代码存于何处,它有哪些参数,方法的描述符(public之类)等等。
如果一个方法描述符内有native,这个描述符块将有一个指向该方法的实现的指针。这些实现在一些DLL文件内,但是它们会被操作系统加载到java程序的地址空间。当本地方法被调用时,虚拟机通过调用java.system.loadLibrary()加载这些DLL文件实现本地方法。
JNI如何实现数据传递?
- Java调用C/C++语言
在Java中声明Native方法(即需要调用的本地方法)
编译上述 Java源文件javac(得到 .class文件)
通过 javah 命令导出JNI的头文件(.h文件)
使用 Java需要交互的本地代码 实现在 Java中声明的Native方法
编译.so库文件
通过Java命令执行 Java程序,最终实现Java调用本地代码 - JNI调用Java层代码
从classpath路径下搜索ClassMethod这个类,并返回该类的Class对象
获取类的默认构造方法ID
查找实例方法的ID
创建该类的实例
调用对象的实例方法
你用JNI实现过什么功能吗?怎么实现的?
第十章 线程 / 进程
- 基本线程实现(Thread & Runnable)
- 线程池(ThreadPoolExecutor)
- 简介 & 优势
- 使用
- 工作原理
- AsyncTask
- 是什么?能解决什么问题?
- 三个泛型参数作用 & 四个方法?每个方法在哪个线程执行?
- 实现原理?
- 不足之处 & 解决方法?
- Handler
- 子线程一定不能更新UI吗?为什么Android系统不建议子线程访问UI?
- 定义 & 作用 & 六大概念
- 使用
- Android 消息机制(工作原理 & 源码分析)
- 内存泄露 & 解决方案
- 面试
- HandlerThread
- 简介
- 具体使用
- 工作原理 & 源码分析
- IPC
- IPC 概述?
- Binder机制 简介 & 原理?
- 什么是AIDL?如何使用AIDL?AIDL工作原理(结合Binder)?
基本线程实现(Thread & Runnable)
- 继承Thread类
Thread类是Java中实现多线程的具体类,封装了所需线程操作。在Android开发中用于实现多线程
1 | // 步骤1:自定义线程类(继承自Thread类) |
- 实现Runnable接口
一个与多线程相关的抽象接口,仅定义1个方法=run(),在Android开发中用于实现多线程
1 | // 步骤1:创建线程辅助类,实现Runnable接口 |
- 实现Callable接口
创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。使用FutureTask类来包装Callable对象,通过调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
1 | public class CallableThreadTest implements Callable<Integer> { |
线程池(ThreadPoolExecutor)
简介 & 优势
线程的创建和销毁,都涉及到系统调用,消耗系统资源,所以就引入了线程池技术,避免频繁的线程创建和销毁
Java使用Executors接口表示线程池,具体实现类是ThreadPoolExecutor
- 通过复用缓存在线程池中的线程 降低 线程创建&销毁 造成的性能开销。
- 提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 防止线程并发数量过多,抢占系统资源从而导致阻塞。
- 提高线程的可管理性。使用线程池可以对线程进行统一的分配,调优和监控,如延时执行,定时循环执行等。
使用
1 | // 线程池的构造 |
工作原理
[线程池的工作原理与源码解读][Link 14]
[【细谈Java并发】谈谈线程池:ThreadPoolExecutor][Java_ThreadPoolExecutor]
核心参数
ThreadPoolExecutor参数最全的构造方法(根据需求配置参数)
1 | // 构造函数源码分析 |
| 参数 | 定义 | 说明 |
|---|---|---|
| corePoolSize | 核心线程数 | 线程池新建线程的时候,如果当前线程总数小于corePoolSize,则新建的是核心线程,如果超过corePoolSize,则新建的是非核心线程 核心线程默认情况下会一直存活在线程池中,即使这个核心线程啥也不干(闲置状态) |
| maximumPoolSize | 线程池所能容纳最大线程数 | 线程总数 = 核心线程数 + 非核心线程数 当线程总数达到该数值之后,新任务会被阻塞 |
| keepAliveTime | 非核心线程 限制超时时长 | 一个非核心线程,如果不干活(闲置状态)的时长超过这个参数所设定的时长,就会被销毁 |
| unit | 指定keepAliveTime参数的时间单位 | 枚举类型,keepAliveTime的单位,常用TimeUnit.MILLSECONDS毫秒、TimeUnit.SECOND秒、TimeUnit.MINUTE分 |
| workQueue | 任务队列 | 维护着等待执行的Runnable对象 当所有的核心线程都在干活时,新添加的任务会被添加到这个队列中等待处理,如果队列满了,则新建非核心线程执行任务 |
| threadFactory | 线程工厂 | 在线程池创建新线程的方式,这是一个接口。 实例化时需要实现他的Thread newThread(Runnable r)方法 |
| handler | 用于抛出异常 |
源码分析
1 | /** |
总结:
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务;
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中;
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务;
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
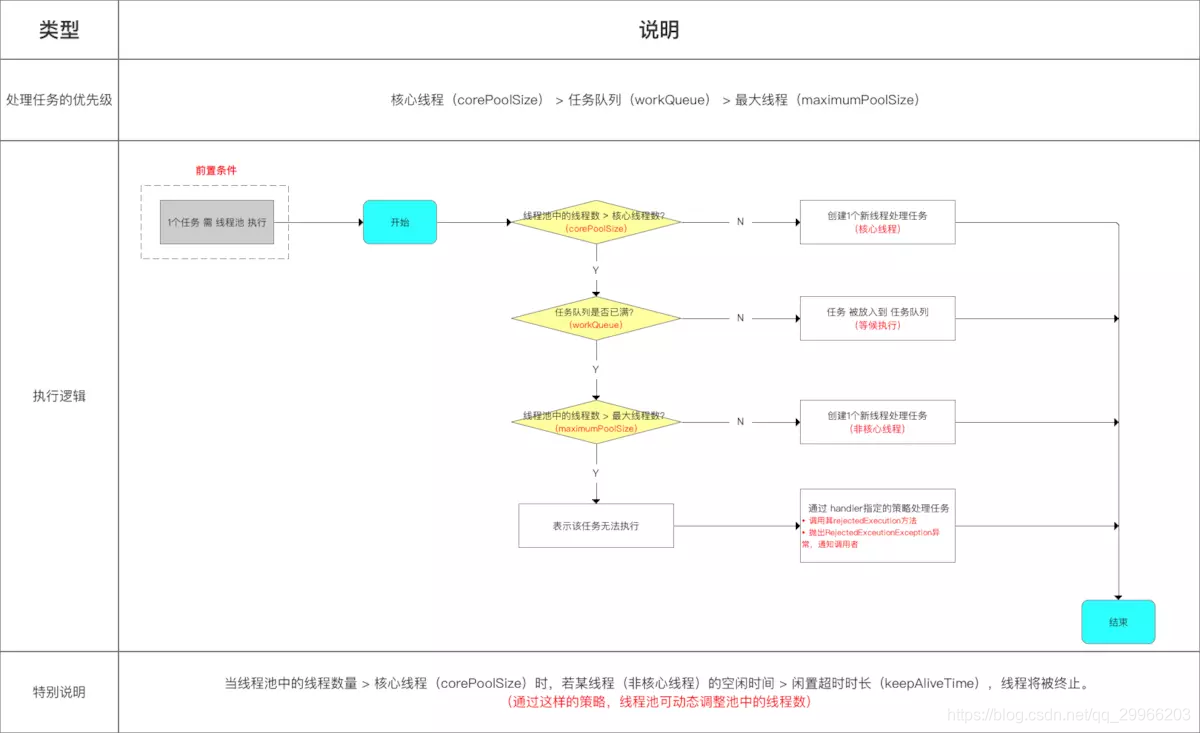
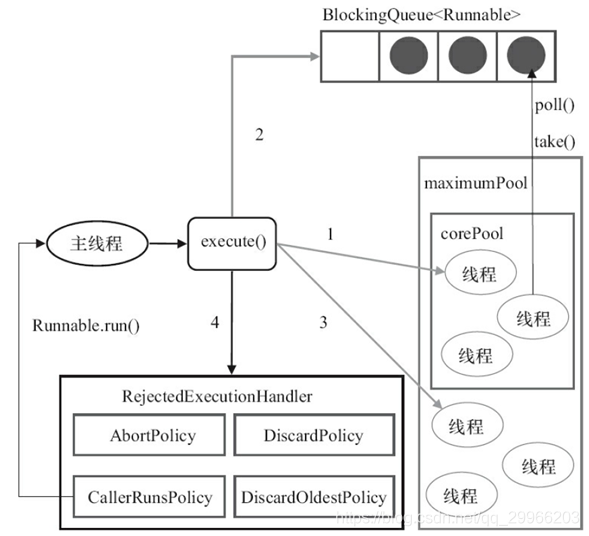
AsyncTask
[菜鸟教程——AsyncTask][AsyncTask 1]
[Android面试系列文章2018之Android部分AsyncTask机制篇][Android_2018_Android_AsyncTask]
是什么?能解决什么问题?
一个Android已封装好的轻量级异步类,属于抽象类,使用时需要实现子类。
它本质上是一个封装了 线程池 和 Handler 的异步框架。
线程池:缓存线程+复用线程,避免频繁创建 & 销毁线程 所带来的系统开销
用于:
- 异步任务,如在工作线程中执行耗时任务
- 消息传递,如实现工作线程 & 主线程 之间通信,即将工作线程处理结果传递给主线程,并在主线程中执行相关UI操作
- 和Handler一样用于处理异步任务,不过相对于前者,AsyncTask代码量更为轻量级,且后台是一个线程池,在异步任务数据比较庞大时更有优势。且使用更为简便、快捷。
三个泛型参数作用 & 四个方法?每个方法在哪个线程执行?
- 三个参数
当定义一个类来继承AsyncTask这个类时,需要为其指定3个泛型参数,用来控制AsyncTask子类执行线程各个任务时各个阶段的返回类型。
1 | public abstract class AsyncTask<Params, Progress, Result> { |
| 参数 | 说明 |
|---|---|
| Params | 开始异步任务执行时传入的参数类型,对应execute(params)中传递的参数 |
| Progress | 异步任务执行过程中,返回下载进度值的类型 |
| Result | 异步任务执行完成后,返回的结果类型,与doInBackground()的返回值类型保持一致 |
不需要指定类型时可以写成void
2. 四个方法
在主线程中执行异步任务时myAsyncTask.execute(params)时,AsyncTask会按照如下四个步骤分别执行
| 方法名 | 作用 | 调用时期 | 所在线程 | 说明 |
|---|---|---|---|---|
| onPreExecute() | 执行异步任务前的操作 | 执行 异步任务前自动调用 | 主线程 | 用于UI组件初始化操作,如显示进度条对话框 |
| *doInBackground(Params params) | 执行异步任务(接收输入参数并返回异步任务执行结果) | onPreExecute执行结束后,开始执行 异步任务时自动调用 | 子线程(后台线程池中开启一个工作线程执行) | 执行网络请求等耗时操作 |
| onProgressUpdate(Progress values) | 在主线程中显示 工作线程任务执行的进度 | 当任务状态发生变化时(通过publishProgress方法)自动调用 | 主线程 | 在doInBackground中调用publishProgress(Progress) 的方法来将我们的进度实时传递给 onProgressUpdate 方法来更新 |
| onPostExecute(Result result) | 接收异步任务执行结果,并将结果显示到UI组件 | 异步任务执行结束时自动调用 | 主线程 | 显示异步任务处理结果 |
- 基本使用
- 创建AsyncTask子类,为3个泛型参数指定类型;若不使用,可用void类型代替。
1 | private class MyTask extends AsyncTask<String, Integer, String> { |
- 创建Async子类的实例对象(任务实例)。必须在UI线程中创建,且同一个AsyncTask实例对象只能执行1次,若执行第2次会抛出异常。
1 | MyTask mTask = new MyTask(); |
- 手动调用execute()从而执行异步线程任务,必须在UI线程中调用
1 | mTask.execute(); |
实现原理?
[黑马视频:AsyncTask 源码][AsyncTask 2]
[Carson_Ho:AsyncTask的原理 及其源码分析][Carson_Ho_AsyncTask_]
AsyncTask基本使用
1 | public class MyAsyncTask extends AsyncTask<String,Integer,Bitmap>{ |
手动调用execute(Params… params),开始执行异步任务
1 | public final AsyncTask<Params, Progress, Result> execute(Params... params) { |
AsyncTask构造方法
- 创建了1个WorkerRunnable类 的实例对象 & 复写了call()方法
- 创建了1个FutureTask类 的实例对象 & 复写了 done()方法
1 | /** |
InternalHandler 接收 子线程 发送消息
1 | private void finish(Result result) { |
源码流程图
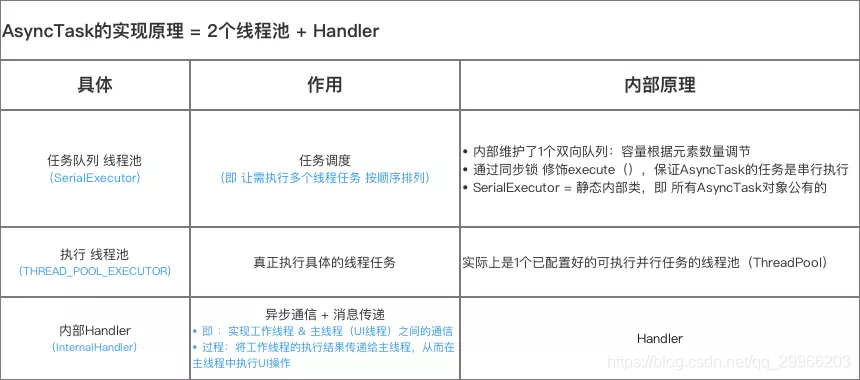
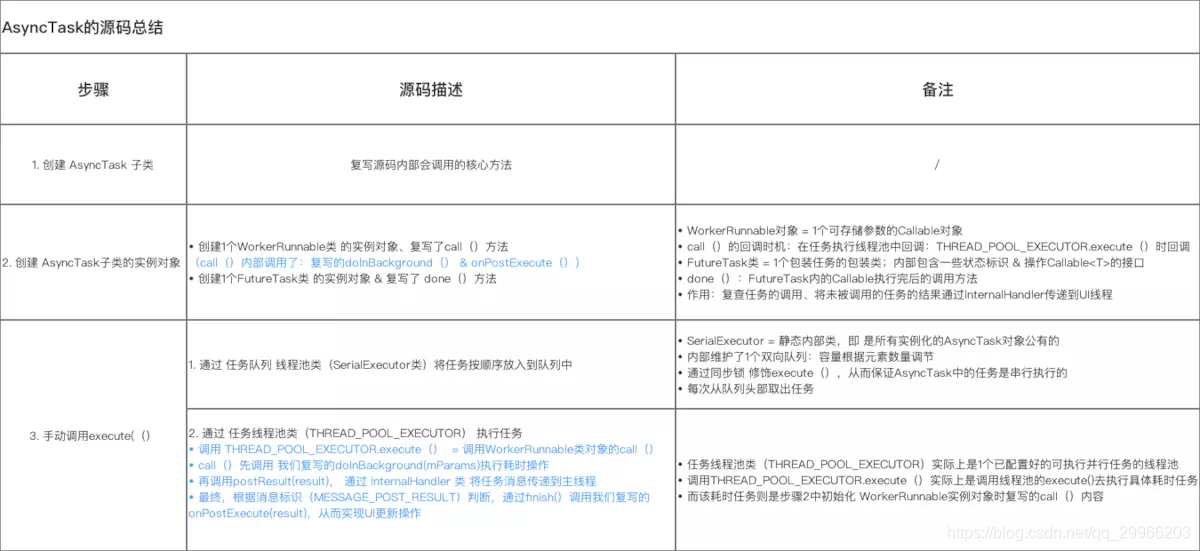
总结
- AsyncTask派生出的子类可以实现不同的异步任务,每个异步任务均提交到线程池中执行,且只能执行一次(执行多次会出现异常)
- 需要执行一个异步任务时,AsyncTask在主线程中调用execute方法。execute中会首先调用onPreExecute,因此这个方法在主线程中执行。
- 接着,AsyncTask从线程池中取处一个子线程执行doInBackground方法来执行异步的任务,因此这个方法在子线程中执行。
- 任务执行完成后,AsyncTask会获取结果后并通过Handler向主线程发送消息,AsyncTask内部的InternalHandler收到消息并调用onPostExecute,因此这个方法在主线程中执行。
不足之处 & 解决方法?
- 内存泄漏:
如果AsyncTask被声明为Activity的非静态的内部类,那么AsyncTask会保留一个对创建了AsyncTask的Activity的引用。如果Activity已经被销毁,AsyncTask的后台线程还在执行,它将继续在内存里保留这个引用,导致Activity无法被回收,引起内存泄露。
解决方法很简单,让内部持有外部的弱引用即可解决 - 生命周期
在Activity的onDestory()中及时对AsyncTask进行回收,调用其cancel()方法来保证程序的稳定性。 - 结果丢失
当屏幕旋转或内存不足时,当前的Activity被回收,如果此时AsyncTask被声明为Activity的非静态内部类,由于AsyncTask持有的是回收之前Activity的引用,导致AsyncTask更新的结果对象为一个无效的Activity的引用,这就是结果丢失。 - 并行或串行
在1.6(Donut)之前: 在第一版的AsyncTask,任务是串行调度。一个任务执行完成另一个才能执行。由于串行执行任务,使用多个AsyncTask可能会带来有些问题。所以这并不是一个很好的处理异步(尤其是需要将结果作用于UI试图)操作的方法。1.6-2.3: 所有的任务并发执行,这会导致一种情况,就是其中一条任务执行出问题了,会引起其他任务出现错误。3.0之后AsyncTask又修改为了顺序执行,并且新添加了一个函数 executeOnExecutor(Executor),如果您需要并行执行,则只需要调用该函数,并把参数设置为并行执行即可。
Handler
子线程一定不能更新UI吗?为什么Android系统不建议子线程访问UI?
[为什么不能在子线程中更新UI?][UI]
子线程可以更新UI(在系统还未检测当前更新UI的线程是否是UI线程之前执行操作)
谷歌提出:“UI更新一定要在UI线程里实现” 这一规则原因如下:
目的在于提高移动端更新UI的效率和和安全性,以此带来流畅的体验。原因是:
Android的UI访问是没有加锁的,多个线程可以同时访问更新操作同一个UI控件。也就是说访问UI的时候,android系统当中的控件都不是线程安全的,这将导致在多线程模式下,当多个线程共同访问更新操作同一个UI控件时容易发生不可控的错误,而这是致命的。
所以Android中规定只能在UI线程中访问UI,这相当于从另一个角度给Android的UI访问加上锁,一个伪锁。
定义 & 作用 & 六大概念
- 定义
一种Android消息传递/异步通信机制 - 作用
在多线程的应用场景中,将工作线程中需更新UI的操作信息 传递到 UI主线程,从而实现 工作线程对UI的更新处理,保证多线程并发更新UI时 线程安全,实现异步消息的处理。 - 六大概念
| 概念 | 定义 | 作用 | 说明 |
|---|---|---|---|
| 主线程/UI线程 Main Thread |
当一个程序启动时,就有一个进程被操作系统(OS)创建,与此同时一个线程也立刻运行,该线程通常叫做程序的主线程 | 用于处理UI相关的事件 | Android OS中,一个进程被创建之后,同时会自动开启一条主线程(当前Activity),主线程创建一个Looper和一个MessageQueue |
| 子线程/工作线程 Work Thread |
手动开启的线程 | 用于执行耗时操作,如网络请求、数据加载等 | |
| 消息 Message |
线程间通讯的数据单元(Handler 发送 & 响应的消息对象) | 存储子线程发送给UI线程的通信信息 | |
| 消息队列 Message Queue |
用来存放Message对象的数据结构 | 用来存放Handler发送过来的消息,不按照FIFO规则执行,而是将Message以单链表的方式串联起来的(适用于插入消息MessageQueue.enqueue和取出MessageQueue.next),等待Looper的抽取 维护所有顶层应用对象(Activities, Broadcast receivers等)以及主线程创建的窗口 |
MessageQueue对象不需要手动创建,而是由Looper对象对其进行管理,一个线程最多只可以拥有一个MessageQueue |
| 循环器 Looper |
MessageQueue的管理者 MessageQueue与Handler通信媒介 |
消息循环,包括 消息获取:循环取出消息队列MessageQueue中消息 消息分发:将取出的消息发送给对应的处理者Handler |
在一个线程中,如果存在Looper对象,则必定存在MessageQueue对象,并且只存在一个Looper对象和一个MessageQueue对象。在Android系统中,除了主线程有默认的Looper对象,其它线程默认是没有Looper对象。如果想让我们新创建的线程拥有Looper对象时,我们首先应调用Looper.prepare()方法,然后再调用Looper.loop()方法 |
| 处理者 Handler |
消息的处理者 主线程与子线程的通信媒介 |
Handler的作用是把消息加入特定(主线程)的消息队列中:Handler.sendMessage 处理Looper分发过来的消息:Handler.dispatchMessage |
MessageQueue,Handler和Looper三者之间的关系
一个线程Thread绑定一个循环器Looper和一个消息队列MessageQueue,对应多个处理者Handler。MessageQueue可以存放来自不同Handler发送的消息,Looper可以将消息分发给对应的Handler进行处理。
使用
步骤1:(自定义)新创建Handler子类(继承Handler类) & 复写handleMessage()方法
步骤2:在主线程中创建Handler实例
步骤3:创建工作线程(AsyncTask、Thread、Runnable)处理耗时操作,并创建需要发送的消息对象Message,并通过引用主线程的Handler发送
步骤4:开启工作线程
Handler使用方式 因发送消息到消息队列的方式不同而不同,共分为2种:使用Handler.sendMessage()、使用Handler.post()
- sendMessage(Message msg) 发送一个消息对象到消息队列
1 | public class MainActivity extends AppCompatActivity { |
- post(Runnable r) 将一个线程加入线程队列。
- post不需要外部创建消息对象,而是内部根据传入的Runnable对象封装消息对象并通过sendMessageDelayed(getPostMessege®)放入消息队列。并通过复写Runnable对象的run()通过回调处理消息。
- 本质上,post内部是使用sendMessage实现,他们本质上没有区别。post使用更为简单。
1 | public class MainActivity extends AppCompatActivity { |
Android 消息机制(工作原理 & 源码分析)
- 工作原理
Handler 机制的工作流程主要包括4个步骤:异步通信准备 → 消息发送 → 消息循环 → 消息处理
| 步骤 | 说明 | 备注 |
|---|---|---|
| 异步通信准备 | 在主线程中创建 循环器Looper 对象、消息队列MessageQueue 对象、Handler 对象 | 三者均位于主线程 当MessageQueue创建后,Looper自动进入消息循环 此时Handler 自动绑定了 Looper 和 MessageQueue |
| 消息发送 | 工作线程 通过Handler 发送消息Message 到消息队列MessageQueue中 | 消息内容一般是UI操作 发送消息通过Handler.sendMessage(Message msg)和Handler.post(Runnable r)发送 入队一般通过MessageQueue.enqueueMessage(Message)处理 |
| 消息循环 | 包括 消息出队 和 消息分发 两个步骤 消息出队:Looper循环取出消息队列MessageQueue中的消息Message 消息分发:Looper将取出的消息Message发送给创建消息的处理者Handler |
如果在消息循环的过程中,消息队列MessageQueue为空队列时,线程阻塞 |
| 消息处理 | 消息处理者Handler 接受 Looper 发送过来的消息Message,并根据Messge进行UI操作 |
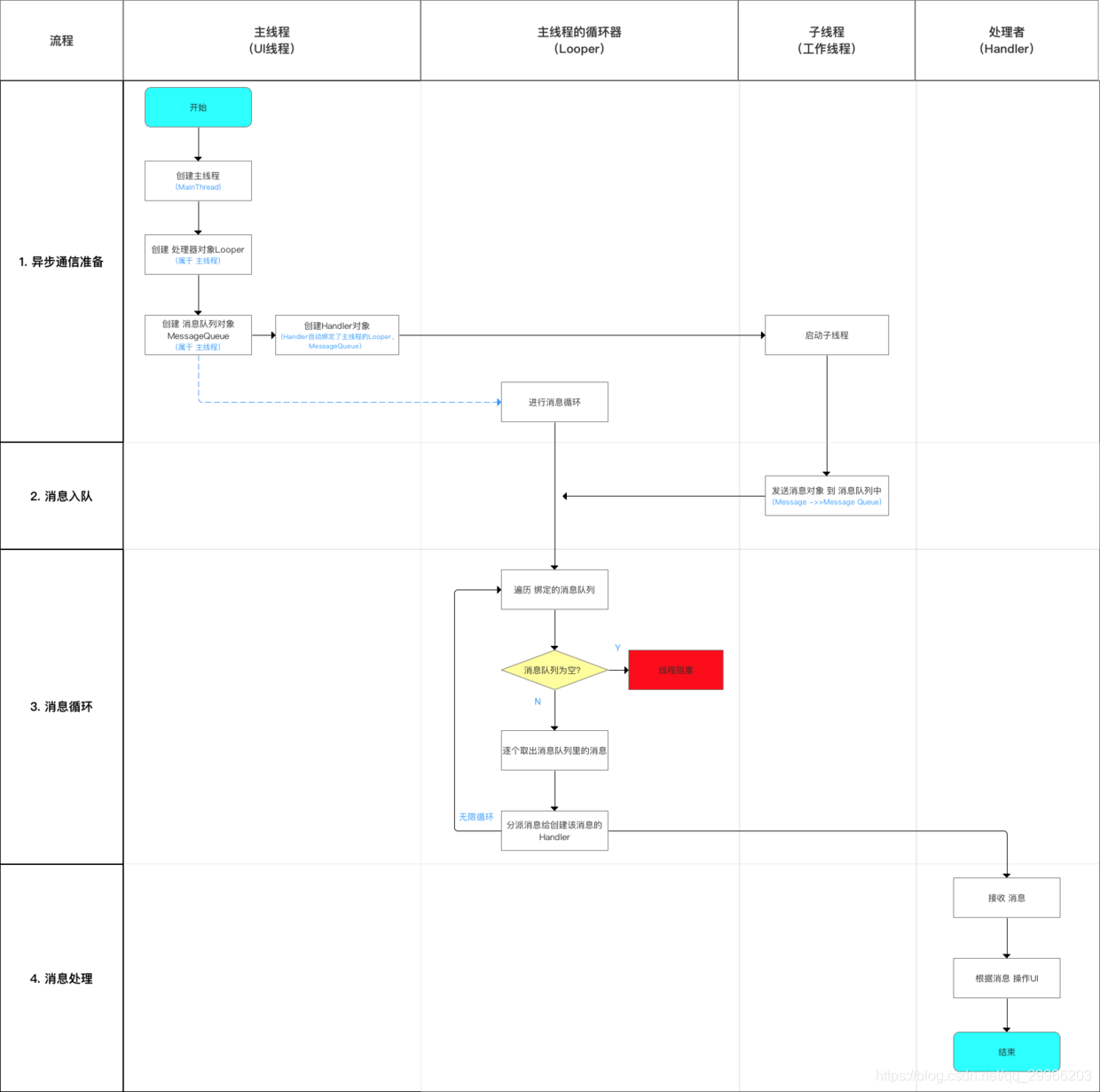
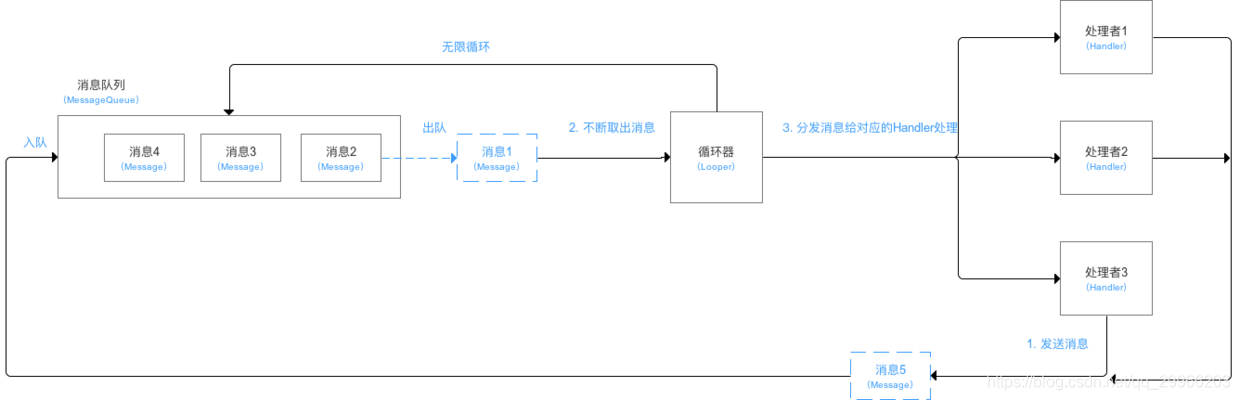
- 源码分析
[黑马:Handler源码分析][Handler 1]
[Carson_Ho:深入详解Handler机制源码][Carson_Ho_Handler]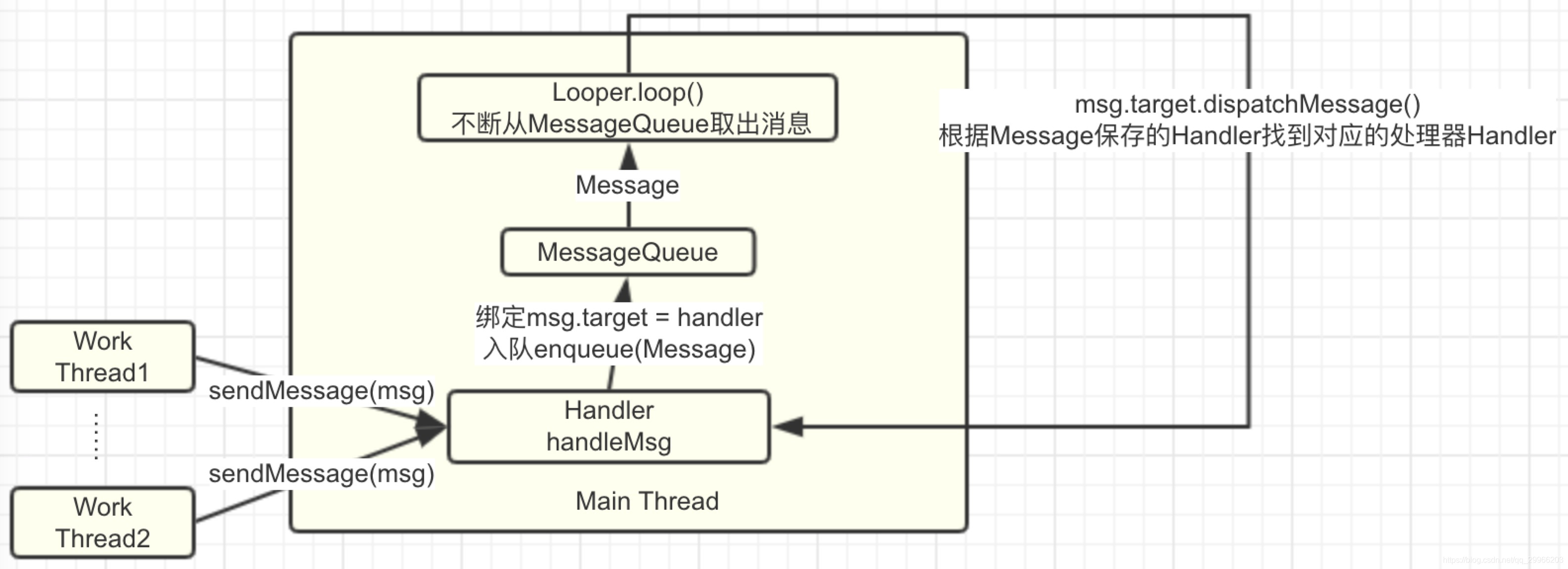
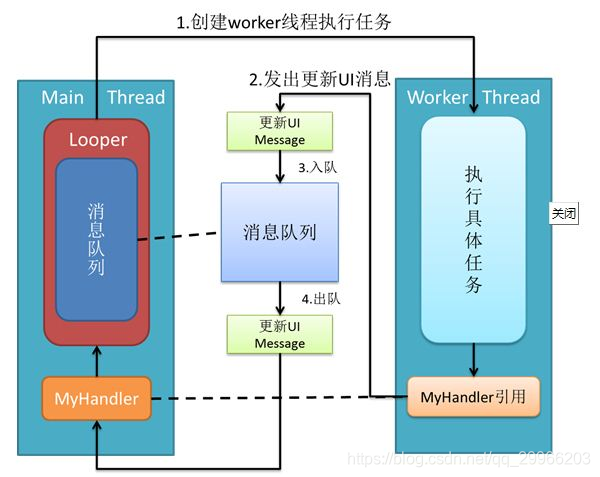
Handler.sendMessage(Message msg)
基本用法
1 | /** |
- 步骤1:在主线程中 通过匿名内部类 创建Handler类对象
- 当创建Handler对象时,则通过 构造方法 自动关联当前线程的Looper对象 & 对应的消息队列对象(MessageQueue),从而 自动绑定了 实现创建Handler对象操作的线程
- 实例化Handler对象需要复写handleMessage(Message msg)方法,对Looper分发的Message进行处理
1 | /** |
- 步骤1前隐式操作:创建循环器Looper & 循环队列MessageQueue 并进行 消息循环
- 创建循环器Looper & 循环队列MessageQueue
1 | /** |
- 创建主线程时,会自动调用ActivityThread的1个静态的main();而main()内则会调用Looper.prepareMainLooper()为主线程生成1个Looper对象,同时也会生成其对应的MessageQueue对象
- 生成Looper & MessageQueue对象后,则会自动进入消息循环:Looper.loop()
- 主线程的Looper对象自动生成,不需手动生成;而子线程的Looper对象则需手动通过Looper.prepare()创建
- 在子线程若不手动创建Looper对象 则无法生成Handler对象
- 根据Handler的作用(在主线程更新UI),故Handler实例的创建场景 主要在主线程
- 消息循环
1 | /** |
- 消息循环的操作 = 消息出队 + 分发给对应的Handler实例
- 分发给对应的Handler的过程:根据出队消息的归属者通过dispatchMessage(msg)进行分发,最终回调复写的handleMessage(Message msg),从而实现 消息处理 的操作
特别注意:在进行消息分发时(dispatchMessage(msg)),会进行1次发送方式的判断:
- 若msg.callback属性不为空,则代表使用了post(Runnable r)发送消息,则直接回调Runnable对象里复写的run()
- 若msg.callback属性为空,则代表使用了sendMessage(Message
msg)发送消息,则回调复写的handleMessage(msg)
- 步骤2:创建消息对象
- Message类内部维护一个Message池,用于消息对象复用
- 若消息池有可复用消息,则返回;否则return new Message()
1 | /** |
- 步骤3:在工作线程(AsynTask、Thread、Runnable)中 发送消息到消息队列中
- 将Handler实例保存到Message的target属性中(使Looper分发消息时能找到对应处理器)
- 将消息入队到绑定线程的消息队列中
1 | /** |
总结
| 步骤 | 核心方法 | 说明 |
|---|---|---|
| 主线程创建时 | Looper.prepare() Looper.loop() |
在ActivityThread.java主线程入口类,自动创建1个Looper,1个MessageQueue 并进入消息循环(不断从消息队列中取出消息Message并分发给相应的处理器msg.target.dispatchMessage(msg)) |
| 创建Handler实例 | Handler构造方法 Handler.handleMessage() |
绑定当前线程(Looper & MessageQueue) 复写回调方法对Looper分发的消息进行处理 |
| 创建消息对象 | Message.obtain() | 从Message池获取或新建Message对象 |
| 通过Handler发送消息到消息队列中 | Handler.sendMessage() | Message.target保存Handler信息 调用MessageQueue.enqueueMessage()将消息放入消息队列中 |
内存泄露 & 解决方案
- 内存泄露
当一个对象已经不再被使用时,本该被回收但却因为有另外一个正在使用的对象持有它的引用从而导致它不能被回收,仍停留在堆内存中。这就导致了内存泄漏。 - Handler内存泄露原因
(1)当Handler消息队列 还有未处理完的消息/正在处理的消息时,消息队列中的Message持有Handler实例的引用
(2)Handler = 非静态内部类/匿名内部类 ,故默认持有外部类(Activity实例)的引用
(3)该引用关系会一直保持,直到Handler消息队列中所有消息处理完毕(未被处理 / 正处理的消息 -> Handler实例 -> 外部类)
(4)在Handler消息队列 还有未处理的消息 / 正在处理消息时,此时若需销毁外部类MainActivity(Handler的生命周期 > 外部类的生命周期),但由于上述引用关系,垃圾回收器(GC)无法回收MainActivity,从而造成内存泄漏。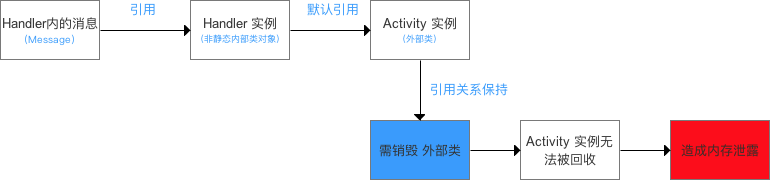
- Handler内存泄露解决
静态内部类 + 弱引用 - 将Handler的子类设置成 静态内部类
静态内部类 不默认持有外部类的引用,从而使得 “未被处理 / 正处理的消息 -> Handler实例 -> 外部类” 的引用关系 的引用关系 不复存在。 - 使用WeakReference弱引用持有Activity实例
弱引用的对象拥有短暂的生命周期。在垃圾回收器线程扫描时,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存
1 | public class MainActivity extends AppCompatActivity { |
面试
- [Looper死循环为什么不会导致应用卡死?][Looper]
- [使用Handler的postDealy后消息队列有什么变化?][Handler_postDealy]
- [可以在子线程直接new一个Handler出来吗?][new_Handler]
- [Message对象创建的方式有哪些 & 区别?][Message_ _]
HandlerThread
简介
一个Android 已封装好的轻量级异步通信类。
用于实现多线程(开启工作线程执行耗时操作),异步通信与消息传递(工作线程与主线程之间通信)
本质上是通过继承Thread类和封装Handler类的使用,从而使得创建新线程和与其他线程进行通信变得更加方便易用
具体使用
1 | // 步骤1:创建HandlerThread实例对象 |
工作原理 & 源码分析
内部原理 = Thread类 + Handler类机制,即:
- 通过继承Thread类,快速地创建1个带有Looper对象的新工作线程
- 通过封装Handler类,快速创建Handler & 与其他线程进行通信
- 创建HandlerThread实例对象
- HandlerThread类继承自Thread类
- 创建HandlerThread类对象 = 创建Thread类对象 + 设置线程优先级 = 新开1个工作线程 + 设置线程优先级
1 | /** |
- 启动线程
- 为当前工作线程(即步骤1创建的线程)创建1个Looper对象 & MessageQueue对象
- 通过持有锁机制来获得当前线程的Looper对象
- 发出通知:当前线程已经创建mLooper对象成功
- 工作线程进行消息循环,即不断从MessageQueue中取消息 & 派发消息
1 | /** |
- 创建工作线程Handler & 复写handleMessage()
将创建的Handler 与 工作线程的Looper对象绑定,从而将Handler绑定工作线程
1 | /** |
- 使用工作线程Handler向工作线程的消息队列发送消息
1 | /** |
- 结束线程,即停止线程的消息循环
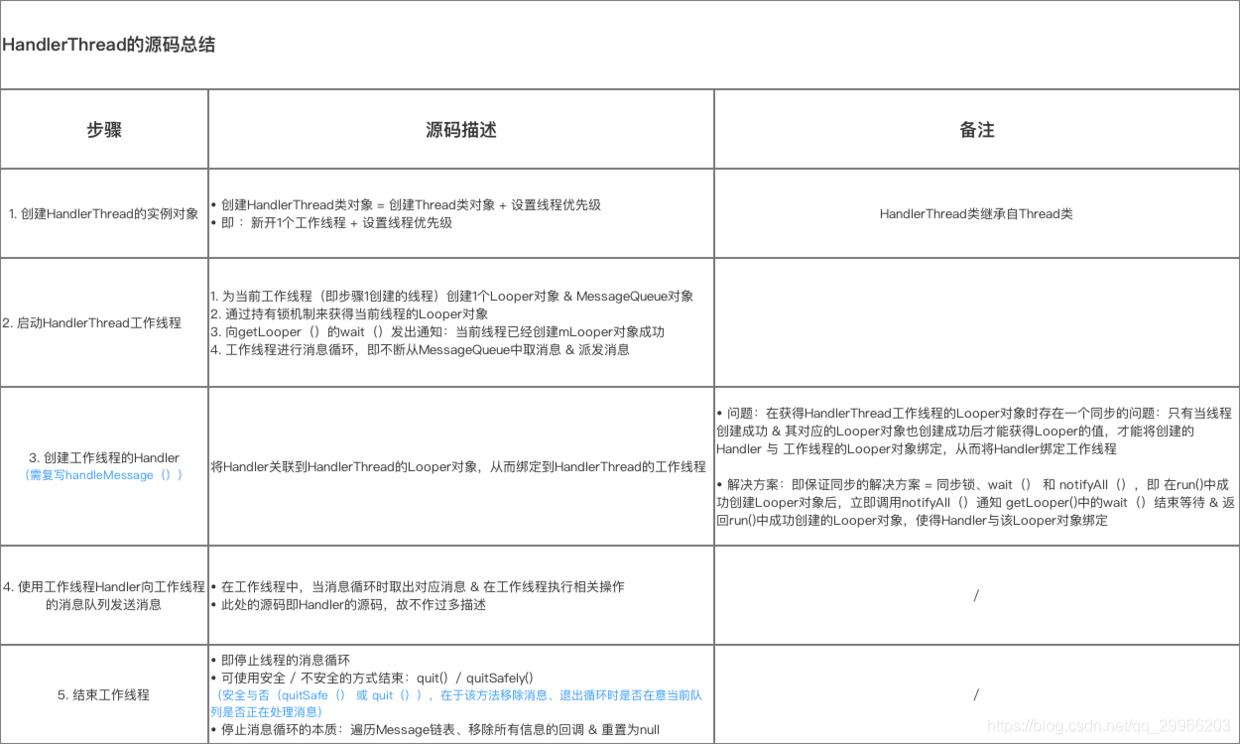
IPC
[带你了解android的IPC机制][android_IPC]
[Android 中的 IPC 方式][Android _ IPC]
[Android Binder机制及AIDL使用][Android Binder_AIDL]
IPC 概述?
- IPC简介
IPC是Inter-Process Communication的缩写,含义就是跨进程通信。
在Android中,为每一个应用程序都分配了一个独立的虚拟机,不同虚拟机在内存分配上都有不同的地址空间,进程间相互独立、隔离。因此互相访问数据需要借助其他手段。
IPC主要包含两部分:(1)序列化:将对象转化为字节(Serialiazable、Parcelable)(2)Binder机制 - 实现IPC的方式
| 方式 | 说明 | 特点 |
|---|---|---|
| Bundle | 在Android中三大组件(Activity,Service,Receiver)都支持在Intent中传递Bundle数据,由于Bundle实现了Parcelable接口(一种特有的序列化方法),所以它可以很方便的在不同的进程之间进行传输 | 四大组件间的进程间通信方式,简单易用,但只能是单方向的简单数据传输,使用有一定的局限性 |
| 文件共享 | 将对象序列化之后保存到文件中,在通过反序列,将对象从文件中读取出来。此方式对文件的格式没有具体的要求,可以是文件、XML、JSON等 | 文件共享方式也存在着很大的局限性,如并发读/写问题,如读取的数据不完整或者读取的数据不是最新的。不适合高并发场景,并且无法做到进程间的及时通信 |
| Messenger | 通过Messenger来进行进程间通信,在Messenger中放入我们需要传递的数据,实现进程间数据传递。Messenger只能传递Message对象,Messenger是一种轻量级的IPC方案,它的底层实现是AIDL | Messenger内部消息处理使用Handler实现的,所以它是以串行的方式处理客服端发送过来的消息的,如果有大量的消息发送给服务器端,服务器端只能一个一个处理,如果并发量大的话用Messenger就不合适了,而且Messenger的主要作用就是为了传递消息,很多时候我们需要跨进程调用服务器端的方法,这种需求Messenger就无法做到了。 |
| AIDL | 用于生成可以在Android设备上两个进程之间进行进程间通信(IPC)的代码 | 如果在一个进程中(例如Activity)要调用另一个进程中(例如Service)对象的操作,就可以使用AIDL生成可序列化的参数。AIDL是IPC的一个轻量级实现,Android也提供了一个工具,可以自动创建Stub(类架构,类骨架) |
| ContentProvider | ContentProvider(内容提供者)是Android中的四大组件之一,为了在应用程序之间进行数据交换,Android提供了ContentProvider,ContentProvider是不同应用之间进行数据交换的API,一旦某个应用程序通过ContentProvider暴露了自己的数据操作的接口,那么不管该应用程序是否启动,其他的应用程序都可以通过接口来操作接口内的数据,包括数据的增、删、改、查等操作 | 使用受限,只能根据特定规则访问数据 |
| Socket | Socket也是实现进程间通信的一种方式,Socket也称为“套接字”(网络通信中概念),通过Socket也可以实现跨进程通信,Socaket主要还是应用在网络通信中 |
Binder机制 简介 & 原理?
[carson_ho:Android跨进程通信:图文详解 Binder机制 原理][carson_ho_Android_ Binder_]
- Binder 简介
(1)Binder机制 是Android中实现跨进程通信(IPC)的方式
(2)Binder驱动 是连接Service进程、Client进程和Service Manager进程的一种虚拟的物理设备驱动
(3)Binder类 是一个实现了IBinder接口的类,常用用于代理模式中(AMS、AIDL) - Binder 机制
- 通信模型 & 工作原理
(1)进程隔离 & 跨进程通信模型 - 进程隔离
为了保证 安全性 & 独立性,一个进程 不能直接操作或者访问另一个进程,即Android的进程是相互独立、隔离的,只能运行在自己进程所拥有的虚拟地址空间。
对于用户空间,不同进程之间是不能共享的,而内核空间却是可共享的。Client进程向Server进程通信,恰恰是利用进程间可共享的内核内存空间来完成底层通信工作的。Client端与Server端进程往往采用ioctl等方法与内核空间的驱动进行交互。 - 跨进程通信(IPC)基本原理
(2)Binder 跨进程通信模型 & 工作原理
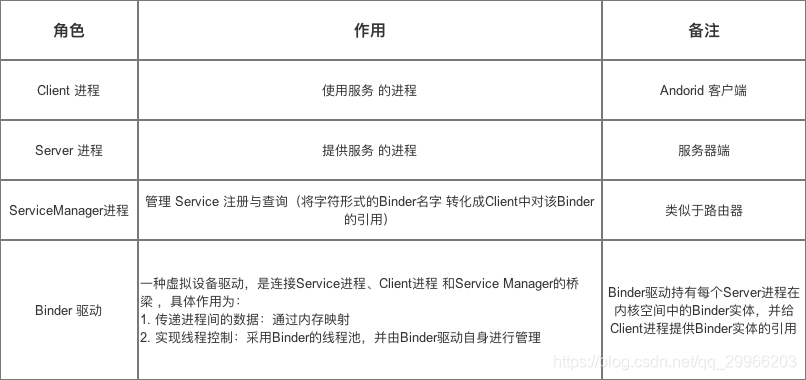
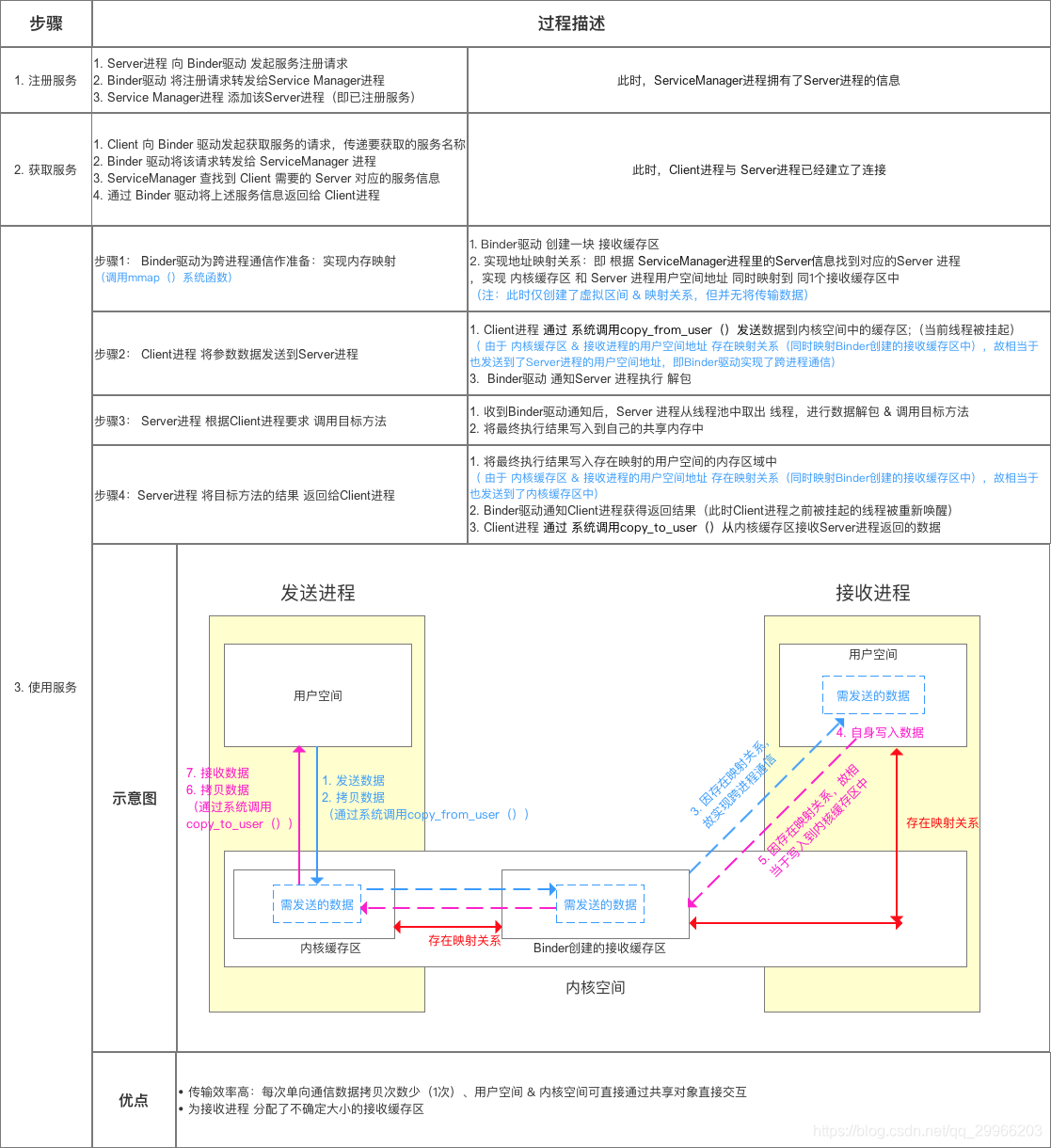
- Client进程、Server进程 & Service Manager 进程之间的交互 都必须通过Binder驱动(使用 open 和 ioctl文件操作函数),而非直接交互
Client进程、Server进程 & Service Manager进程属于进程空间的用户空间,不可进行进程间交互
Binder驱动 属于 进程空间的 内核空间,可进行进程间 & 进程内交互 - Binder驱动 & Service Manager进程 属于 Android基础架构(Android平台,由系统实现);而Client 进程 和 Server 进程 属于Android应用层(由开发者实现)
Binder 驱动创建一块接收缓存区。实现Service 进程用户空间 与 Client内核缓存区的地址映射。
因此用户通过系统调用(copy_from_user)发送数据到内核缓冲区时,也相当于发送到了Server进程的用户空间;
同理,Server将执行的结果写入共享的接受缓存区时,也相当于发送到了内核缓存区,用户通过系统调用(copy_to_user)从内核缓存区接受Server进程返回的数据。Binder只需要通过一次数据拷贝便可实现进程间的数据传递。
- 优点
- 对比 Linux (Android基于Linux)上的其他进程通信方式(管道、消息队列、共享内存、
信号量、Socket),Binder 机制的优点有: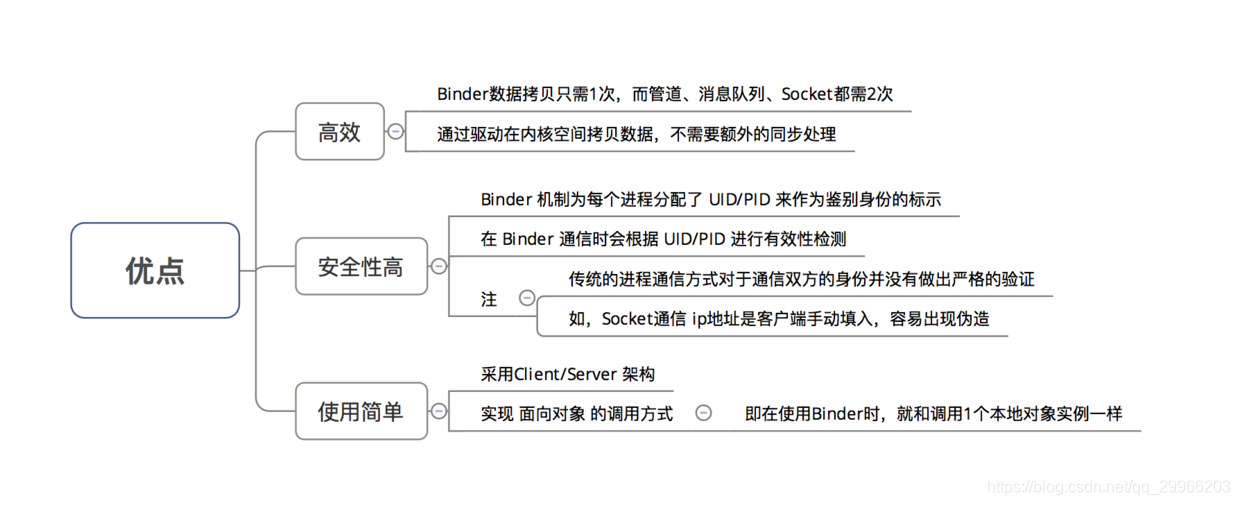
- Binder 跨进程调用服务流程
跨进程调用系统服务的简单示例,实现浮动窗口部分代码:
1 | //获取WindowManager服务引用 |
- 注册服务(addService): 在Android开机启动过程中,Android会初始化系统的各种Service,并将这些Service向ServiceManager注册(即让ServiceManager管理)。这一步是系统自动完成的。
- 获取服务(getService): 客户端想要得到具体的Service直接向ServiceManager要即可。客户端首先向ServiceManager查询得到具体的Service引用,通常是Service引用的代理对象,对数据进行一些处理操作。即第2行代码中,得到的wm是WindowManager对象的引用。
- 使用服务: 通过这个引用向具体的服务端发送请求,服务端执行完成后就返回。即第6行调用WindowManager的addView函数,将触发远程调用,调用的是运行在systemServer进程中的WindowManager的addView函数。
使用服务的具体执行过程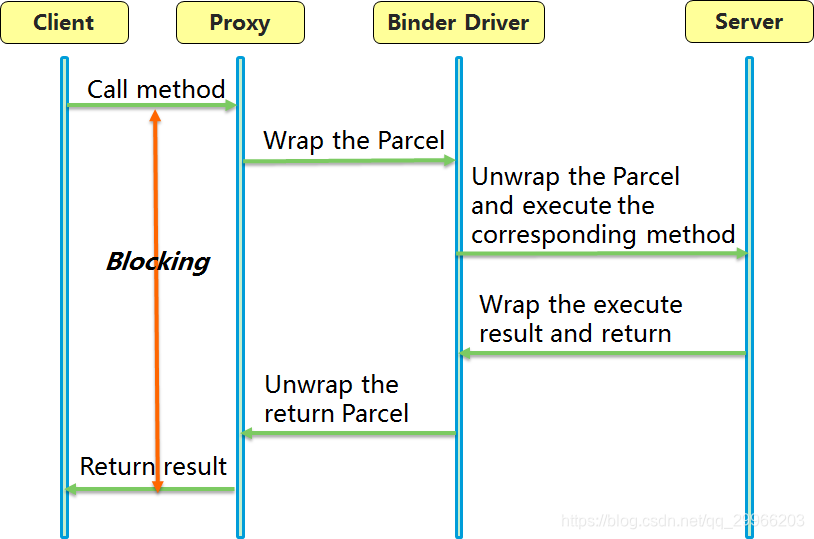
(1)Client通过获得一个Server的代理接口Proxy,对Server提供的方法进行调用。代理接口Proxy中定义的方法与Server中定义的方法是一一对应的。
(2)Client调用某个代理接口中的方法时,代理接口的方法会将Client传递的参数打包成Parcel对象。代理接口将Parcel发送给内核中的Binder Driver。
(BinderDriver底层工作:Client进程通过 系统调用 copy_from_user将数据发送到内核空间缓存区,由于 Client内核空间缓存区 & Server用户空间 存在地址映射关系,因此相当于发送到Server进程用户空间,Binder通知Server进行解包)
(3)Server会读取Binder Driver中的请求数据,解包Parcel对象,调用相应的方法并将结果打包返回给Binder Driver。
(Binder底层工作:Server将结果写入自己的用户空间,由于 Client内核空间缓存区 & Server用户空间 存在地址映射关系,因此相当于发送到内核缓存区,Binder通知Client获得结果,Client进程 通过 系统调用 copy_to_user() 从内核缓存区接收Server进程返回数据)
(4)Client的代理接口Proxy收到结果会解包并将真正的数据传送给Client。
整个的调用过程是一个同步过程,在Server处理的时候,Client会Block住。因此Client调用过程不应在主线程。 - 代理模式在Binder中的使用 / 从应用层面剖析Android Binder机制
[从应用层面剖析Android Binder机制][Android Binder]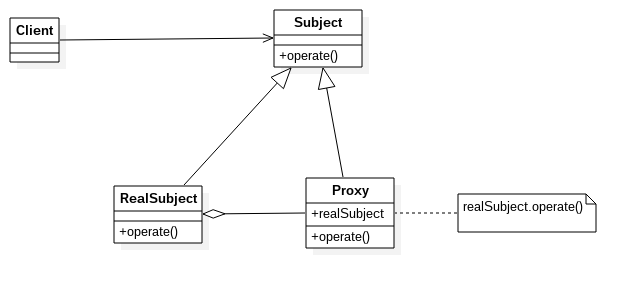
从Android应用层来说,Binder是客户端和服务端进行通信的媒介,当你bindService的时候,服务端会返回一个包含了服务端业务调用的Binder对象,通过这个Binder对象,客户端就可以获取服务端提供的服务或者数据,这里的服务包括普通服务和基于AIDL的服务。
(1)AIDL中代理模式
[人人都会设计模式:代理模式–Proxy][Proxy]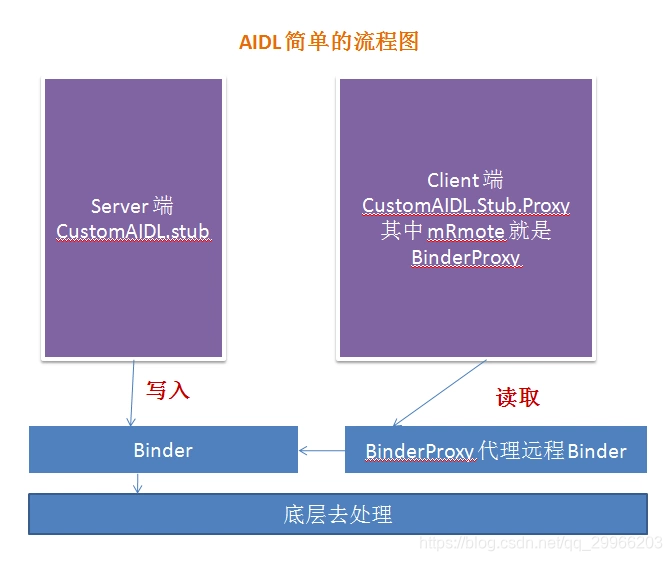
Binder实现中含有Proxy类。
Proxy将客户端的请求参数通过Parcel包装后通过Binder传到远程服务端,远程服务端解析数据并执行对应的操作,同时客户端线程挂起,当服务端方法执行完毕后,再将返回结果写入到另外一个Parcel中并将其通过Binder传回到客户端Proxy,客户端Proxy会解析但会数据包中的内容并将原始结果返回给客户端真正调用者,至此,整个Binder的工作过程就完成了。
由此可见,Binder是一个典型的代理者模式,Parcel对象就在这个通道中跨进程传输。
(2)AMS中代理模式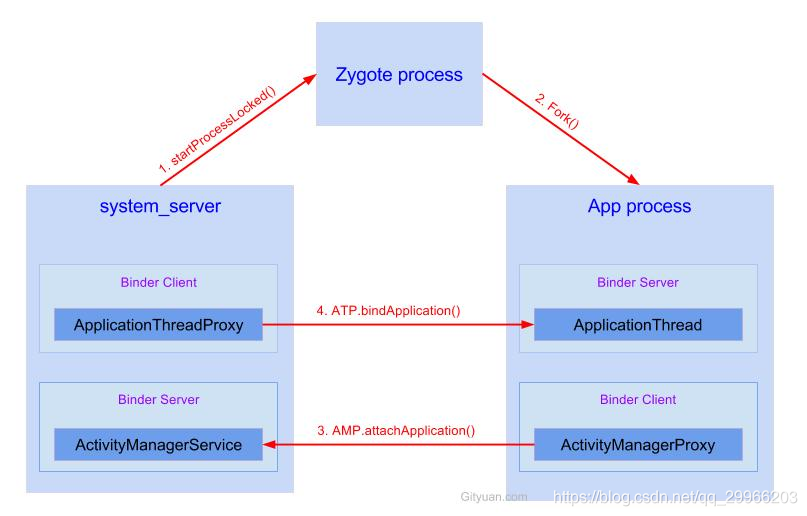
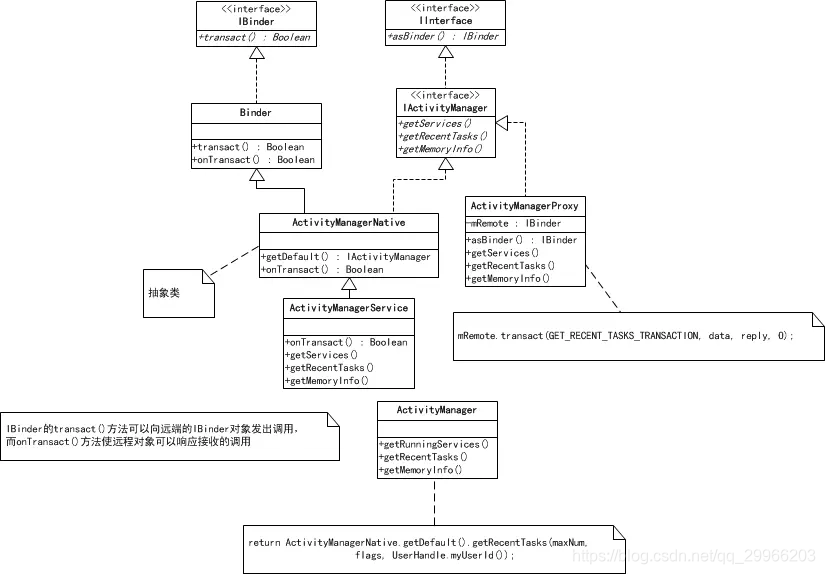
- IActivityManager作为ActivityManagerProxy和ActivityManagerNative的公共接口,所以两个类具有部分相同的接口,可以实现合理的代理模式;
- ActivityManagerProxy代理类是ActivityManagerNative的内部类;
- ActivityManagerNative是个抽象类,真正发挥作用的是它的子类ActivityManagerService(系统Service组件)。
- ActivityManager是一个客户端,为了隔离它与,有效降低甚至消除二者的耦合度,在这中间使用了ActivityManagerProxy代理类,所有对的访问都转换成对代理类的访问,这样ActivityManager就与解耦了,这是典型的proxy的应用场景。
- ActivityManagerService是系统统一的Service,运行在独立的进程中;通过系统ServiceManger获取;ActivityManager运行在一个进程里面,ActivityManagerService运行在另一个进程内,对象在不同的进程里面,其地址是相互独立的;采用Binder机制跨进程通信,所以我们可以得出这是一个RemoteProxy。
(3)activity.bindService()
什么是AIDL?如何使用AIDL?AIDL工作原理(结合Binder)?
- AIDL定义
AIDL (Android Interface Definition Language) 是一种接口定义语言,用于生成可以在Android设备上两个进程之间进行进程间通信(Interprocess Communication, IPC)的代码。如果在一个进程中(例如Activity)要调用另一个进程中(例如Service)对象的操作,就可以使用AIDL生成可序列化的参数,来完成进程间通信。 - AIDL使用
AIDL一共分为三部分,分别是客户端、服务端和AIDL接口。
- AIDL接口:用来传递的参数,提供进程间通信。
(1)创建.aidl文件,即接口IService(IService.aidl),用于提供暴露的方法(传递的参数)
IService.aidl
1 | interface IService { |
Make Project后,系统会自动生成IService.java文件(位于gen/package目录下)
该接口会自动生成Stub类,继承了Binder 类,同时实现了IService接口。Stub是AIDL自动生成一个实现AIDL接口的专门用于进程间通信的中间人(IBinder)类。
1 | public interface IService extends android.os.IInterface{ |
(2)服务端需要创建一个中间人实现IService接口,从而提供的服务方法;客户端需要获取IService接口从而得到中间人并调用服务方法。因此需要保证服务端客户端拥有同一个AIDL文件。AIDL规定拥有相同包名的AIDL文件为同一个ADIL文件。
在服务端和客户端下创建相同的包名,放入相同的IService.aidl,并由AIDL(系统)自动生成相同的IService.java文件(可序列化参数)
- 服务端/远程进程:运行在其他应用中的服务,用于提供服务。
(1)编写服务端代码,定义一个中间人对象,并实现接口(extends Binder implements IService = extends Stub)。并在onBinder中返回中间人
1 | public class RemoteService extends Service{ |
(2)AndroidManifest.xml 配置服务
1 | <service android:name="com.itheima.remoteservice.RemoteService"> |
总结:服务端创建一个 Service 用来监听客户端的连接请求,然后创建一个 AIDL 文件,将暴露给客户端的接口在这个 AIDL 文件中声明,最后在 Service 中实现这个 AIDL 接口即可。
- 客户端/本地进程:运行在自己应用的服务,用于调用远程服务
(1)在MainActivity中通过asInterface方法获取中间人对象,并执行服务端方法
1 | public class MainActivity extends Activity{ |
总结:绑定服务端的 Service ,绑定成功后,将服务端返回的 Binder 对象转成 AIDL 接口所属的类型,然后就可以调用 AIDL 中的方法了。
- AIDL应用场景
某个游戏(如欢乐斗地主)需要支付时打开支付宝应用进行支付 - AIDL文件解析(手写aidl)
.aidl文件用于向客户端暴露远程服务提供方法,用于跨进程通信。经过JVM编译后生成对应java文件,生成一个继承IInterface类的接口。
包含2部分: - 实现IBookService的本地实现类Stub
- 暴露给客户端的服务方法
1 | public interface IBookService extends IInterface { |
实现IBookService的本地实现类Stub,包含1个构造函数,2个重要方法,一个代理内部类
- 构造函数 public Stub() {}
- asInterface
- onTransact
- Stub 内部类 Proxy
1 | public abstract class Stub extends Binder implements IBookService { |
实现IBookService的代理类Proxy
Proxy是一个典型的静态代理模式,Proxy并没有实现IBookService中的方法,而是通过remote将方法请求传递到Server进程,也即是上面的Stub类处理,而remote是一个BinderProxy,包含2部分:
- 构造方法 public Proxy(IBinder remote) {}
- 接口方法的实现
1 | public class Proxy implements IBookService { |
- AIDL工作原理
Binder机制运行主要包括三部分:注册服务、获取服务和使用服务。注册服务和获取服务主要涉及C的内容,不予介绍。主要介绍使用服务时AIDL工作原理。
.aidl文件生成的java代码是一个接口文件,继承了android.os.IInterface,用于声明暴露给Client端的具体服务。这个接口生成的java文件包括两部分: - 静态内部抽象类Stub
- 声明了具体的功能的抽象方法(aidl文件中声明的方法)
(1)Binder对象的获取
Binder是实现跨进程通信的基础,那么Binder对象在服务端和客户端是共享的,是同一个Binder对象。在客户端通过Binder对象获取实现了IInterface接口的对象来调用远程服务,然后通过Binder来实现参数传递。 - 服务端获取Binder对象并保存IInterface接口对象
服务端创建binder实现Stub类并实现AIDL抽象函数
1 | private IBookManager.Stub mbinder = new IBookManager.Stub() { |
Binder中两个关键方法:
1 | // Binder具有被跨进程传输的能力是因为它实现了IBinder接口。系统会为每个实现了该接口的对象提供跨进程传输 |
在服务端进程,通过实现private IBookManager.Stub mbinder = new IBookManager.Stub() {}抽象类,获得Binder对象。 并保存了IInterface对象。
1 | public Stub() { |
- 客户端获取Binder对象并获取IInterface接口对象
通过bindService获得Binder对象
1 | MyClient.this.bindService(intentService, mServiceConnection, BIND_AUTO_CREATE); |
然后通过Binder对象获得IInterface对象。
1 | private ServiceConnection mServiceConnection = new ServiceConnection() { |
其中asInterface(binder)方法如下:
1 | public static com.lvr.aidldemo.IBookManager asInterface(android.os.IBinder obj) { |
先通过queryLocalInterface(DESCRIPTOR);查找到对应的IInterface对象,然后判断对象的类型,如果是同一个进程调用则返回IBookManager对象,由于是跨进程调用则返回Proxy对象,即Binder类的代理对象。
(2)客户端调用服务端方法
实现IBookService的代理类Proxy,Proxy是一个典型的静态代理模式,Proxy并没有实现IBookService中的方法,而是通过remote将方法请求传递到Server进程,交给Stub类处理。
1 | public class Proxy implements IBookService { |
客户端获得了Binder类的代理对象Proxy,并且通过代理对象获得了IInterface对象,那么就可以调用接口的具体实现方法了,来实现调用服务端方法的目的。
以addBook方法为例,调用该方法后,客户端线程挂起,等待唤醒:
1 | public void addBook(com.lvr.aidldemo.Book book) throws android.os.RemoteException |
省略部分主要完成对添加的Book对象进行序列化工作,然后调用transact方法。
Proxy对象中的transact调用发生后,会引起系统的注意,系统意识到Proxy对象想找它的真身Binder对象(系统其实一直存着Binder和Proxy的对应关系)。于是系统将这个请求中的数据转发给Binder对象,Binder对象将会在onTransact中收到Proxy对象传来的数据,于是它从data中取出客户端进程传来的数据,又根据第一个参数确定想让它执行添加书本操作,于是它就执行了服务端相应操作,并把结果写回reply。代码概略如下:
1 | case TRANSACTION_addBook: { |
然后在transact方法获得_reply并返回结果,本例中的addList方法没有返回值。
客户端线程被唤醒。因此调用服务端方法时,应开启子线程,防止UI线程堵塞,导致ANR。
因此对于Binder跨进程通信过程,可以总结为:
- 创建IService.aidl文件,声明暴露给Client的方法。系统将自动创建对应IService.java继承IInterface,包含Stub类和一系列暴露的抽象方法。作为跨进程通信的接口。
Stub类:继承Binder,实现IService接口。Server通过创建Stub实例,实现接口中定义的方法,处理Client的调用请求。包含一个构造函数、两个重要的方法和一个代理类:
- public Stub():创建Stub实例,在Binder中保存IInterface对象,服务端获取Binder
- public static IService asInterface(IBinder binder):根据key值查找相应的IInterface对象,客户端获取Binder
- protected boolean onTranscat(int code, @NonNull Parcel data, @Nullable Parcel reply, int flags):进程间通信的方法,Client调用Proxy对象的transact后,会将数据传给Server的onTransact,执行Client想要执行的方法
抽象方法:IService中声明的暴露给Client的方法
- Server进程端创建Stub实例,实现接口方法,使之可以处理Client进程端的调用请求;
- Client进程端持有BinderProxy,当要调用IService中的方法时,实际上通过BinderProxy.transact()方法调用,经过Binder驱动跨进程传递之后,最终找到Server端onTransact()执行;
- Server的onTransact收到Client传来的数据后,根据code来执行Client调用的方法。
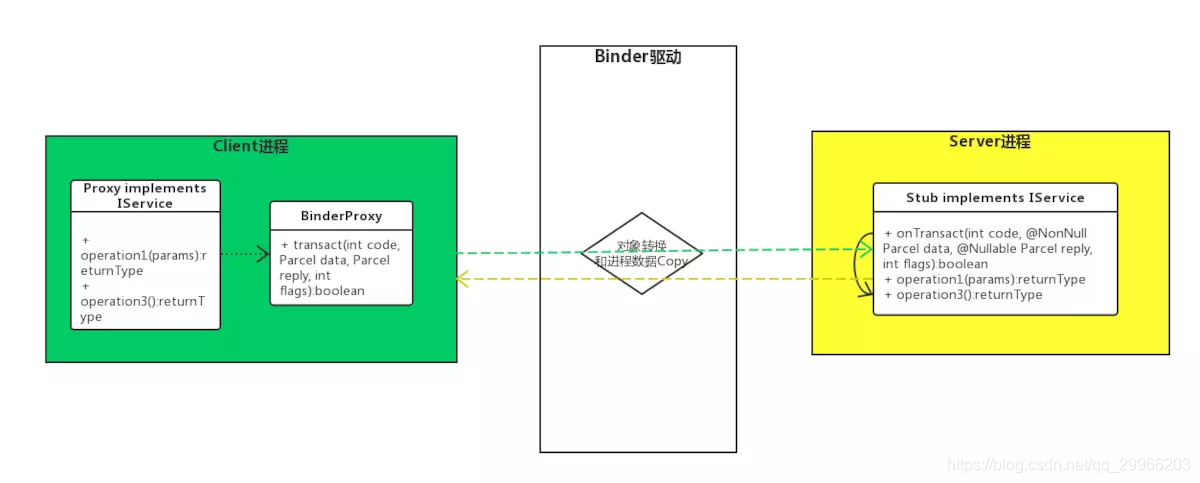
第十一章 WebView
- WebView
- Hybird 开发
- WebView 是什么 & 作用 & 内核
- WebView 基本使用
- WebSettings & WebViewClient & WebChromeClient
- 使用案例
- WebView 与 JS 交互方式
- WebView 导致内存泄露 原因 & 解决
- WebView 优化方案 & 框架
- 前端H5的缓存机制(WebView 缓存机制)
- 资源预加载
- 自身构建缓存
- Hybird 框架
WebView
Hybird 开发
Hybrid App(混合模式移动应用)是指介于web-app、native-app这两者之间的app,兼具“Native App良好用户交互体验的优势”和“Web App跨平台开发的优势”。
hybrid开发其实就是在App开发过程中既使用到了web(H5)开发技术也使用到了native开发技术,通过这两种技术混合实现的App就是我们通常说的hybrid app,而通过这两种技术混合开发就是hybrid开发。
- 为何需要hybird开发
- 使用Native开发的方式人员要求高,只是一个简单的功能就需要IOS程序员和Android程序员各自完成;
- 使用Native开发的方式版本迭代周期慢,每次完成版本升级之后都需要上传到App Store并审核,升级,重新安装等,升级成本高;
- 使用hybrid开发的方式简单方便,同一套代码既可以在IOS平台使用,也可以在Android平台使用,提高了开发效率与代码的可维护性;
- 使用hybrid开发的方式升级简单方便,只需要服务器端升级一下就好了,对用户而言完全是透明了,免去了Native升级中的种种不便;
通过对比可以发现hybrid开发方式现对于native实现主要的优势就是更新版本快,代码维护方便,当然了这两个优点也是我们推崇使用hybrid开发app的主要因素。
- Android中如何实现Bybird开发
有两种方案:
- 使用第三方hybrid框架(集成度高,不容易定制化处理)
- 自己使用webview加载(定制化程度高,问题可控,但是相对与第三方框架集成度不够高)
WebView 是什么 & 作用 & 内核
- 简介
WebView是一个基于webkit引擎、展现web页面的控件。
Android的Webview在低版本和高版本采用了不同的webkit版本内核,4.4后直接使用了Chrome。
- 显示和渲染Web页面
- 直接加载url
- 直接使用html文件(网络上或本地assets中)作布局
- 使用JavaScript交互调用H5和Native
WebView 基本使用
前提:添加网络权限
1 | <uses-permission android:name="android.permission.INTERNET"/> |
WebSettings & WebViewClient & WebChromeClient
- WebSetting
对WebView进行配置和管理
1 | WebView webView = new WebView(this) |
常用:设置WebView缓存
当加载 html 页面时,WebView会在/data/data/包名目录下生成 database 与 cache 两个文件夹
请求的 URL记录保存在 WebViewCache.db,而 URL的内容是保存在 WebViewCache 文件夹下
1 | //优先使用缓存: |
- WebViewClient
处理各种通知 & 请求事件
1 | Webview webview = (WebView) findViewById(R.id.webView1); |
- WebChromeClient
辅助 WebView 处理 Javascript 的对话框,网站图标,网站标题等等。
1 | webview.setWebChromeClient(new WebChromeClient(){ |
使用案例
(1)需求
实现显示“www.baidu.com”、获取其标题、提示加载开始 & 结束和获取加载进度
(2)实现
步骤1:添加访问网络权限
AndroidManifest.xml
1 | <uses-permission android:name="android.permission.INTERNET"/> |
步骤2:主布局
activity_main.xml
1 | <?xml version="1.0" encoding="utf-8"?> |
步骤3:实现显示“www.baidu.com”、获取其标题、提示加载开始 & 结束和获取加载进度
1 | public class MainActivity extends AppCompatActivity { |
WebView 与 JS 交互方式
- Android 调用 JS 方法
通过WebView的loadUrl - Web端
1 | <!DOCTYPE html> |
- Android端
1 | public class HybirdTestctivity extends AppCompatActivity { |
- JS 调用 Android 方法
使用@addJavascriptInterface 注入 java 对象来实现 - 创建要注入的Java类
1 | // 创建注入的Java类 |
- Android端
1 | // 设置与Js交互的权限 |
- Web端
1 | <!DOCTYPE html> |
- JS 消息回调拦截
- 通过 WebViewClient 的方法shouldOverrideUrlLoading ()回调拦截 url
(1)在JS约定所需要的Url协议
1 | <!DOCTYPE html> |
(2)在Android通过WebViewClient复写shouldOverrideUrlLoading ()
1 | // 复写WebViewClient类的shouldOverrideUrlLoading方法 |
- 通过 WebChromeClient 的onJsAlert()、onJsConfirm()、onJsPrompt()方法回调拦截JS对话框alert()、confirm()、prompt() 消息
(1)Web端调用prompt() 调用JS输入框
1 | <!DOCTYPE html> |
(2)在Android通过WebChromeClient复写onJsPrompt()
1 | mWebView.setWebChromeClient(new WebChromeClient() { |
WebView 导致内存泄露 原因 & 解决
不再使用WebView对象后不销毁,导致占用的内存长期无法回收,从而造成内存泄露。
WebView关联Activity的时候会自动创建线程,绑定了Activity Context。而Activity无法确定这个线程的销毁时间,这个线程的生命周期和我们Activity生命周期是不一样的,这就导致了Activity销毁时,WebView还持有Activity的引用,从而出现内存泄漏问题。
WebView与Activity Context绑定。销毁WebView的时候,需要释放Activity的Context,否则会内存泄露。
- 在 Activity 销毁( WebView )的时候,先让 WebView 加载null内容,然后移除 WebView,再销毁 WebView,最后置空。
1 |
|
- 不在xml中定义 WebView ,而是在需要的时候在Activity中创建,并且Context使用 getApplicationContext()
1 | LinearLayout.LayoutParams params = new LinearLayout.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT); |
- 开启独立进程加载WebView页面,页面关闭后关闭进程
WebView 优化方案 & 框架
WebView 性能问题
- Android WebView 里 H5 页面加载速度慢
(1)渲染速度慢:JS解析效率低、手机硬件设备性能低
(2)资源加载慢:H5页面资源多、网络请求数量多 - 耗费流量
(1)每次使用时需要重新加载Android WebView H5页面
(2)发送大量网络请求
上述问题导致了Android WebView的H5 页面体验 与 原生Native 存在较大差距。
前端H5的缓存机制(WebView 缓存机制)
- 浏览器 缓存机制
根据 HTTP 协议头里的 Cache-Control(或 Expires)和 Last-Modified(或 Etag)等字段来控制文件缓存的机制
Android WebView内置自动实现,即不需要设置即实现(属于浏览器内核机制),用于存储静态资源文件,如JS、CSS、字体、图片等。 - Application Cache 缓存机制
以文件为单位进行缓存,且文件有一定更新机制(类似于浏览器缓存机制,是浏览器缓存的补充),是专门为 Web App离线使用而开发的缓存机制
用于存储静态文件(如JS、CSS、字体文件) - Dom Storage 缓存机制
通过存储字符串的 Key - Value 对来提供,存储控件大、安全、便捷(Dom Storage 机制类似于 Android 的 SharedPreference机制)
用于存储临时、简单的数据。 - Web SQL Database 缓存机制
基于 SQL 的数据库存储机制,充分利用数据库的优势,可方便对数据进行增加、删除、修改、查询。存储适合数据库的结构化数据。 - Indexed Database 缓存机制
属于 NoSQL 数据库,通过存储字符串的 Key - Value 对来提供(取代Web SQL Database 缓存机制)。通过数据库的事务机制进行数据操作,可对对象任何属性生成索引,方便查询。存储控件大。可存储任何类型对象。
适用于存储复杂、数据量大的结构化数据。
资源预加载
包括 WebView对象 & H5资源 预加载
- 原因
首次创建WebView对象耗时
首次加载H5页面耗时(后续打开H5页面时便有缓存) - 具体实现
- 在Android的 BaseApplication 里初始化一个WebView对象(用于加载常用的H5页面资源);当需要使用这些页面时,直接从BaseApplication中使用该WebView对象显示、
自身构建缓存
- 原因
H5页面有一些更新频率低、常用 & 固定的静态资源文件(如JS、CSS文件、图片等)。每次重新加载会浪费很多时间、流量。 - 解决方案
- 事先将更新频率较低、常用 & 固定的H5静态资源 文件(如JS、CSS文件、图片等) 放到本地
- 拦截H5页面的资源网络请求 并进行检测
- 如果检测到本地具有相同的静态资源 就 直接从本地读取进行替换 而 不发送该资源的网络请求 到 服务器获取
- 具体实现
重写WebViewClient 的 shouldInterceptRequest 方法,当向服务器访问这些静态资源时进行拦截,检测到是相同的资源则用本地资源代替
1 | // 假设现在需要拦截一个图片的资源并用本地资源进行替代 |
Hybird 框架
[腾讯祭出大招VasSonic,让你的H5页面首屏秒开][VasSonic_H5]
优化方案:
- 启动流程彻底拆分,设计为一个状态机按序按需执行
- View相关拆分模块化设计,尽可能懒加载,IO异步化
- X5内核在手Q中的独立进程中提前预加载
- 创建WebView对象复用池
- 静态直出
- 离线预推:把页面的资源提前拉取到本地,当用户加载资源的时候,相当于从本地加载,即使没有网络,也能展示首屏页面。这个也就是大家熟悉的离线包。(在弱网络或者网速比较差的环境下加载资源耗时耗资源)
- 并行加载
- 动态缓存(将用户的已经加载的页面内容缓存下来,等用户下此点击页面的时候,我们先加载展示页面缓存,第一时间让用户看到内容,然后同时去请求新的页面数据,等新的页面数据拉取下来之后,我们再重新加载一遍即可。)
- 页面分离
- 请求规范约定
- 首次加载 & 非首次加载之 完全缓存/增量数据/模块更新
第十二章 Android第三方库源码
- EventBus
- EventBus理解
- EventBus源码分析
- EventBus项目实战
- okHttp
- 简介
- 使用
- 工作原理
- 源码解读
- 总结
- 设计模式
- 封装
- 网络框架对比
- Glide
- 简介
- 使用
- 工作原理(非重点)
- 图片加载框架对比
EventBus
[https://github.com/greenrobot/EventBus][https_github.com_greenrobot_EventBus]
EventBus理解
[EventBus原理解析笔记以及案例实战(结合demo)][EventBus_demo]
- 什么是 EventBus
EventBus(事件总线)是一个Android端优化的 发布/订阅 消息总线。简化了应用程序内各个组件、组件与后台线程间(活动Activity、碎片Fragment、进程Thread、服务Service等)的通信方式;
使用 发布/订阅 机制对代码进行解耦,移除了不必要的依赖,使APP项目用更少的代码量实现更好的质量;
优点:
(1)简化应用程序内各个组件、组件与后台线程间通讯方式
(2)分离事件发布者和订阅者,实现完全解耦
(3)移除不必要的依赖关系(避免易错的生命周期问题)
(4)可继承、优先级、粘滞性
(5)代码更简洁、性能更好、移动应用更快、更小
缺点:
(1)EventBus中的事件分发是通过事件类名(订阅方法的参数类型)决定的,这就导致了当接受者过多或相同参数时很难理清消息流。
(2)EventBus中发布者(publisher)只能单向广播,无法获得订阅者(subscriber)对事件处理的相应 - EventBus 三个角色
- Event:事件。可以是任意类型,EventBus根据事件类型进行全局通知。
- Subscriber:事件订阅者。事件方法名任意取名,需要加上注解@subscribe,并指定线程模型。
EventBus 3.0 有四种线程模型(订阅者 & 发布者可位于任意线程),分别是:
- POSTING:默认,表示事件处理函数的线程跟发布事件的线程在同一个线程。
- MAIN:表示事件处理函数的线程在主线程(UI)线程,因此在这里不能进行耗时操作。若当前线程不是主线程,则通过Handler将消息发送给主线程。
- BACKGROUND:表示事件处理函数的线程在后台线程,因此不能进行UI操作。如果发布事件的线程是主线程(UI线程),那么事件处理函数将会开启一个后台线程,如果果发布事件的线程是在后台线程,那么事件处理函数就使用该线程。
- ASYNC:表示无论事件发布的线程是哪一个,事件处理函数始终会新建一个子线程运行,同样不能进行UI操作。
- Publisher:事件发布者。可在任意线程里发布事件
- EventBus 的使用
(1)引入依赖
1 | implementation 'org.greenrobot:eventbus:3.1.1' |
(2)定义事件
定义一个事件的封装对象。在程序内部就使用该对象作为通信的信息
1 | public class MyEvent { |
(3)定义订阅者,注册事件 & 处理事件
1 | public class MainActivity extends AppCompatActivity { |
(4)定义发布者,发布事件
1 | public class SecondActivity extends AppCompatActivity { |
- EventBus & BroadcastReceiver & Handler
EventBus、BroadcastReceiver和Handler均是Android中进程间消息传递的方式
| EventBus | BroadcastReceiver | Handler | |
|---|---|---|---|
| 定义 | EventBus是一个Android端优化的publish/subscribe消息总线 | Android四大组件之一,广播,全局监听器 | Handler运行在主线程中,通过Message与子线程进行数据传递,解决子线程无法更新UI问题 |
| 范围 | 应用内组件间、线程间通信 | 同一app内部的同一组件内的消息通信(单个或多个线程之间); 同一app内部的不同组件之间的消息通信(单个进程); 同一app具有多个进程的不同组件之间的消息通信; 不同app之间的组件之间消息通信 |
同一进程中不同线程间通信(主要是UI线程 & 子线程) |
| 消息 | 事件,可以是任意类型对象 | intent | Message类型 |
| 适用场景 | 应用内的消息事件广播 | 系统内全局性的消息传递,尤其包括: 1. 系统事件监听(电量、网络等) 2. 多进程通信 |
UI线程 与 子线程 之间消息传递 |
| 优点 | 1. 订阅者和发布者耦合度低,调度灵活,不依赖Context 2. 可继承、优先级、粘滞性 3. 轻量 |
1. 四大组件之一,与sdk链接紧密,监听系统广播 2. 跨进程通信 |
适用于目标具体明确的调度,处理简单的耗时操作 |
| 缺点 | EventBus中的事件分发是通过注解函数的参数类型决定的,这就导致了当接受者过多或相同参数时很难理清消息流 | 1. 资源占用多,依赖Context 2. 同一进程不同线程消息传递回调函数复杂(适用EventBus/Observer) | 消息高度绑定,发布者与接受者高度耦合,代码冗余 |
EventBus源码分析
[参考链接:EventBus源码解析][EventBus 4]
EventBus官方原理图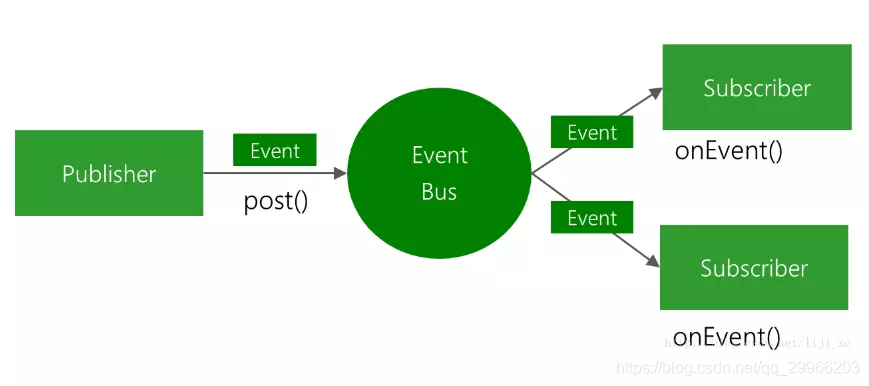
发布者(Publisher)只需要post一个event之后就不用管了,EventBus内部会将event逐一分发给订阅此event的订阅者(Subscriber)
EventBus用于应用内消息事件传递,方便快捷,耦合性低
代码实例
订阅者(Subscriber)
1 | public class EventBusMain extends AppCompatActivity { |
发布者(Publisher)
1 | EventBus.getDefault().post(new RemindBean()) |
源码解析
- register
1 | EventBus.getDefault().register(this); |
- getDefault() :Subscriber获取EventBus实例
EventBus 是一个单例模式,懒汉式,双重校验锁判断解决线程不安全问题
1 | public static EventBus getDefault() { |
- register():在EventBus中将Subscriber与其订阅的event(使用@Subscribe进行注解)关联
1 | public void register(Object subscriber) { |
List findSubscriberMethods(Class<?> subscriberClass):内部利用反射机制(findUsingReflectionInSingleClass)通过订阅者的类的字节码文件 获取 订阅者所有的订阅事件event:
- 通过反射扫描字节码中当前类声明的所有方法,匹配订阅方法(修饰符public、只有1个参数、含有subscribe注解)。并获取订阅方法的一系列信息如:方法第一个参数eventType(Event事件的封装对象,作为通信的信息),ThreadMode(线程模型,包括mainThread,Posting,background,async),priority(优先级),是否粘性等信息。
1 | private void findUsingReflectionInSingleClass(FindState findState) { |
- 将订阅的事件最终保存在HashMap subscriptionsByEventType(key:eventType(事件)、value:Subscription(subscriber,subscribMethod(method,threadMode,eventType),priority)即订阅方法的一系列信息)
- post
1 | EventBus.getDefault().post(new RemindBean("2018-02-12","happy")); |
post(Event)
1 | /** Posts the given event to the event bus. */ |
- 遍历eventTypes(Event类及其父类),并通过postSingleEventForEventType查找所有的订阅者subscriptions。
1 | private boolean postSingleEventForEventType(Object event, PostingThreadState postingState, Class<?> eventClass) { |
- 遍历每个subscription,根据定义的不同线程模式,反射调用相关方法postToSubscription
1 | private void postToSubscription(Subscription subscription, Object event, boolean isMainThread) { |
invokeSubscriber
1 | void invokeSubscriber(Subscription subscription, Object event) { |
EventBus项目实战
- 请求网络时候,等网络返回时通过Handler或Broadcast通知UI;
- 两个Fragment之间需要通过Listener通讯;
okHttp
简介
OkHttp是一个处理网络请求的开源项目,是Android端最火热的轻量级框架,由移动支付Square公司贡献用于替代HttpUrlConnection和Apache HttpClient。
之所以可以赢得如此多开发者的喜爱,主要得益于如下特点:
- 支持HTTPS/HTTP2/WebSocket(在OkHttp3.7中已经剥离对Spdy的支持,转而大力支持HTTP2)
SPDY(读作“SPeeDY”)是Google开发的基于TCP的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验。SPDY是对HTTP协议的加强。新协议的功能包括数据流的多路复用、支持服务器推送技术、请求优先级、HTTP报头压缩以及强制使用SSL传输协议。
- 内部维护任务队列线程池,友好支持并发访问
- 内部维护socket连接池,支持多路复用(共享同一个Socket处理同一个服务器所有请求:同一域名的所有请求stream共享同一个tcp连接),减少连接创建开销(减少握手次数 & 请求延时)
- socket创建支持最佳路由 & 自动重连
- 提供拦截器链(InterceptorChain),实现request与response的分层处理(如透明GZIP压缩,logging等)
- 基于headers的缓存策略减少重复的网络请求
使用
- 同步请求(GET)
对于同步请求在请求时需要开启子线程,请求成功后需要跳转到UI线程修改UI
1 | public void getDatasync(){ |
- 异步请求(POST)
这种方式不用再次开启子线程,但回调方法是执行在子线程中,所以在更新UI时还要跳转到UI线程中。
1 | private void postDataAsync() { |
工作原理
源码解读
- 创建okHttpClient对象
1 | OkHttpClient client = new OkHttpClient(); |
构造函数
1 | public OkHttpClient() { |
为了方便我们使用,提供了一个“快捷操作”,对OkHttpClient.Builder的类成员 全部使用了默认的配置。
1 | public Builder() { |
- 发起 HTTP 请求(同步/异步请求)
- 同步网络请求
1 | Request request = new Request.Builder() |
OkHttpClient实现了Call.Factory,负责根据请求创建新的Call。通过newCall创建RealCall类实例,由RealCall负责进行网络请求操作
1 | public Call newCall(Request request) { |
RealCall#execute:
1 | public Response execute() throws IOException { |
RealCall 做了4件事:
- 检查这个 call 是否已经被执行:每个 call 只能被执行一次,如果想要一个完全一样的 call,可以利用call#clone方法进行克隆。
- 利用client.dispatcher().executed(this)通知开始执行
- 调用getResponseWithInterceptorChain()函数发出网络请求,并解析返回 HTTP 结果。
- 利用client.dispatcher().finished(this)通知已经执行完毕。
dispatcher是OkHttpClient.Builder的成员之一,dispatcher是用于异步 HTTP请求的执行策略,在同步请求它中只用于通知执行状态。
真正发出网络请求,解析返回结果的,还是getResponseWithInterceptorChain:
1 | private Response getResponseWithInterceptorChain() throws IOException { |
the whole thing is just a stack of built-in interceptors.
—— OkHttp 作者
Interceptor是 OkHttp 最核心的一个东西,它不仅只负责拦截请求进行一些额外的处理(如cookie),实际上它把实际的网络请求、缓存、透明压缩等功能统一了起来,每个功能都是一个Interceptor,连接起来成了一个Interceptor.Chain,环环相扣,最终完成一次完整的网络请求。
Interceptor.Chain 分布依次是:
- 在配置OkHttpClient时设置的interceptors;
- 负责失败重试以及重定向的RetryAndFollowUpInterceptor;
- 负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应的BridgeInterceptor;
- 负责读取缓存直接返回、更新缓存的CacheInterceptor;
- 负责和服务器建立连接的ConnectInterceptor;
- 配置OkHttpClient时设置的networkInterceptors;
- 负责向服务器发送请求数据、从服务器读取响应数据CallServerInterceptor。
在这里,位置决定了功能,最后一个 Interceptor 一定是负责和服务器实际通讯的,重定向、缓存等一定是在实际通讯之前的。
责任链模式在这个Interceptor链条中得到了很好的实践。
责任链包含了一些命令对象和一系列的处理对象,每一个处理对象决定它能处理哪些命令对象,它也知道如何将它不能处理的命令对象传递给该链中的下一个处理对象。该模式还描述了往该处理链的末尾添加新的处理对象的方法。
对于把Request变成Response这件事来说,每个Interceptor都可能完成这件事,所以我们循着链条让每个Interceptor自行决定能否完成任务以及怎么完成任务(自力更生或者交给下一个Interceptor)。这样一来,完成网络请求这件事就彻底从RealCall类中剥离了出来,简化了各自的责任和逻辑。两个字:优雅!
责任链模式在安卓系统中也有比较典型的实践,例如 view 系统对点击事件(TouchEvent)的处理。
Interceptor 实际上采用了一种分层的思想,每个Interceptor都是一层。分层简化了每一层的逻辑,每层只需要关注自己的责任(单一原则思想),而各个层之间通过约定的接口/协议进行合作(面向接口编程思想),共同完成复杂的任务。
这种分层的思想在TCP/IP协议(4层协议)中体现的淋漓尽致。
OkHttp 主要通过ConnectInterceptor和CallServerInterceptor和服务器的进行实际通信。
- 建立连接 ConnectInterceptor
1 |
|
实际上建立连接就是创建了一个HttpCodec对象,用于后面通信中发送和接受数据。它是对HTTP协议操作的抽象,有两个实现:Http1Codec和Http2Codec,分别对应 HTTP/1.1 和 HTTP/2 版本的实现。
创建HttpCodec对象过程就是找到一个可用的RealConnection,再利用RealConnection的输入输出(BufferdSource 和 BufferedSink)创建HttpCodec对象,供后续步骤使用。
在Http1Codec中,它利用Okio对Socket的读写操作进行封装,Okio是对java.io和java.nio进行了封装,让我们更便捷高效的进行
IO 操作。
- 发送和接受数据 CallServerInterceptor
1 |
|
- 向服务器发送 request header;如果有 request body,就向服务器发送;
- 读取 response header,先构造一个Response对象;如果有 response body,就在 header的基础上加上 body 构造一个新的Response对象;
核心操作由HttpCodec对象完成,HttpCodec封装Okio,Okio封装Socket。完成网络的通信。 - 异步网络请求
1 | Request request = new Request.Builder() |
实际调用RealCall#enqueue
1 | public void enqueue(Callback responseCallback) { |
dispatcher 用于对异步请求进行分发、执行。
如果当前还能执行一个并发请求,那就立即执行,否则加入readyAsyncCalls队列。
正在执行的请求执行完毕之后,会调用promoteCalls()函数,来把readyAsyncCalls队列中的AsyncCall “提升” 为runningAsyncCalls,并开始执行。
这里的AsyncCall是RealCall的一个内部类,它实现了Runnable,所以可以被提交到ExecutorService上执行,而它在执行时会调用getResponseWithInterceptorChain()函数,并把结果通过responseCallback传递给上层使用者。
这样看来,同步请求和异步请求的原理是一样的,都是在getResponseWithInterceptorChain()函数中通过Interceptor链条来实现的网络请求逻辑,而异步则是通过ExecutorService实现。
- 获取 HTTP 响应
在上述同步(Call#execute()执行之后)或者异步(Callback#onResponse()回调中)请求完成之后,我们就可以从Response对象中获取到响应数据了,包括 HTTP status code,status message,response header,response body 等。这里 body 部分最为特殊,因为服务器返回的数据可能非常大,所以必须通过数据流的方式来进行访问(当然也提供了诸如string()和bytes()这样的方法将流内的数据一次性读取完毕),而响应中其他部分则可以随意获取。
- 发送和接受数据 CallServerInterceptor
1 | if (!forWebSocket || response.code() != 101) { |
- HTTP缓存
- 读取 & 缓存数据 CallServerInterceptor
在建立连接、和服务器通讯之前,检查响应是否已经被缓存、缓存是否可用,如果是则直接返回缓存的数据,否则就进行后面的流程,并在响应返回之前,把网络的数据写入缓存。
具体的缓存逻辑 OkHttp 内置封装了一个Cache类,它利用DiskLruCache,用磁盘上的有限大小空间进行缓存,按照 LRU 算法进行缓存淘汰。
总结
- OkHttpClient实现Call.Factory,负责为Request创建Call;
- RealCall为具体的Call实现,其enqueue()异步接口通过Dispatcher利用ExecutorService + AsyncCall队列 实现,而最终进行网络请求时和同步execute()接口一致,都是通过getResponseWithInterceptorChain()函数实现;
- getResponseWithInterceptorChain()中利用Interceptor拦截链,将缓存、透明压缩、网络 IO 等功能统一起来,层层实现,最终完成一次完整的网络请求。
设计模式
- 建造者模式
1 | public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory { |
- 工厂模式
1 | public interface Call extends Cloneable { |
- 观察者模式
源码中的EventListener对请求/响应过程中的每一个Event通过方法回调的方式通知前方用户,用户需要自己实现EventListener中的所需要的方法:
1 | public abstract class EventListener { |
- 单例模式
创建OkHttpClient对象的时候,就推荐使用单例模式,防止创建多个OkHttpClient对象,损耗资源;
- 策略模式
在CacheInterceptor中,在响应数据的选择中使用了策略模式,选择缓存数据还是选择网络访问。
CacheInterceptor根据一个缓存策略,来决定选择缓存数据,还是网络请求数据:
- 请求头包含 “If-Modified-Since” 或 “If-None-Match” 暂时不走缓存
- 客户端通过 cacheControl 指定了无缓存,不走缓存
- 客户端通过 cacheControl 指定了缓存,则看缓存过期时间,符合要求走缓存。
- 如果走了网络请求,响应状态码为 304(只有客户端请求头包含 “If-Modified-Since” 或 “If-None-Match” ,服务器数据没变化的话会返回304状态码,不会返回响应内容), 表示客户端继续用缓存。
- 责任链模式
okhttp可以针对请求配置很多拦截器,而这些拦截器正是通过责任链模式链接起来,并最终返回处理的结果。
封装
由于okhttp是偏底层的网络请求类库,返回结果的回调方法仍然执行在子线程中,需要自己跳转到UI线程,使用麻烦。为了使用方便需要对OKHttp进行再次封装。
[guozhengXia/OkHttpUtils][guozhengXia_OkHttpUtils]
最简单的okhttp封装,CallBack方法执行在UI线程。支持get请求,post请求,支持文件上传和下载。
网络框架对比
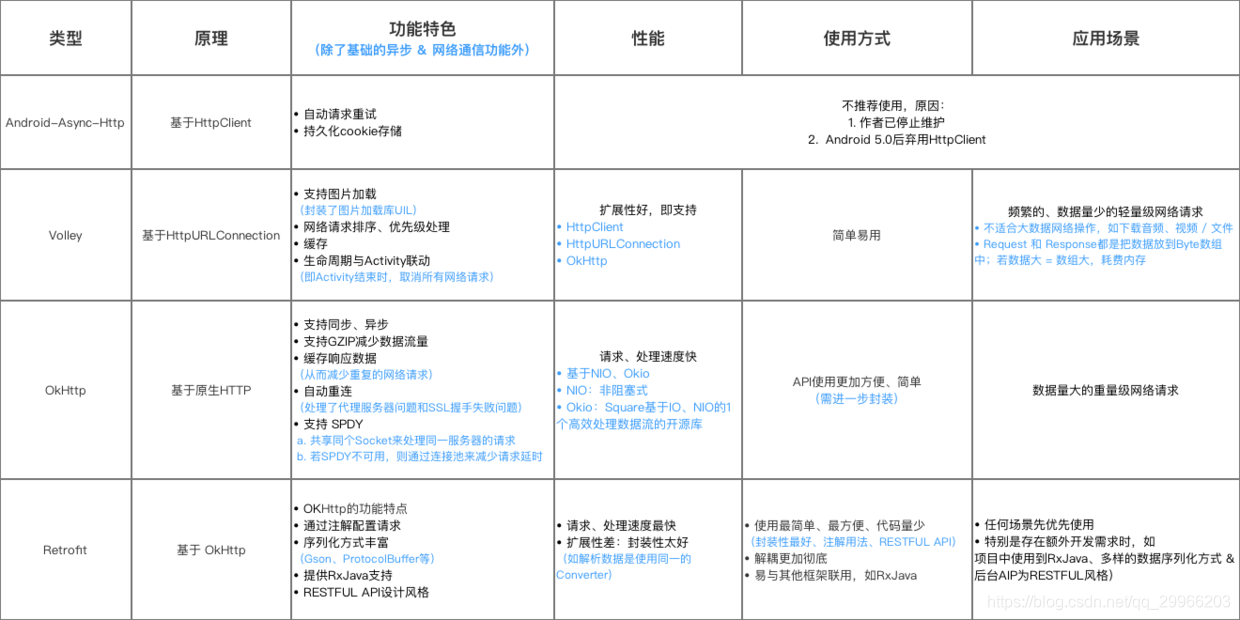
Glide
简介
Glide,一个被google所推荐的图片加载库,作者是bumptech。这个库被广泛运用在google的开源项目中,包括2014年的google I/O大会上发布的官方app。
Glide滑行的意思,可以看出这个库的主旨就在于让图片加载变的流畅。
- 多样化媒体加载
Glide 不仅是一个图片缓存,它支持 Gif、WebP、缩略图。甚至是 Video - 生命周期绑定 & 动态管理
- 高效缓存策略
(1)支持Memory和Disk图片缓存
(2)内存开销小(Glide根据ImageView大小缓存图片 & 使用合理的解码方式)
使用
- 导入
1 | implementation 'com.github.bumptech.glide:glide:3.7.0' |
- 基础使用
(1)基本方法
1 | String url = "http://img1.dzwww.com:8080/tupian_pl/20150813/16/7858995348613407436.jpg"; |
- with(Context context) 决定Glide加载图片的生命周期
可以使用 Activity、FragmentActivity、android.support.v4.app.Fragment、android.app.Fragment 等对象。将 Activity/Fragment 对象作为参数的好处是,图片的加载会和 Activity/Fragment 的生命周期保持一致,例如:onPaused 时暂停加载,onResume 时又会自动重新加载。所以在传参的时候建议使用 Activity/Fragment 对象,而不是 Context。 - load(String url) 加载图片URL
url包括网络图片、本地图片、应用资源、二进制流、Uri对象等等(重载) - into(ImageView imageView) 需要显示图片的目标 ImageView
(2)扩展方法
1 | Glide.with(context) |
- 进阶使用
- Target
- Transformations
通过 Transformations 操作 bitmap 来实现,我们可以修改图片的任意属性:尺寸,范围,颜色,像素位置等等。fitCenter 和 centerCrop ,这两个是 Glide 已经实现的Transformations。
自定义Transformation,继承BitmapTransformation接口
图片切圆角操作
1 | public class RoundTransformation extends BitmapTransformation { |
图片顺时针旋转90度操作
1 | public class RotateTransformation extends BitmapTransformation { |
使用
1 | // 单个Transformation |
这里有一个 GLide Transformations 的库,它提供了很多 Transformation 的实现,非常值得去看,不必重复造轮子对吧!
[wasabeef/glide-transformations][wasabeef_glide-transformations]
- Animate
自定义缩放动画
1 | <set xmlns:android="http://schemas.android.com/apk/res/android" |
使用
1 | Glide.with(context) |
- Modules
工作原理(非重点)
- 主流程
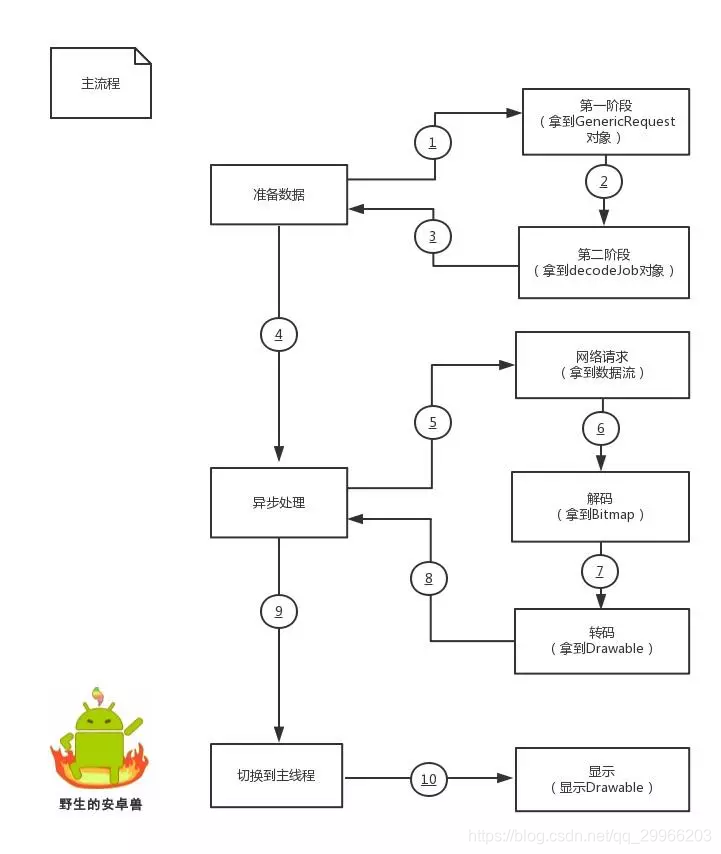
三件大事:
- 准备数据
Glide中存在大量的类和对象,Glide在初始时,就尽量把所有需要使用的对象构造并封装,层层传递。
第一阶段:构建GenericRequest对象(面向用户构建,受用户调用API或修改配置所影响)
第二阶段:从GenericRequest对象中,解封得到需要对象,构建出decodeJob对象,是异步处理中核心对象(面向Glide构建) - 异步处理
经过前面大量准备工作,这一步,Glide在工作线程中进行图片数据请求,包括三步:
(1)发起网络请求,拿到数据流;
(2)将数据流解码成bitmap对象;
(3)将bitmap对象转码成Drawable对象 - 切换到主线程
切换为主线程,将Drawable对象显示
- 源码解读
1 | Glide.with(this).load(url).into(imageView); |
- with(Context/Activity/Fragment)
得到一个RequestManager对象(实现request和Activity/Fragment生命周期的关联)
Glide再根据传入的with()方法的参数确定图片加载的生命周期:
- Application类型参数——应用程序生命周期
- 非Application类型参数——Activity/Fragment生命周期
- load(url)
实质上还是做前期的数据准备,主要就是构造对象,封装对象。
得到一个DrawableTypeRequest对象(extends DrawableRequestBuilder)
- into(imageView)
into比较复杂,其涉及了“准备数据”,“异步处理”,“切换到主线程”这三大步的内容。包括:
(1)准备过程 第一阶段:构造出GenericRequest对象(封装了Glide中所有的相关对象)
(2)准备过程 第二阶段:使用 第一阶段 生成的GenericRequest对象,从GenericRequest对象取出各种需要的对象,传递给Engine的load函数,最终构造出了decodeJob对象。
(3)异步调用 : 使用decodeJob 对象进行:
- 发起网络请求,拿到数据流
- 将数据流解码成bitmap对象
- 将bitmap对象转码成Drawable对象(保证静图和动图的类型一致性(动图的类型是Drawable))
(4)切换到主线程,显示Drawable对象
通过Handler机制,Glide从工作线程切换到主线程,并最终将Drawable对象显示到ImageView上。
图片加载框架对比
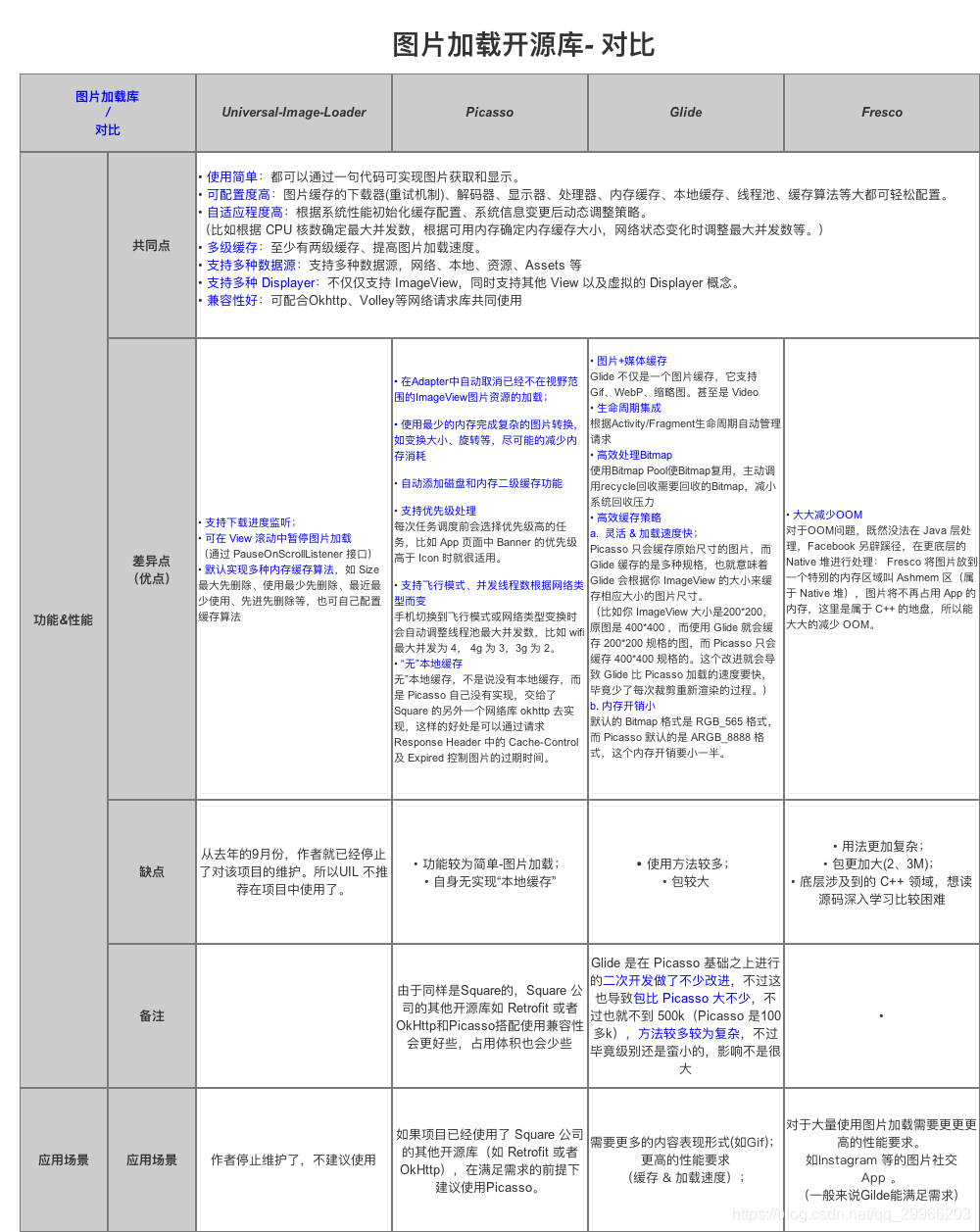
第十三章 杂七杂八
- 进程保活
- Android进程回收策略 及 进程优先级
- 进程保活方案
- Service如何保持不被杀死
- 屏幕适配
- 混生开发
- React Native、weex、Flutter ?对比?
- 谷歌新出的官方开发语言Kotlin了解吗 & 和Java相比它有哪些特点。
- ReactNative 和 Android 如何交互?
- 一个APP从启动到主页面显示经历了哪些过程?
- APP 推送
- Android 虚拟机及编译过程
- Dalvik虚拟机
- ART虚拟机与Dalvik虚拟机的区别
- Android APK 编译打包流程
- Android dex分包方案和热补丁原理
- Android dex文件 & 类加载器DexLoader
- dex分包方案
- 热补丁
- Android 插件化
- Android MVP模式
进程保活
[关于 Android 进程保活,你所需要知道的一切][Android 2]
Android进程回收策略 及 进程优先级
- Android 进程回收策略(一种根据 OOM_ADJ 阈值级别触发相应力度的内存回收的机制)
Android 系统将尽量长时间地保持应用进程,但随着打开的应用越多,后台应用进程也越多。容易导致系统内存不足。
为了新建进程或运行更重要的进程,最终需要清除旧进程来回收内存。 为了确定保留或终止哪些进程,系统会根据进程的状态等,给进程分配一个优先级。当系统内存不足时,系统会按照优先级高低依次清除进程,回收系统资源。 - 进程优先级
| 优先级排序 | 进程类型 | 说明 |
| 1 | 前台进程 | 用户当前操作所必需的进程。通常在任意给定时间前台进程都为数不多。 只有在内存不足以支持它们同时继续运行这一万不得已的情况下,系统才会终止它们。 |
| 2 | 可见进程 | 没有任何前台组件、但仍会影响用户在屏幕上所见内容的进程,可见进程被视为是极其重要的进程。 除非为了维持所有前台进程同时运行而必须终止,否则系统不会终止这些进程。 |
| 3 | 服务进程 | 尽管服务进程与用户所见内容没有直接关联,但是它们通常在执行一些用户关心的操作(例如,在后台播放音乐或从网络下载数据)。 因此,除非内存不足以维持所有前台进程和可见进程同时运行,否则系统会让服务进程保持运行状态。 |
| 4 | 后台进程 | 后台进程对用户体验没有直接影响,通常会有很多后台进程在运行,它们会保存在 LRU 列表中,以确保包含用户最近查看的 Activity 的进程最后一个被终止。 系统可能随时终止它们,以回收内存供前台进程、可见进程或服务进程使用。 |
| 5 | 空进程 | 保留这种进程的的唯一目的是用作缓存,以缩短下次在其中运行组件所需的启动时间。 为使总体系统资源在进程缓存和底层内核缓存之间保持平衡,系统往往会终止这些进程。 |
进程保活方案
核心思想:提高进程优先级
- 通过开启服务提升进程优先级
对于需要在后台长期运行的操作可以通过创建对应的服务Service(排名3)而不是在Activity开启一个后台子线程(排名4)提高进程优先级 - 利用通知(Notification)提升权限
启动一个前台的Service进程,这样会在系统的通知栏生成一个通知(Notification),使用户可见该运行的app。从而使进程的优先级仅仅低于用户当前正在交互的进程,与可见进程优先级一致,使进程被杀死的概率大大降低。 - 通过广播唤醒(不同app进程之间/系统提供广播)
- 场景1:系统监听开机、网络状态、拍照等事件,产生广播唤醒app
- 场景2:接入第三方SDK唤醒相应的app进程(如微信sdk,包括微信支付会唤醒微信、或者支付宝会唤醒淘宝等同属于阿里系的app)经常通过推送SDK对app进程保活
Service如何保持不被杀死
- onStartCommand方法,返回START_STICKY
服务的onStartCommand方法
1 |
|
onStartCommand 返回值
| 返回值 | 含义 | 适用场景 |
|---|---|---|
| START_STICKY | 当Service因内存不足而被系统kill后,一段时间后内存再次空闲时,系统将会尝试重新创建此Service,一旦创建成功后将回调onStartCommand方法,但其中的Intent将是null,也就是onStartCommand方法虽然会执行但是获取不到intent信息 | 这个状态下比较适用于任意时刻开始、结束的服务如音乐播放器 |
| START_NOT_STICKY | 当Service因内存不足而被系统kill后,即使系统内存再次空闲时,系统也不会尝试重新创建此Service。除非程序中再次调用startService启动此Service,这是最安全的选项,可以避免在不必要时以及应用能够轻松重启所有未完成的作业时运行服务 | 某个Service执行的工作被中断几次无关紧要 |
| START_REDELIVER_INTENT | 当Service因内存不足而被系统kill后,则会重建服务,并通过传递给服务的最后一个 Intent 调用 onStartCommand(),任何挂起 Intent均依次传递。与START_STICKY不同的是,其中的传递的Intent将是非空,是最后一次调用startService中的intent | 适用于主动执行应该立即恢复的作业(例如下载文件)的服务 |
手动返回START_STICKY,当service因内存不足被kill,等到内存空闲后,service又被重新创建。
1 |
|
- 在AndroidManifest中通过android:priority提升service优先级
在AndroidManifest.xml文件中对于intent-filter可以通过android:priority = “1000”这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低,同时适用于广播。
1 | <service |
- 使用startForeground 将service放到前台状态,提升service进程优先级
Android中的进程是托管的,当系统进程空间紧张的时候,会依照优先级自动进行进程的回收。Android将进程分为6个等级,它们按优先级顺序由高到低依次是:
前台进程( FOREGROUND_APP)、可视进程(VISIBLE_APP )、次要服务进程(SECONDARY_SERVER )、后台进程 (HIDDEN_APP)、内容供应节点(CONTENT_PROVIDER)、空进程(EMPTY_APP)
当service运行在低内存的环境时,将会kill掉一些存在的进程。因此进程的优先级将会很重要,可以使用startForeground 将service放到前台状态。这样在低内存时被kill的几率会低一些。
1 |
|
- onDestroy方法里重启service
service +broadcast 方式,就是当service调用ondestory的时候,发送一个自定义的广播,当收到广播的时候,重新启动service;或直接startService()重新打开服务
屏幕适配
[一种极低成本的Android屏幕适配方式——字节跳动技术团队][Android 3]
- 传统dp适配方式
android中的dp在渲染前会将dp转为px,计算公式: - px = density * dp;
- density = dpi / 160;
- px = dp * (dpi / 160);
而dpi是根据屏幕真实的分辨率和尺寸来计算的,每个设备都可能不一样的。
通常情况下,一部手机的分辨率是宽x高,屏幕大小是以寸为单位,那么三者的关系是(屏幕分辨率为:1920*1080,屏幕尺寸为5吋的话,那么dpi为440。)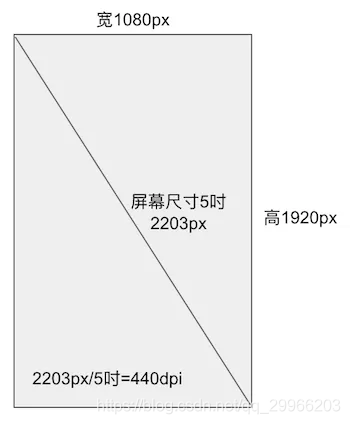
由于不同手机屏幕尺寸、分辨率不同,因此dpi的值很乱,导致dp适配效果(px = (dpi/160)*dp)结果很乱,没有规律,因此应该使用新的适配方式。
- 屏幕适配切入点
根据 dp和px的转换公式 :px = dp * density ,可通过修改density保证所有设备计算出的px值满足该设备的要求。
布局文件中dp的转换,最终都是调用 TypedValue#applyDimension(int unit, float value, DisplayMetrics metrics) 来进行转换。因此我们只需要修改 DisplayMetrics 中和 dp 转换相关的变量即可。
1 | public static float applyDimension(int unit, float value, |
- 最终方案
下面假设设计图宽度是360dp,以宽维度来适配。
那么适配后的 density = 设备真实宽(单位px) / 360,接下来只需要把我们计算好的 density 在系统中修改下即可。同时应该修改文字的scaledDensity,可以通过计算之前scaledDensity和density的比获得现在的scaledDensity。并通过registerComponentCallbacks注册监听文字的切换。
1 | private static float sRoncompatDennsity; |
混生开发
跨平台开发是为了增加代码复用,减少开发者对多个平台差异适配的工作量,降低开发成本,提高业务专注的同时,提供比web更好的体验。
React Native、weex、Flutter ?对比?
| React Native | weex | Flutter | |
|---|---|---|---|
| 出品 | Alibaba | ||
| 语言 | JavaScript | JavaScript | Dart |
| 引擎 | JSCore | JS V8 | Flutter Engine |
| 设计模式 | React | Vue | 响应式 |
| 社区 | 丰富,Facebook终点维护 | 有点残念,托管apache | 较多拥护者 |
| 难度 | 较大 | 较小 | 一般 |
| 支持 | Android IOS | Android IOS Web | Android IOS 等等 |
| 现状 | 作为RN平台最大支持者Airbnb放弃使用RN 项目庞大维护困难,第三方库良莠不齐,兼容性差 |
被托管到了Apache,拭目以待 | Flutter 是 Google 跨平台移动UI框架,被重点维护 |
谷歌新出的官方开发语言Kotlin了解吗 & 和Java相比它有哪些特点。
由 JetBrains 开发。用于现代多平台应用的静态编程语言。
Kotlin可以编译成Java字节码,也可以编译成JavaScript,方便在没有JVM的设备上运行。
Kotlin已正式成为Android官方支持开发语言。
兼容/无缝对接java,可以java代码和kotlin代码互相调用。一键java转kotlin,如果你有遗留的java代码,可以一键转换
与Java对比
- 更简洁:这是它重要的优点之一,可以比Java编写少得多的代码。
- 更安全:Kotlin是空安全的,它在编译期间就会处理各种为null的情况,无需像java一样添加很多的判空代码,节约很多调试空指针异常的时间,很大程度上避免出现NullPointException。
- 易扩展:扩展函数意味着我们不仅可以扩展我们原有写好的类,还可以扩展系统级的类,非常灵活,另外如果在类里编写扩展函数,那么只对当前类生效。
- 函数式:Kotlin使用了很多函数式编程的概念,比如用到了lambda表达式来更方便地解决问题。
- Kotlin Android Extensions:再也不用编写烦人的findViewById()了,如果你集成了ButterKnife,是时候删除对它的依赖了,Kotlin支持了对于View以id形式访问。
- 不用写分号,就像你看到的上述代码一样,对于很多写过脚本语言的童鞋来说,不要写分号这一点真是节省了很多时间,对于一天写几百行几千行甚至上万行代码的童鞋们来说,相当于省了多少个分号.
ReactNative 和 Android 如何交互?
[ReactNative 官方文档][ReactNative]
- Android 端
创建一个原生模块类CommonModule,继承ReactContextBaseJavaModule,并复写getName()方法,创建暴露给RN调用的方法,并使用@ReactMethod注解修饰
1 | public class CommonModule extends ReactContextBaseJavaModule { |
创建类 CommonPackage 实现接口 ReactPackage 包管理器,并把第1步中创建好的 CommonModule 类添加进来
1 | public class CommonPackage implements ReactPackage { |
将创建好的 CommonPackage 包管理器添加到 ReactPackage 列表中,即在MainApplication.java文件中getPackages方法中提供
1 | protected List<ReactPackage> getPackages() { |
- ReactNative 端
把原生模块封装成一个JavaScript模块
1 | 'use strict'; |
调用该模块方法
1 | import CommonModule from './CommonModule'; |
补:RN 用 Promise 机制与安卓原生代码通信
在原生代码 CommonModule 类中创建桥接方法,当桥接的方法最后一个参数是 Promise 对象,那么该方法就会返回一个JS 的 Promise 对象给对应的 JS 方法
首先需要在 CommonModule 中定义一个暴露给 RN 的方法,并且要用 @ReactMethod 标识
- Android端 发送消息
1 |
|
- RN端 收到消息
1 | const commonModule = NativeModules.CommonModule; |
一个APP从启动到主页面显示经历了哪些过程?
[Github:一个APP从启动到主页面显示经历了哪些过程?][Github_APP]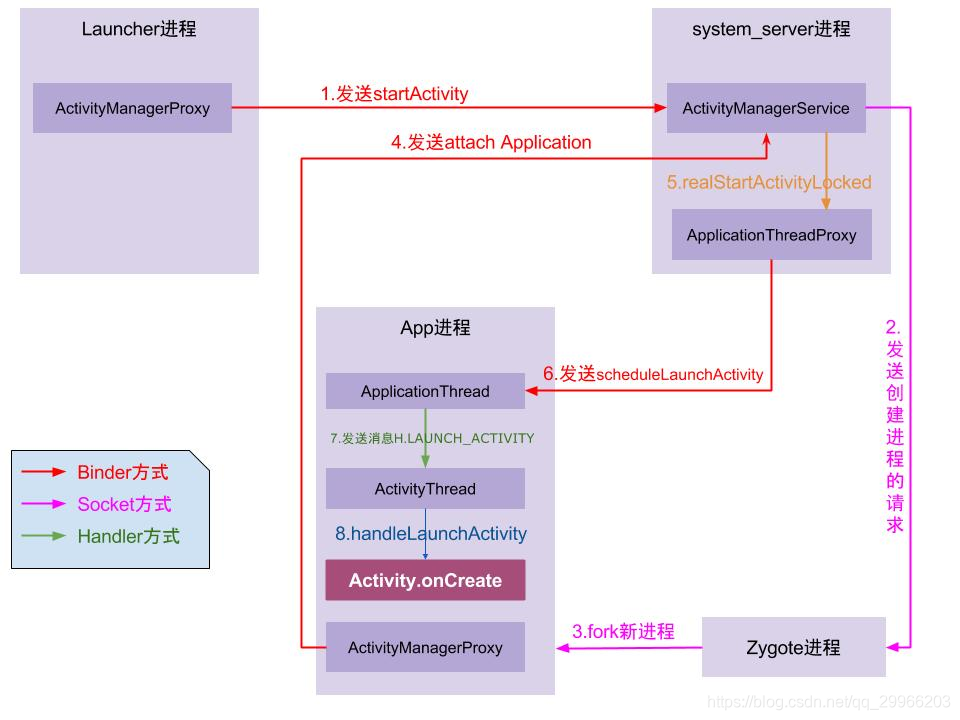
创建进程(AMS → Zygote)
- 点击桌面App图标,Launcher进程采用Binder IPC向system_server进程发起startActivity请求;
- system_server进程接收到请求后,调用ASM的startActivity方法,最后向zygote进程发送创建进程的请求;
- Zygote进程fork出新的子进程,即App进程;
- App进程内调用ActivityThread.main()方法,随后依次调用Looper.prepareLoop()和Looper.loop()来开启消息循环。
绑定Application(App → AMS) - App进程随后调用attach()方法,通过Binder IPC向sytem_server进程发起attachApplication请求;
- system_server进程在收到请求后,将进程和指定的Application绑定起来。
显示Activity界面(AMS → App) - 此时系统已经拥有了该application的进程,它通过binder IPC向App进程发送scheduleLaunchActivity请求启动一个新进程的activity;
- App进程的binder线程(ApplicationThread)在收到请求后,通过handler向主线程发送LAUNCH_ACTIVITY消息;
- 主线程在收到Message后,开始创建目标Activity,通过performLaunchActiivty()方法回调Activity.onCreate()和onStart()方法。
- 到此,App便正式启动,开始进入Activity生命周期,执行完onCreate/onStart/onResume方法,UI渲染结束后便可以看到App的主界面。
补充:Binder通信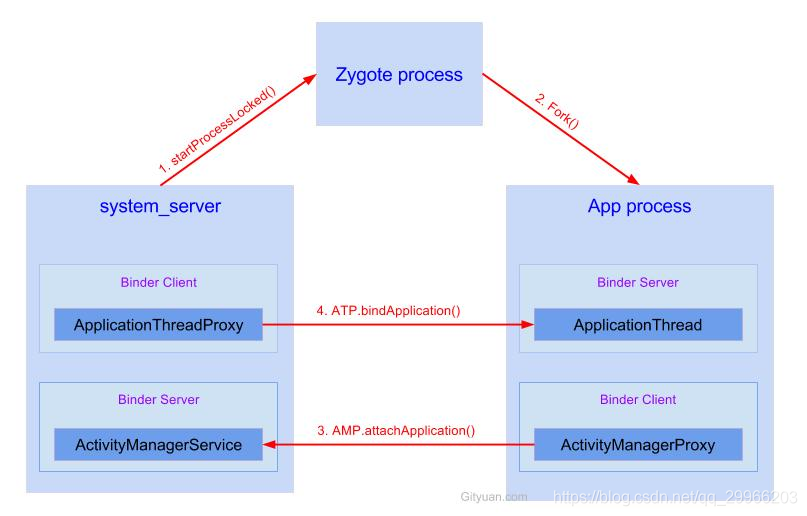
简称:
ATP: ApplicationThreadProxy syetem_server 客户端
AMS: ActivityManagerService syetem_server 服务端
AT: ApplicationThread 新创建/App进程 服务端
AMP: ActivityManagerProxy 新创建/App进程 客户端
图解:
①system_server进程中调用startProcessLocked方法,该方法最终通过socket方式,将需要创建新进程的消息告知Zygote进程,并阻塞等待Socket返回新创建进程的pid;
②Zygote进程接收到system_server发送过来的消息, 则通过fork的方法,将zygote自身进程复制生成新的进程,并将ActivityThread相关的资源加载到新进程app process,这个进程可能是用于承载activity等组件;
③ 在新进程app process向servicemanager查询system_server进程中binder服务端AMS, 获取相对应的Client端,也就是AMP. 有了这一对binder c/s对, 那么app process便可以通过binder向跨进程system_server发送请求,即attachApplication()
④system_server进程接收到相应binder操作后,经过多次调用,利用ATP向app process发送binder请求, 即bindApplication. system_server拥有ATP/AMS, 每一个新创建的进程都会有一个相应的AT/AMP,从而可以跨进程 进行相互通信. 这便是进程创建过程的完整生态链。
APP 推送
- 定义 & 使用场景
- 定义
服务端主动发送消息,客户端被动接收服务端数据 - 使用场景
广告、及时通讯
- 实现原理
- 轮询(Pull)
应用程序隔固定时间主动与服务器进行连接并查询是否有新的消息。
不适用于即时通讯产品,客户端需要不断检测服务器数据(每隔很短时间连一次服务器),浪费客户端资源(CPU、网络流量、系统电量) - SMS(Push)
服务器有新消息时,发送1条类似短信的信令给客户端,客户端通过拦截信令,解析消息内容 / 向服务器获取信息。
可以实现实时操作,但是实现成本很高,需要向移动公司缴纳相应费用。 - 长连接(Push)
长连接是目前APP推送 最佳 & 主要 的底层实现机制
客户端主动和服务器建立TCP长连接之后, 客户端定期向服务器发送心跳包, 有消息的时候, 服务器直接通过这个已经建立好的TCP连接通知客户端。
(1)TCP长连接
长连接即客户端与服务端建立连接后,互相通信,数据发送完成后也不主动断开连接,之后有需要发送的数据就继续通过该连接发送。
TCP连接在默认情况下为长连接,即如果连接双方不主动关闭连接,这个连接就一直存在。有一些情况会导致连接切断,如:链路故障,服务器宕机,NAT超时,网络状态变化……
(2)心跳包(保活TCP连接)
客户端通过每隔一段时间发送一段极短的数据,证明客户端还活着。如果服务端在一定时间收不到客户端数据,则说明连接断开,服务端便不再向该客户端发送推送消息。
- 解决方案
- C2DM
Google提供了C2DM(Cloud to Device Messaging)服务。Android Cloud to Device Messaging (C2DM)是一个用来帮助开发者从服务器向Android应用程序发送数据的服务。该服务提供了一个简单的、轻量级的机制,允许服务器可以通知移动应用程序直接与服务器进行通信,以便于从服务器获取应用程序更新和用户数据。C2DM服务负责处理诸如消息排队等事务并向运行于目标设备上的应用程序分发这些消息。
- MQTT协议
轻量级的消息发布/订阅协议,基于Push方式,wmqtt.jar 是IBM提供的MQTT协议的实现。 - XMPP协议
Extensible Messageing and Presence Protocol,可扩展消息与存在协议,是基于可扩展标记语言(XML)的协议,是目前主流的四种IM协议之一。
主流四种IM协议:XMPP协议、IMPP协议(即时信息和空间协议)、PRIM协议(空间和即时信息协议)、SIP协议(即时通讯和空间平衡扩充的进程开始协议)
XMPP协议是针对消息推送的协议,精简。开源、简单且可扩展性强。
- 第三方平台(激光推送)
- 自己搭建一个推送平台
[Android的socket通信的长连接,有心跳检测][Android_socket]
[高效 保活长连接:手把手教你实现 自适应的心跳保活机制][Link 6]
(1)长连接 && 心跳检测(保活长连接) - 长连接
在Android中建立长连接,不能使用HttpUrlConnection或者HttpClient等网络请求API,因为它们是属于上层的、HTTP协议的。Java为开发者提供了网络套接字Socket。
1 | private void initSocket() throws UnknownHostException, IOException { |
- 心跳检测
通过Handler.postDelayed(Runnable , TimeMillis)实现定时发送心跳检测功能。因为客户端与服务端可能不属于同一线程,考虑AIDL。
1 | // 发送心跳包 |
(2)封装发送数据 / 解析接收数据
建立Socket长连接后,数据在Socket通道中以字节流的形式传输,通过InputStream和outputStream读取和发送数据。我们应该定义通信的数据格式(如HTTP格式包含:协议头+协议主体+校验码),可参考XMPP协议封装数据。
Android 虚拟机及编译过程
Dalvik虚拟机
- Dalvik 虚拟机
Dalvik是Google公司自己设计用于Android平台的Java虚拟机,它是Android平台的重要组成部分,支持dex格式(Dalvik Executable)的Java应用程序的运行。dex格式是专门为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。Google对其进行了特定的优化,使得Dalvik具有高效、简洁、节省资源的特点。从Android系统架构图知,Dalvik虚拟机运行在Android的运行时库层。
Dalvik作为面向Linux、为嵌入式操作系统设计的虚拟机,主要负责完成对象生命周期管理、堆栈管理、线程管理、安全和异常管理,以及垃圾回收等。 - 特点
- 体积小,占用内存空间小;
- 专有的DEX可执行文件格式,体积更小,执行速度更快;
- 常量池采用32位索引值,寻址类方法名,字段名,常量更快;
- 基于寄存器架构,并拥有一套完整的指令系统;
- 提供了对象生命周期管理,堆栈管理,线程管理,安全和异常管理以及垃圾回收等重要功能;
- 所有的Android程序都运行在Android系统进程里,每个进程对应着一个Dalvik虚拟机实例。
- DVM & JVM 区别
(1)执行文件不同
Java虚拟机运行的是Java字节码,Dalvik虚拟机运行的是Dalvik字节码。
传统的Java程序经过编译,生成Java字节码保存在class文件中,Java虚拟机通过解码class文件中的内容来运行程序。
Dalvik虚拟机运行的是Dalvik字节码,所有的Dalvik字节码由Java字节码转换而来,并被打包到一个DEX(Dalvik Executable)可执行文件中。Dalvik虚拟机通过解释DEX文件来执行这些字节码。
Dalvik可执行文件体积小。Android SDK中有一个叫dx的工具负责将Java字节码转换为Dalvik字节码。
dx工具消除java类文件的冗余信息,重新组合形成一个常量池,所有的类文件共享同一个常量池。由于dx工具对常量池的压缩,使得相同的字符串,常量在DEX文件中只出现一次,从而减小了文件的体积。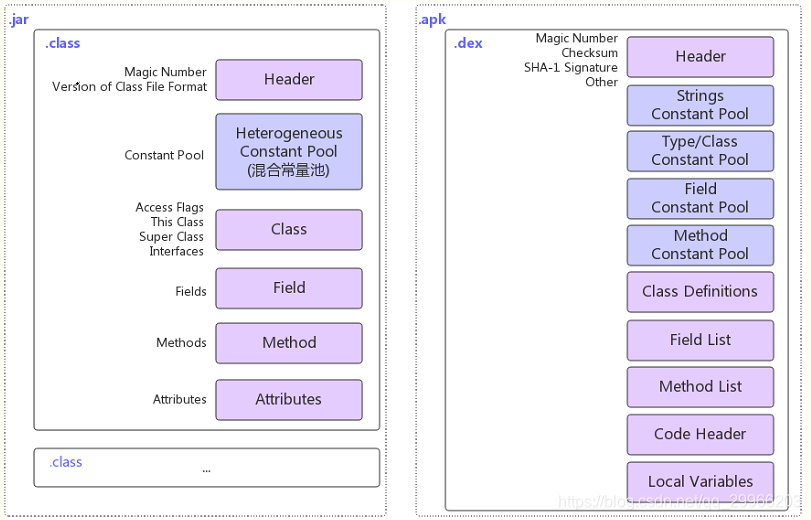
简单来讲,dex格式文件就是将多个class文件中公有的部分统一存放,去除冗余信息。
(2)架构不同
Java虚拟机基于栈架构,Dalvik虚拟机基于寄存器架构。
Java虚拟机基于栈架构,程序在运行时虚拟机需要频繁的从栈上读取或写入数据,这个过程需要更多的指令分派与内存访问次数,会耗费不少CPU时间,对于像手机设备资源有限的设备来说,这是相当大的一笔开销。Dalvik虚拟机基于寄存器架构。数据的访问通过寄存器间直接传递,这样的访问方式比基于栈方式要快很多。 - 结构
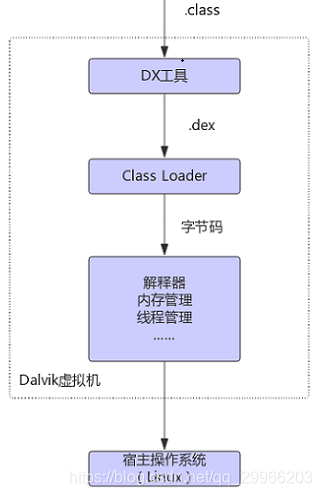
一个应用首先经过DX工具将class文件转换成Dalvik虚拟机可以执行的dex文件,然后由类加载器加载原生类和Java类,接着由解释器根据指令集对Dalvik字节码进行解释、执行。最后,根据dvm_arch参数选择编译的目标机体系结构。
ART虚拟机与Dalvik虚拟机的区别
Android 从5.0开始默认使用ART虚拟机执行程序,抛弃了Dalvik虚拟机.加快了Android的运行效率,提高系统的流畅性。
ART 机制
ART代表Android Runtime,其处理应用程序执行的方式完全不同于Dalvik,Dalvik是依靠一个Just-In-Time (JIT)编译器去解释字节码。开发者编译后的应用代码需要通过一个解释器在用户的设备上运行,即翻译工作是在程序运行时进行的。这一机制并不高效,但让应用能更容易在不同硬件和架构上运行。
ART则完全改变了这套做法,在应用安装时就预编译字节码到机器语言,这一机制叫Ahead-Of-Time (AOT)编译,ART在APK在安装时就对其包含的Dex字节码进行翻译,得到对应的本地机器指令,于是就可以在运行时直接执行了,即翻译工作是在APK安装时进行的。应用程序执行将更有效率,启动更快;缺点就是需占用更大的存储空间与更长的应用安装时间(空间换取时间策略)。
ART虚拟机相对于Dalvik虚拟机的提升
| Dalvik虚拟机 | ART虚拟机 | |
|---|---|---|
| 预编译 | 采用的是JIT来做及时翻译(动态翻译),在运行时将dex通过解释器翻译成native code | 使用了AOT直接在安装时将dex翻译成native code |
| 垃圾回收机制 | 标记-清除 算法 (非并发过程STW)如果出现内存不足时,GC频繁会导致UI卡顿掉帧不流畅 |
标记-压缩 + 部分并发 提高GC效率 |
| 内存管理 | 内存碎片化严重(标记清除算法) | 进行内存管理,减少内存碎片化,提高内存效率 (标记-压缩:将不连续的物理内存块进行压缩) |
Android APK 编译打包流程
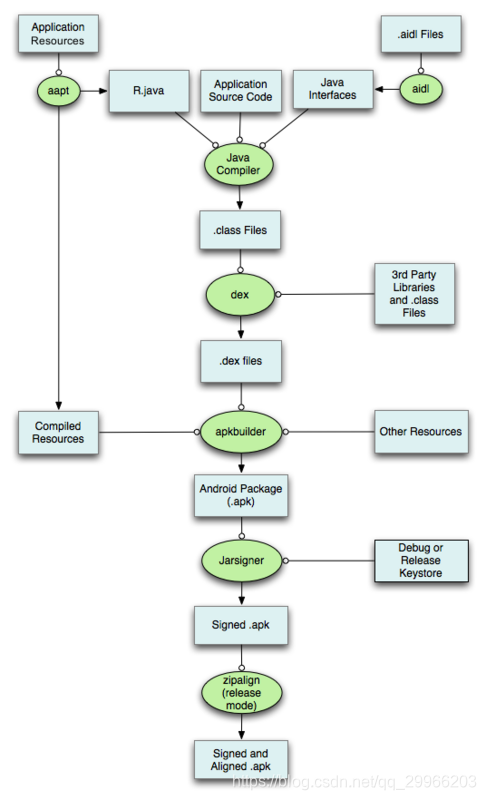
- Java编译器对工程本身的java代码进行编译,这些java代码有三个来源:app的源代码,由资源文件生成的R文件(aapt工具),以及有aidl文件生成的java接口文件(aidl工具)。产出为.class文件。
①用AAPT编译R.java文件
②编译AIDL的java文件
③把java文件编译成class文件 - .class文件和依赖的三方库文件通过dex工具生成Delvik虚拟机可执行的.dex文件,包含了所有的class信息,包括项目自身的class和依赖的class。产出为.dex文件。
- apkbuilder工具将.dex文件和编译后的资源文件生成未经签名对齐的apk文件。这里编译后的资源文件包括两部分,一是由aapt编译产生的编译后的资源文件,二是依赖的三方库里的资源文件。产出为未经签名的.apk文件。
- 分别由Jarsigner和zipalign对apk文件进行签名和对齐,生成最终的apk文件。
总结为:编译–>DEX–>打包–>签名和对齐
Android dex分包方案和热补丁原理
[Android dex分包方案和热补丁原理][Android dex 1]
[安卓App热补丁动态修复技术介绍][App]
Android dex文件 & 类加载器DexLoader
- 类加载器简介
对于Android的应用程序,本质上虽然也是用Java开发,并且使用标准的Java编译器编译出Class文件,但最终的APK文件中包含的却是dex类型的文件。dex文件是将所需的所有Class文件重新打包,打包的规则不是简单的压缩,而是完全对Class文件内部的各种函数表、变量表等进行优化,并产生一个新的文件,这就是dex文件。由于dex文件是一种经过优化的Class文件,因此要加载这样特殊的Class文件就需要特殊的类装载器,这就是DexClassLoader,Android SDK中提供的DexClassLoader类就是出于这个目的。
DexClassLoader是一个可以从包含classes.dex实体的.jar或.apk文件中加载classes的类加载器。可以用于实现dex的动态加载、代码热更新等等。
DexClassLoader和PathClassLoader的区别
- DexClassLoader:能够加载未安装的jar/apk/dex(可加载外部dex文件,如SD卡中)
- PathClassLoader:Android 系统类&应用类的加载器,只能加载系统中已经安装过的apk(/data/data/包名目录下apk)
- 加载原理
Android的ClassLoader体系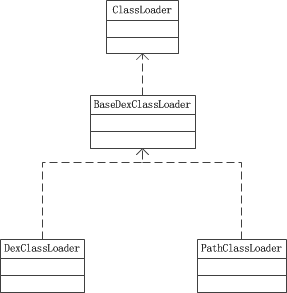
由上图可以看出,在叶子节点上,我们能使用到的是DexClassLoader和PathClassLoader,两个叶子节点的类都继承BaseDexClassLoader中,而具体的类加载逻辑也在此类中:
// BaseDexClassLoader.java
1 |
|
由上述函数可知,当我们需要加载一个class时,实际是从pathList(DexPathList)中去查找。pathList是一个存储dex文件(每个dex文件实际上是一个DexFile对象)的数组(Element数组,Element是一个内部类),然后依次去加载所需要的class文件,直到找到为止。
dex分包方案
- 分包原因
当一个app的功能越来越复杂,代码量越来越多,也许有一天便会突然遇到下列现象:
- 生成的apk在2.3以前的机器无法安装,提示INSTALL_FAILED_DEXOPT
Android2.3及以前版本用来执行dexopt(用于优化dex文件)的内存只分配了5M - 方法数量过多,编译时出错,提示:Conversion to Dalvik format failed:Unable to execute dex: method ID not in [0, 0xffff]: 65536
一个dex文件最多只支持65536个方法
- 分包原理
将编译好的class文件拆分打包成2个dex,在运行时再动态加载第二个dex文件中。(绕过dex方法数量的限制以及安装时的检查)
此时,除了第一个dex文件(一个apk唯一包含一个dex文件),其他dex文件都以资源的方式存放在安装包中,并在Application的onCreate()回调中被注意到系统的ClassLoader中。 - 分包流程
- 编译时分包
(1)将 $ {classes}(该文件夹下都是要打包到第一个dex的文件)打包生成第一个dex。
(2)将 $ {secclasses}中的文件打包生成第二个dex,并将其打包到资资源文件中 - 将dex分包(第二个dex)注入ClassLoader
根据DexClassLoader加载原理:遍历一个存储dex文件的数组,然后依次去加载所需要的class文件,直到找到为止。知注入的解决方案:假如我们将第二个dex文件放入这个数组中,那么在加载第二个dex包中的类时,应该可以直接找到。
在我们自定义的BaseApplication的onCreate中,我们执行注入操作:
1 | public String inject(String libPath) { |
- 参数libPath是第二个dex包的文件信息(包含完整路径,我们当初将其打包到了assets目录下),然后将其使用DexClassLoader来加载。
- 通过反射获取PathClassLoader中的DexPathList中的Element数组(已加载了第一个dex包,由系统加载),以及DexClassLoader中的DexPathList中的Element数组(刚将第二个dex包加载进去)
- 将两个Element数组合并之后,再将其赋值给PathClassLoader的Element数组
通常情况下,dexElements数组中只会有一个元素,就是apk安装包中的classes.dex
而我们则可以通过反射,强行的将一个外部的dex文件添加到此dexElements中,这就是dex的分包原理了。
现在试着启动app,并在TestUrlActivity(在第一个dex包中)中去启动SecondActivity(在第二个dex包中),启动成功。这种方案是可行。
注意点:
- 由于第二个dex包是在Application的onCreate中动态注入的,如果dex包过大,会使app的启动速度变慢,因此,在dex分包过程中一定要注意,第二个dex包不宜过大。
- 由于上述第一点的限制,假如我们的app越来越臃肿和庞大,往往会采取dex分包方案和插件化方案配合使用,将一些非核心独立功能做成插件加载,核心功能再分包加载。
为什么使用DexClassLoader加载第二个包而不用PathClassLoader?
因为PathClassLoader只能加载已安装到系统中(即/data/app目录下)的apk文件。第二个包位于资源文件中dex文件,因此只能用DexClassLoader加载。
源码可参考Google MultiDex方案的实现。
热补丁
- 适用场景
当一个App发布之后,突然发现了一个严重bug需要进行紧急修复,这时候公司各方就会忙得焦头烂额:重新打包App、测试、向各个应用市场和渠道换包、提示用户升级、用户下载、覆盖安装。有时候仅仅是为了修改了一行代码,也要付出巨大的成本进行换包和重新发布。
这时候就提出一个问题:有没有办法以补丁的方式动态修复紧急Bug,不再需要重新发布App,不再需要用户重新下载,覆盖安装?
空间Android独立版5.2发布后,收到用户反馈,结合版无法跳转到独立版的访客界面,每天都较大的反馈。在以前只能紧急换包,重新发布。成本非常高,也影响用户的口碑。最终决定使用热补丁动态修复技术,向用户下发Patch,在用户无感知的情况下,修复了外网问题,取得非常好的效果。 - 实现原理
该方案基于的是android dex分包方案的。原理可概括为:
App的一个ClassLoader可以包含多个dex文件,每个dex文件是一个Element,多个dex文件排列成一个有序的数组dexElements,当找类的时候,会按顺序遍历dex文件,然后从当前遍历的dex文件中找类,如果找类则返回,如果找不到从下一个dex文件继续查找。
理论上,Dex分包方案中是没有重复类的,因此,如果在不同的dex中有重复的类存在,那么会优先选择排在前面的dex文件的类,如下图: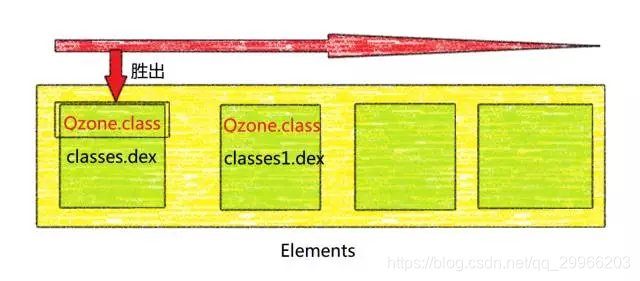
在此基础上,我们构想了热补丁的方案,把有问题的类打包到一个dex(patch.dex)中去,然后把这个dex补丁包插入到Elements的最前面,这样出现bug的类就会被覆盖。如下图: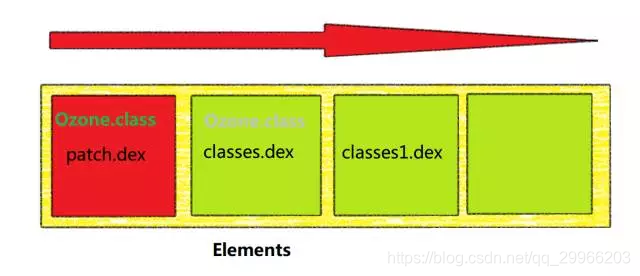
- 实现方案
- 把需修复、含Bug的类 独立打包到1个Dex文件中(记为:patch.dex)
- 将该 Dex文件 插入到ClassLoader中集合 dexElements的最前面

Android 插件化
[H3c —— Android插件化开发][H3c _ Android]
- 简介
所谓插件化,就是让我们的应用不必再像原来一样把所有的内容都放在一个apk中,可以把一些功能和逻辑单独抽出来放在插件apk中,然后主apk做到[按需调用],这样的好处是一来可以减少主apk的体积,让应用更轻便,二来可以做到热插拔(将功能需要的时候插上去,废弃的时候拔下来),更加动态化。
插件化可以解决如下问题:
- 应用体积越来越大,需要拆分apk完成模块化与热部署——减小主包大小
- 应用频繁更新,用户黏性降低——不发版上新功能
- 需求不确定时,添加新功能——允许动态添加新功能,一旦不适用或发生问题,可以进行动态替换(不需要紧急发布补丁或进行升级)
- 主应用用户量较大,同系新应用需要导流,传统特性只能引导用户下载安装——bug修复工具
- 需解决的问题 & 解决方案
插件化核心问题 —— Android动态加载
即动态调用外部的 dex文件,极端的情况下,Android APK自身带有的Dex文件只是一个程序的入口(或者说空壳),所有的功能都通过从服务器下载最新的Dex文件完成。
通过ClassLoader加载,然后通过代理模式让Activity等组件具有生命周期实现真正的功能,并且解决了资源访问问题。是解决插件化的基本问题。
(一)类的加载
- DexClassLoader:要想实现加载外部dex文件(即插件)来实现热部署,那么必然要把其中的class文件加载到内存中。其中涉及到两种ClassLoader:DexClassLoader和PathClassLoader。而DexClassLoader可以加载外部的jar,dex等文件,正是我们需要的。
- 反射:因为插件apk与宿主apk不在一个apk内,那么一些类的访问必然要通过反射进行获取。
(1)创建插件的工程PluginAUtils,并生成PluginAUtils.apk
(2)创建主工程PluginA,在app/src/main/目录下创建asserts文件夹,把刚刚编译好的pluginA.apk放到里面。创建一个AssertsDexLoader.java用来动态加载PluginAUtils工程。
AssertsDexLoader逻辑为拷贝asserts里的apk文件到外置SD卡上某位置(减少应用安装体积),再把ClassLoader,拷贝的目录及文件三个参数传递给installBundleDexs()即可动态加载其方法至内存。
1 | private static List<DexClassLoader> bundleDexClassLoaderList = new ArrayList<DexClassLoader>(); |
使用DexClassLoader代替PathClassLoader除了可以解决Dex加载与系统版本密切问题之外,还可以将第三方apk复制到外置SD卡上减少应用安装后的体积。
(3)在任何需要的地方通过反射调用即可
1 | // class 获取方式 |
(二)生命周期的管理
- 代理模式插件化实现的过程主要靠欺上瞒下,坑蒙拐骗来实现。想想虽然加载进来了Activity等组件,但也仅仅是最为一个对象而存在,并没有在AndroidManifest中注册,没有生命周期的回调,并不能实现我们想要的效果。因此无论是dynamic_load_apk通过代理activity来操控插件activity的方式,还是DroidPlugin通过hook activity启动过程来启动插件activity的方式,都是对代理模式的应用。
(1)宿主代理Activity模式(静态代理模式)
宿主代理无需在宿主中注册Activity,所有跳转均由一个傀儡Activity完成,这样的好处是无需过多的改变宿主即可完成插件开发,但是插件Activity并不享有系统提供的生命周期,其所有生命周期必须由宿主通过反射的方式传递。 - 在PluginA工程中创建BaseActivity.java,关键代码如下:
1 | public class BaseActivity extends Activity { |
- 在PluginA工程中创建AActivity.java和BActivity.java。让AActivity可以点击跳转到BActivity即可。
- 重新编译PluginA,将Apk替换到宿主中。
- 在宿主工程中创建ProxyActivity.java并在AndroidManifest文件中注册。关键代码:
1 | public class ProxyActivity extends Activity { |
跳转
1 | Intent intent = new Intent(MainActivity.this, ProxyActivity.class); |
(2)宿主动态创建Activity模式(动态代理模式)
Activity有着自己的生命周期,但是必须提前在宿主AndroidManifest文件中注册。
(三)资源的加载
要想获得资源文件必须得到一个Resource对象,想要获得插件的资源文件,必须得到一个插件的Resource对象,好在android.content.res.AssetManager.java中包含一个私有方法addAssetPath。只需要将apk的路径作为参数传入,就可以获得对应的AssetsManager对象,从而创建一个Resources对象,然后就可以从Resource对象中访问apk中的资源了。
1 | // 引入插件的AssetManager |
宿主中跳转到ProxyActivity,根据传入的参数反射创建一个插件的Activity,把插件的Resource注入到自己中,并把自己注入到插件Activity中实现生命周期的同步。
Android MVP模式
- MVC模式 & 缺点
MVC,全称Model-View-Controller,即模型-视图-控制器。 具体如下:
- View:对应于布局文件
- Model:业务逻辑和实体模型
- Controllor:对应于Activity
缺点
MVC模式下实际上就是Activty与Model之间交互,View完全独立出来了。
View对应于布局文件,其实能做的事情特别少,实际上关于该布局文件中的数据绑定的操作,事件处理的代码都在Activity中,造成了Activity既像View又像Controller,使得Activity变得臃肿。
2. MVP模式 & 优点
MVP,全称 Model-View-Presenter,即模型-视图-层现器。具体如下:
- View 对应于Activity,负责View的绘制以及与用户交互
- Model 依然是业务逻辑和实体模型
- Presenter 负责完成View于Model间的交互
优点
MVP模式通过Presenter实现数据和视图之间的交互,简化了Activity的职责。同时即避免了View和Model的直接联系,又通过Presenter实现两者之间的沟通。
MVP模式减少了Activity的职责,简化了Activity中的代码,将复杂的逻辑代码提取到了Presenter中进行处理,模块职责划分明显,层次清晰。与之对应的好处就是,耦合度更低,更方便的进行测试。
- MVP & MVC 区别
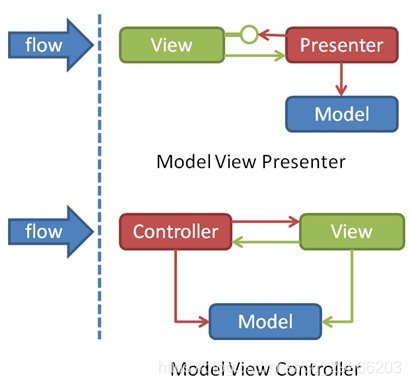
MVC中是允许Model和View进行交互的,而MVP中很明显,Model与View之间的交互由Presenter完成。还有一点就是Presenter与View之间的交互是通过接口的。 - MVP模式 典例 —— 登录案例
结构图
1.Model层
在本例中,M0del层负责对从登录页面获取地帐号密码进行验证(一般需要请求服务器进行验证,本例直接模拟这一过程)。 从上图的包结构图中可以看出,Model层包含内容:
①实体类bean
②接口,表示Model层所要执行的业务逻辑
③接口实现类,具体实现业务逻辑,包含的一些主要方法
下面以代码的形式一一展开。
①实体类bean
1 | public class User { |
封装了用户名、密码,方便数据传递。
②接口
1 | public interface LoginModel { |
其中OnLoginFinishedListener 是presenter层的接口,方便实现回调presenter,通知presenter业务逻辑的返回结果,具体在presenter层介绍。
③接口实现类
1 | public class LoginModelImpl implements LoginModel { |
实现Model层逻辑:延时模拟登陆(2s),如果用户名或者密码为空则登陆失败,否则登陆成功。
2.View层
视图:将Modle层请求的数据呈现给用户。一般的视图都只是包含用户界面(UI),而不包含界面逻辑,界面逻辑由Presenter来实现。
从上图的包结构图中可以看出,View包含内容:
①接口,上面我们说过Presenter与View交互是通过接口。其中接口中方法的定义是根据Activity用户交互需要展示的控件确定的。
②接口实现类,将上述定义的接口中的方法在Activity中对应实现具体操作。
下面以代码的形式一一展开。
①接口
1 | public interface LoginView { |
上述5个方法都是presenter根据model层返回结果需要view执行的对应的操作。
②接口实现类
即对应的登录的Activity,需要实现LoginView接口。
1 | public class LoginActivity extends AppCompatActivity implements LoginView, View.OnClickListener { |
View层实现Presenter层需要调用的控件操作,方便Presenter层根据Model层返回的结果进行操作View层进行对应的显示。
3.Presenter层
Presenter是用作Model和View之间交互的桥梁。 从上图的包结构图中可以看出,Presenter包含内容:
①接口,包含Presenter需要进行Model和View之间交互逻辑的接口,以及上面提到的Model层数据请求完成后回调的接口。
②接口实现类,即实现具体的Presenter类逻辑。
下面以代码的形式一一展开。
①接口
1 | public interface OnLoginFinishedListener { |
当Model层得到请求的结果,需要回调Presenter层,让Presenter层调用View层的接口方法。
1 | public interface LoginPresenter { |
登陆的Presenter 的接口,实现类为LoginPresenterImpl,完成登陆的验证,以及销毁当前view。
②接口实现类
1 | public class LoginPresenterImpl implements LoginPresenter, OnLoginFinishedListener { |
由于presenter完成二者的交互,那么肯定需要二者的实现类(通过传入参数,或者new)。
presenter里面有个OnLoginFinishedListener, 其在Presenter层实现,给Model层回调,更改View层的状态, 确保 Model层不直接操作View层。
核心流程总结
View与Model并不直接交互,而是使用Presenter作为View与Model之间的桥梁。其中Presenter中同时持有View层的Interface的引用以及Model层的引用,而View层持有Presenter层引用。当View层某个界面需要展示某些数据的时候,首先会调用Presenter层的引用,然后Presenter层会调用Model层请求数据,当Model层数据加载成功之后会调用Presenter层的回调方法通知Presenter层数据加载情况,最后Presenter层再调用View层的接口将加载后的数据展示给用户。本例模式:
一般模式: